







本篇为hadoop3.x版本的集群部署过程,涵盖从环境搭建、hadoop集群NameNode、DataNone、Secondary NameNode、ResourceManager、JobHistory、HDFS、Yarn的组件服务配置等步骤,其中搭建过程参考尚硅谷的部署资料。
环境准备:Linux服务器3台,系统版本:centos7.5,IP:192.168.216.100、192.168.216.101、192.168.216.102。JDK版本:jdk1.8.0_212Hadoop版本:3.1.3。
1.1.集群环境配置
1、关闭防火墙,避免后面因防火墙问题导致端口范围不通。
systemctl stop firewalld
systemctl disable firewalld

2、创建个用户,赋予sudo权限,后期使用该账号进行安装
useradd newbie
passwd newbie
vim /etc/sudoers
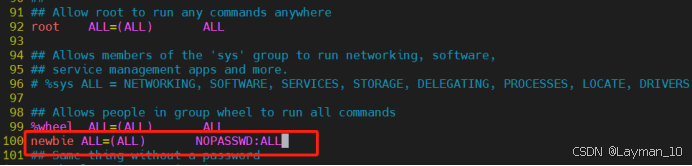
// newbie这一行不要直接放到root行下面,因为所有用户都属于wheel组,先配置了newbie具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以newbie要放到%wheel这行下面。
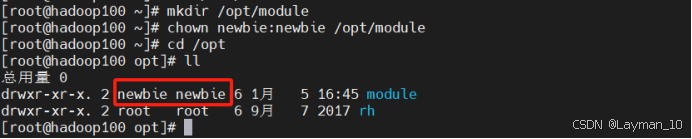
3、创建安装目录,并修改目前的所属主和所属组,后面jdk和hadoop都安装在此目录下
mkdir /opt/module
chown newbie:newbie /opt/module
4、卸载虚拟机自带的JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
# rpm -qa:查询所安装的所有rpm软件包
# grep -i:忽略大小写
# xargs -n1:表示每次只传递一个参数
# rpm -e --nodeps:强制卸载软件
5、克隆虚拟机,将已完成上述配置的虚拟机关键,克隆两台
“虚拟机—>管理—>克隆”
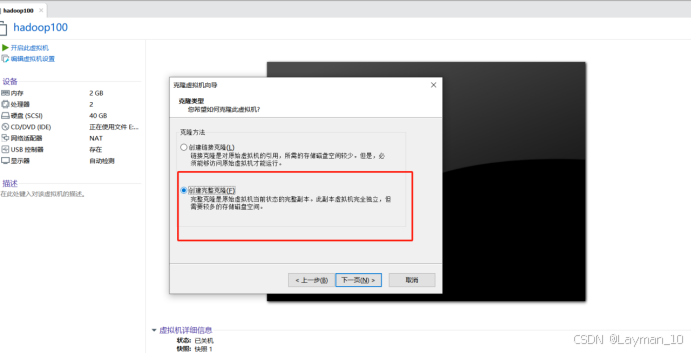
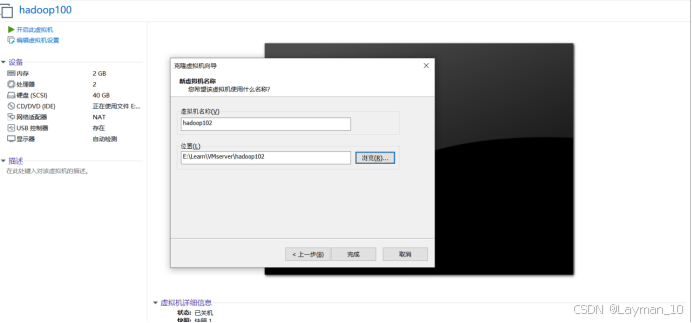
6、分别打开克隆的两台服务,更改IP,这里是克隆100那台主机,所以其他更改为.101、102。
1.2.环境准备在100上安装JDK
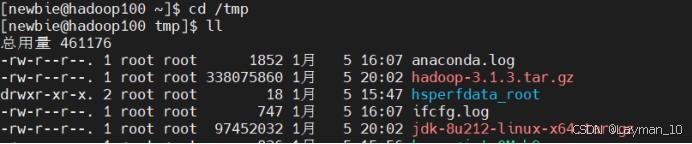
1、上传安装包到/tmp目录
2、解压到/opt/module,并查看是否解压成功
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/

3、配置JDK环境变量
新建/etc/profile.d/my_env.sh文件(/etc/profile和/etc/profile.d/两个文件都是设置环境变量文件的,/etc/profile.d/比/etc/profile好维护,不想要什么变量直接删除/etc/profile.d/下对应的shell脚本即可,不用像/etc/profile改动文件。)
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
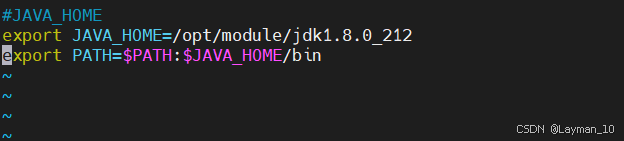
记得每次配置环境变量后要刷新
source /etc/profile
4、测试JDK是否安装成功
java -version

1.3.环境准备在100上安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
可以下载对应的版本
1、然后上传到Linux上(/tmp)
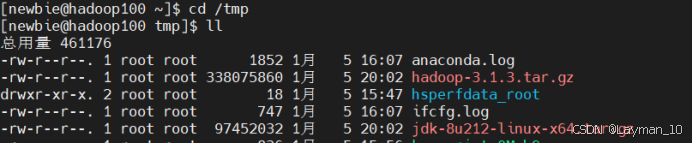
2、解压到/opt/module,并查看是否解压成功,更改hadoop-3.1.3为hadoop(改不改都行),这里因为习惯和便于直观,就更改了
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/

mv hadoop-3.1.3/ hadoop/

3、配置hadoop环境变量
将hadoop的路径加入到环境变量,并使其生效
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
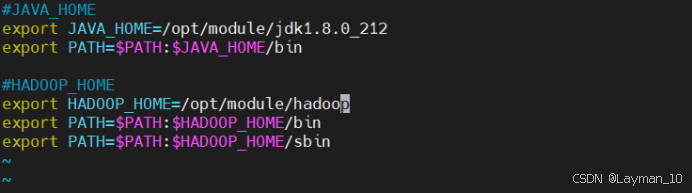
source /etc/profile
4、测试hadoop是否安装成功,并查看hadoop目录
hadoop version

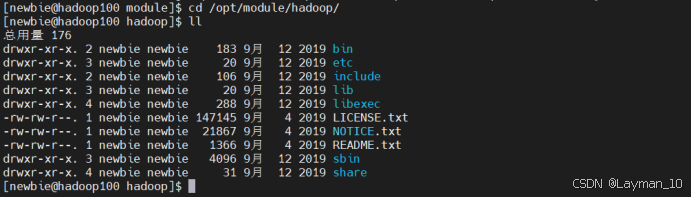
5、ha
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









