







CV项目课程笔记_malaedu
花朵分类_02_模型评估
01 模型评价指标
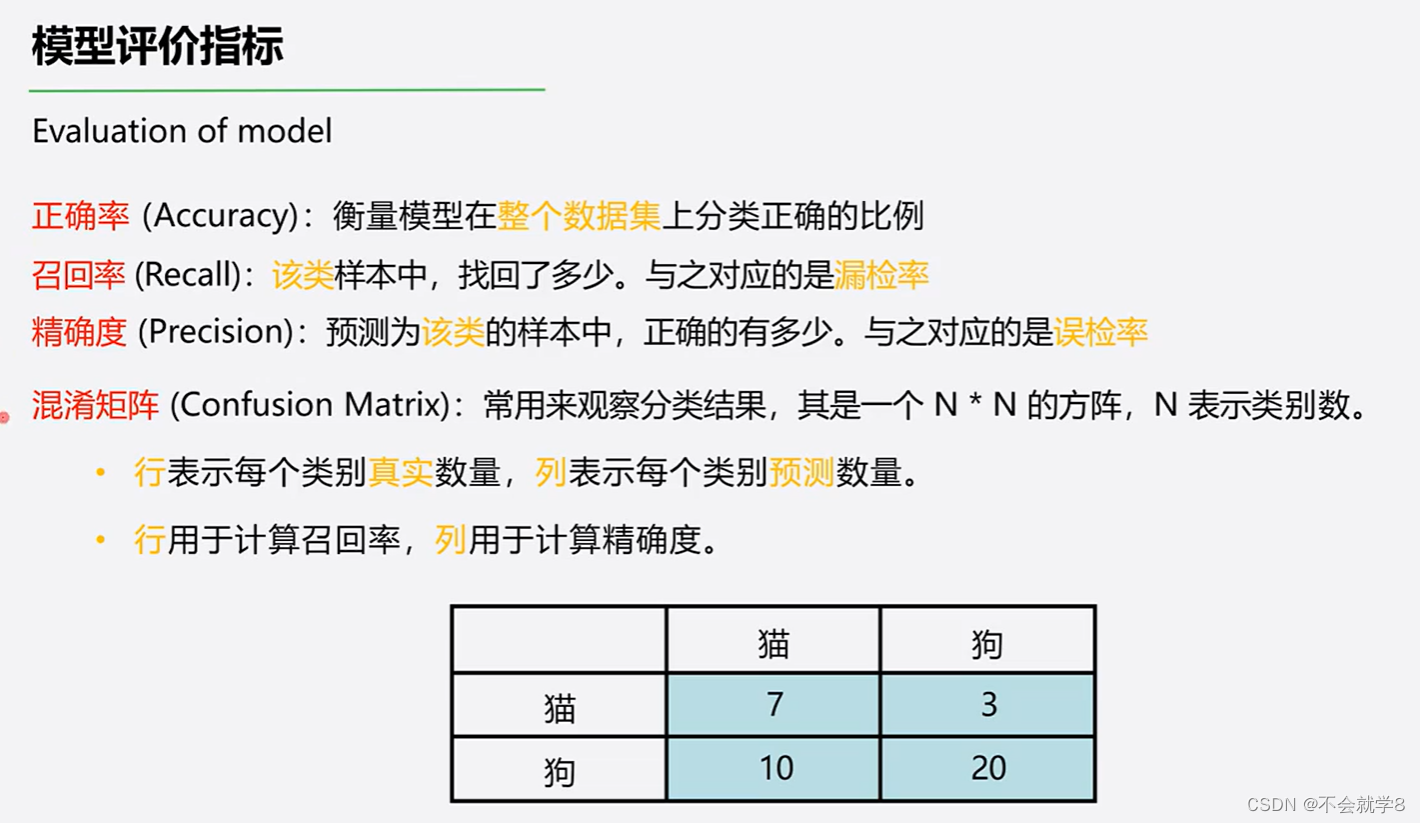
行:真实样本数 计算召回率Recall(检出率)
列:预测样本数 计算精确度Precision

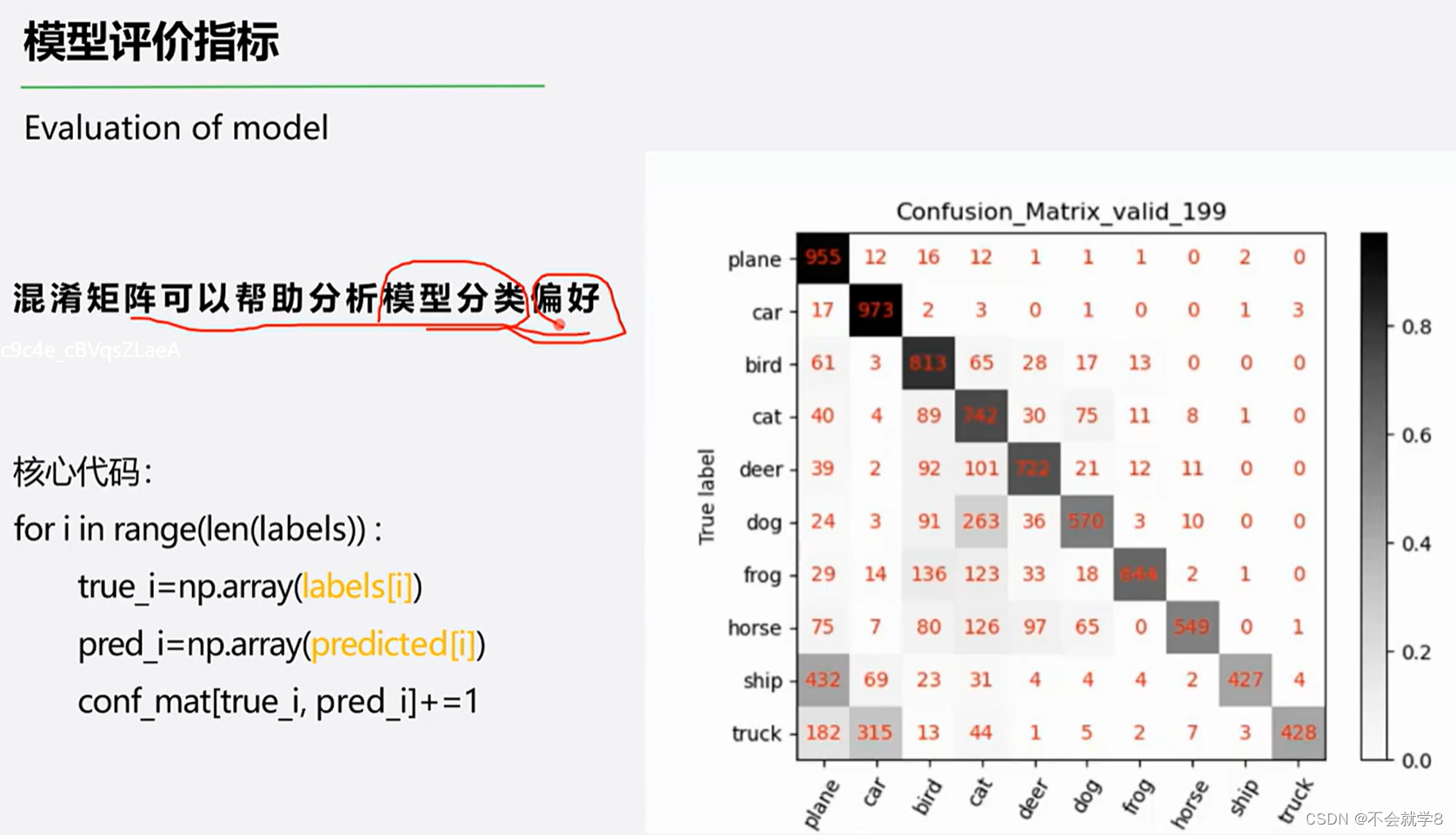
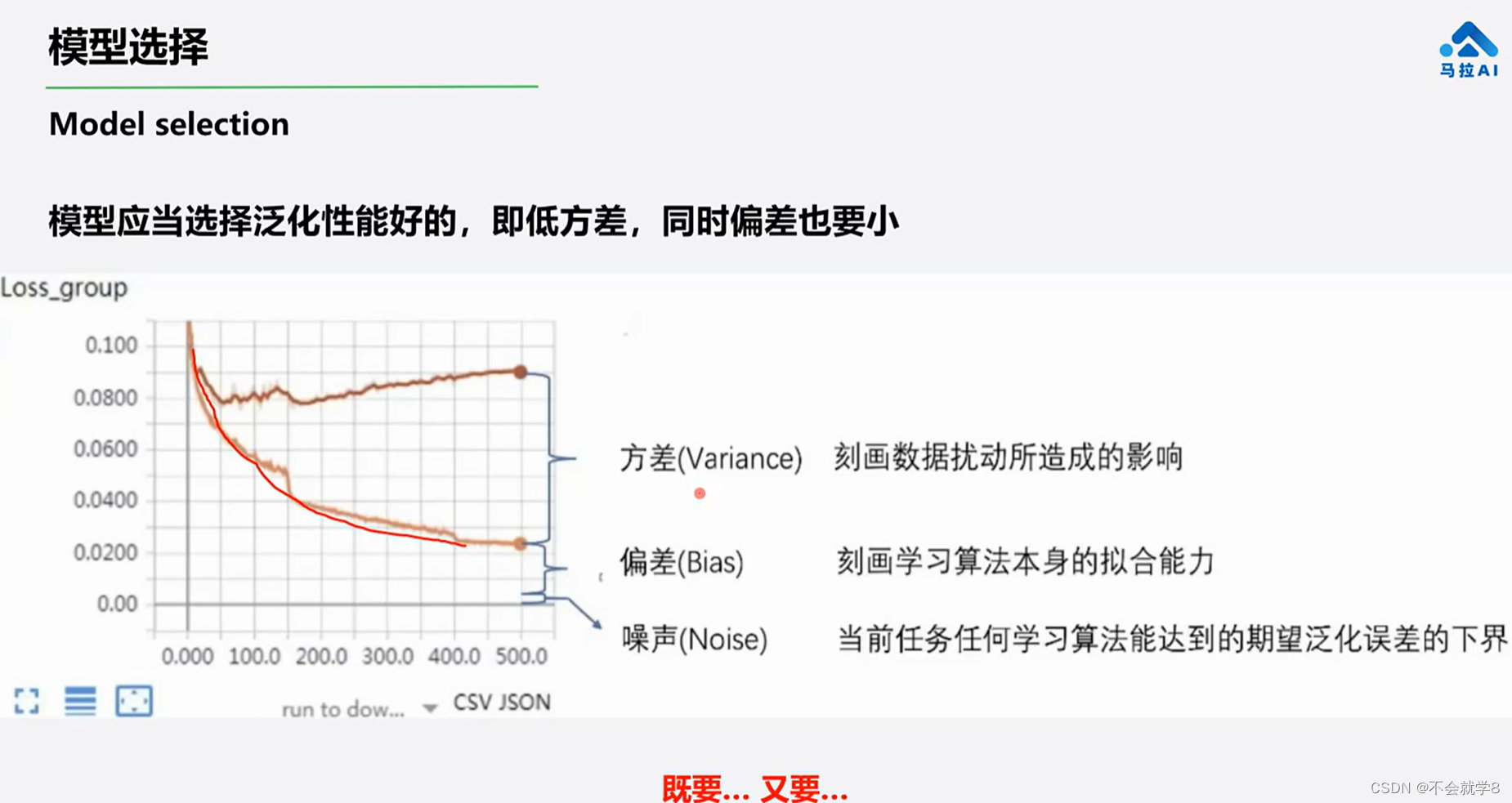
02 模型选择

验证集loss下降曲线(上面那条)
训练集loss下降曲线(下面那条)
**一旦出现验证集loss慢慢上升的情况要把训练停掉,防止方差过大。

03 Coding(文后附注释代码)
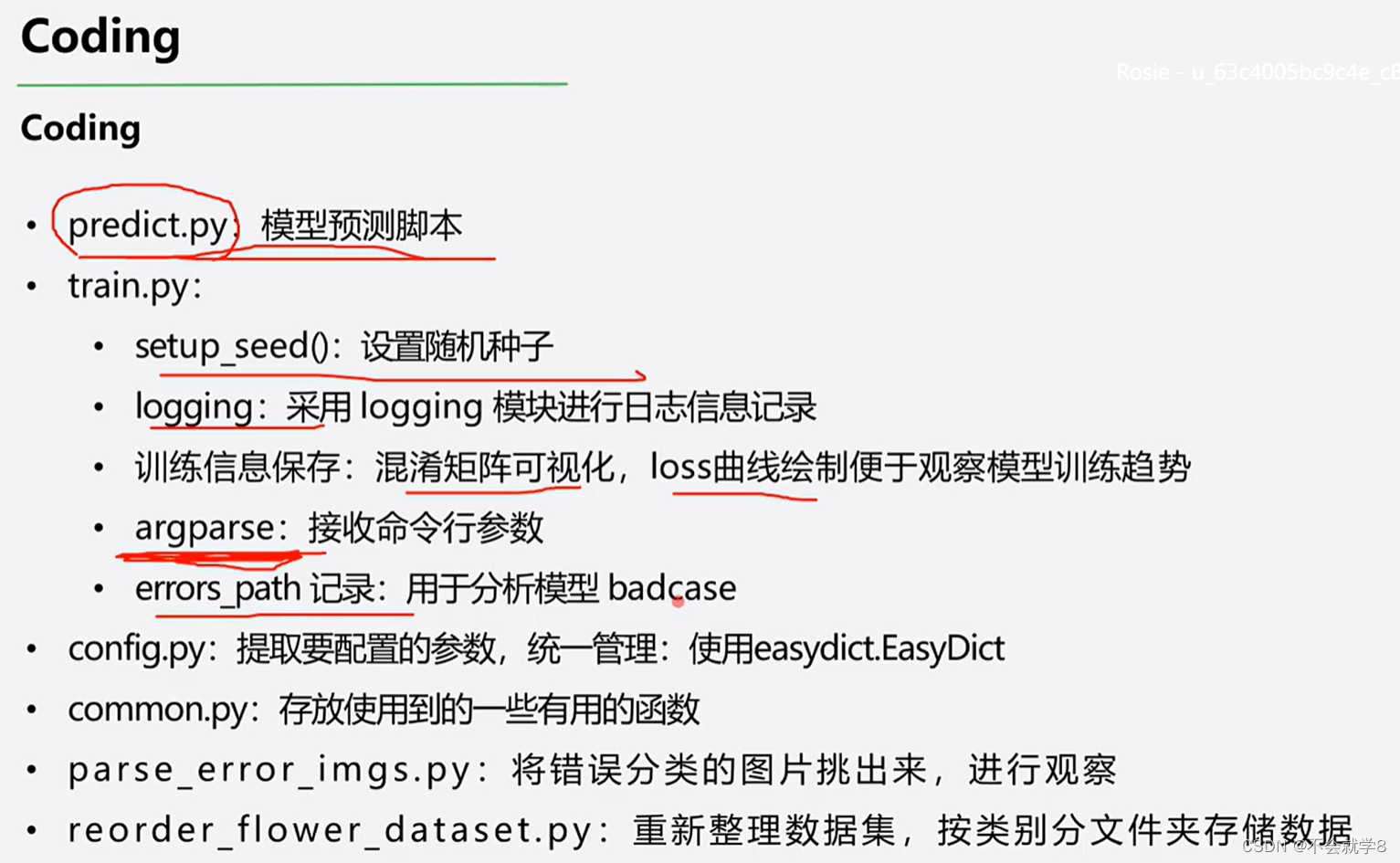
predict.py 通过训练好的模型预测图片类别
**小tips
vscode快捷输入sma ,得到if __name__ == “__main__”:
model.eval() ##重要!!要把模式转换成evaluation形式
#predict.py
#通过训练好的模型预测图片
from torchvision import models, transforms
from torch import nn
import torch
from easydict import EasyDict
from PIL import Image
if __name__ == "__main__":
# config
cfg = EasyDict()#EasyDict 第三方的数据结构来管理配置文件,使得可以通过访问类属性的方式访问字典
cfg.num_cls = 102 #102种花
cfg.transforms = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#归一化。减去均值,除以方差。
])
# 01 初始化模型(实例化)
model = models.resnet18() #参数随机初始化
in_features = model.fc.in_features
fc = nn.Linear(in_features=in_features, out_features=cfg.num_cls)
model.fc = fc
# 02 载入训练好的权重,用torch.load()方法
model_weights = r"model.pth的相对路径"
checkpoint = torch.load(model_weights)
model.load_state_dict(checkpoint["model"])
#对应train.py里的保存模型里的保存模型部分
"""checkpoint = {
"model": model.state_dict(),#保存模型权重和名称
"epoch": epoch,
#另一种可以存成"model": model
}"""
# 03 读图-预处理
#遍历图像路径
data_dir = r"验证集路径"
for img_name in os.listdir(data_dir):
img_path = os.path.join(data_dir, img_name)
img0 = Image.open(img_path).convert("RGB")#原始图像img0
img: torch.Tensor = cfg.transforms(img0) # CHW
#加上: torch.Tensor,指定类型,可以在后面直接加.联想方法
#为了变BCHW,用.unsqueeze()方法 batch为1,1CHW
img = img.unsqueeze(dim=0)#第0维度之前加维度
# 04 推理
#把模型转到GPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device=device) #把模型权重放到cuda上
model.eval()##重要!!要把模式转换成evaluation形式
img = img.to(device=device) #把img数据放到cuda上
with torch.no_grad(): ##
output = model(img) # [1,102]
#1是第二个维度
#输出两个值:最大值是多少,最大值对应的索引。我们想要的是:索引,值是多少不要,所以要写下划线
_, pred_label = torch.max(output, 1)#最大值对应的索引就是类别数
# 05 展示
print(f"path: {img_path}, pred label: {int(pred_label)}")#强转成int型
config.py 参数配置
# config.py 一些可变的参数配置
import time
from easydict import EasyDict
from torchvision import transforms
cfg = EasyDict()
cfg.train_dir = r"训练集路径"
cfg.valid_dir = r"验证集路径"
# 超参数相关
cfg.batch_size = 64
cfg.num_workers = 2
cfg.num_cls = 102
# 优化器相关
cfg.max_epoch = 40
cfg.lr0 = 0.01
cfg.momentum = 0.9
cfg.weight_decay = 1e-4
cfg.milestones = [25, 35]
cfg.decay_factor = 0.1
# log相关
cfg.log_interval = 10 # iter
time_str = time.strftime("%Y%m%d-%H%M")
cfg.output_dir = f"ouputs/{time_str}"
cfg.log_path = cfg.output_dir + "/log.txt"
# 数据相关
norm_mean, norm_std = [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]
cfg.train_transform = transforms.Compose([
transforms.Resize(256), # (256, 256)区别 256:短边保持256 1920x1080 [1080->256 1920*(1080/256)]
transforms.RandomCrop(224), # 模型最终的输入大小[224, 224]
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(), # 1)0-225 -> 0-1 float 2)HWC -> CHW -> BCHW
transforms.Normalize(norm_mean, norm_std) # 减去均值 除以方差
])
cfg.valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(), # 0-225 -> 0-1 float HWC-> CHW BCHW
transforms.Normalize(norm_mean, norm_std) # 减去均值 除以方差
])
通过config.py文件进行一些参数的配置,train.py直接引入config.py这个文件,把原有的参数配置可以修改成cfg.的形式调用。
from configs.config import cfg
(根据自己文件路径进行调整) 如图所示进行替换

从common.py里 添加随机种子
# common.py
import os
import logging
from matplotlib import pyplot as plt
import random
import numpy as np
import torch
# 随机种子的设置
def setup_seed(seed=42):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True # 为True时, 卷积算法固定
torch.backends.cudnn.benchmark = True # 网络结构变化不大时使训练加速,训练前为每个卷积层搜索最适合算法
# 定制化logging, mode='w'可写的
def setup_logger(log_path, mode='w'):
os.makedirs(os.path.dirname(log_path), exist_ok=True)
# logging模块
"""作用:设置等级大小,格式化打印内容,保存log到文件,以流的形式输出到控制台"""
logger = logging.getLogger()
# 可以是warning error
logger.setLevel(level=logging.INFO)
# 格式化打印内容
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# 配置文件Handler,保存log到文件
file_handler = logging.FileHandler(log_path, mode)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
# 配置屏幕Handler,以流的形式输出到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(formatter)
# 添加handler
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
def show_confMat(confusion_mat, classes, set_name, out_dir, epoch=999, verbose=False, figsize=None, perc=False):
"""绘制混淆矩阵并保存图片
Args:
confusion_mat (np.ndarray): 混淆矩阵二维数组
classes (list): 类别名称
set_name (str): 数据集名称 train or valid or test
out_dir (str): 图片保存的文件夹
epoch (int, optional): 第几个epoch. Defaults to 999.
verbose (bool, optional): 是否打印详细信息. Defaults to False.
figsize (optional): 绘制的图像大小. Defaults to None.
perc (bool, optional): 是否采用百分比,图像分割时用,因分类数目过大. Defaults to False.
"""
cls_num = len(classes)
# 归一化
confusion_mat_tmp = confusion_mat.copy()
for i in range(len(classes)):
confusion_mat_tmp[i, :] = confusion_mat[i, :] / confusion_mat[i, :].sum() # 按召回率
# 设置图像大小
if cls_num < 10:
figsize = 6
elif cls_num >= 100:
figsize = 30
else:
figsize = np.linspace(6, 30, 91)[cls_num-10]
plt.figure(figsize=(int(figsize), int(figsize*1.3)))
# 获取颜色
cmap = plt.cm.get_cmap('Greys') #灰度颜色 更多颜色: http://matplotlib.org/examples/color/colormaps_reference.html
plt.imshow(confusion_mat_tmp, cmap=cmap)
plt.colorbar(fraction=0.03)
# 设置文字
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, list(classes), rotation=60)
plt.yticks(xlocations, list(classes))
plt.xlabel('Predict label')
plt.ylabel('True label')
plt.title("Confusion_Matrix_{}_{}".format(set_name, epoch)) # 数据集, epoch
# 打印每个方格的数字
if perc:
cls_per_nums = confusion_mat.sum(axis=0)
conf_mat_per = confusion_mat / cls_per_nums
for i in range(confusion_mat_tmp.shape[0]):
for j in range(confusion_mat_tmp.shape[1]):
plt.text(x=j, y=i, s="{:.0%}".format(conf_mat_per[i, j]), va='center', ha='center', color='red',
fontsize=10)
else:
for i in range(confusion_mat_tmp.shape[0]):
for j in range(confusion_mat_tmp.shape[1]):
plt.text(x=j, y=i, s=int(confusion_mat[i, j]), va='center', ha='center', color='red', fontsize=10)
# 保存
plt.savefig(os.path.join(out_dir, "Confusion_Matrix_{}.png".format(set_name)))
plt.close()
if verbose:
print(set_name)
for i in range(cls_num):
print('class:{:<10}, total num:{:<6}, correct num:{:<5} Recall: {:.2%} Precision: {:.2%}'.format(
classes[i], np.sum(confusion_mat[i, :]), confusion_mat[i, i],
confusion_mat[i, i] / (1e-9 + np.sum(confusion_mat[i, :])), # 防止分母为0,所以加上一个很小很小的数字1e-9
confusion_mat[i, i] / (1e-9 + np.sum(confusion_mat[:, i]))))
def plot_line(train_x, train_y, valid_x, valid_y, mode, out_dir):
"""绘制训练和验证集的loss曲线/acc曲线
Args:
train_x (list): x轴
train_y (list): y轴
valid_x (list): x轴
valid_y (list): y轴
mode (str): 'loss' or 'acc'
out_dir (str): 图片保存的文件夹
"""
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.ylabel(str(mode))
plt.xlabel('Epoch')
location = 'upper right' if mode == 'loss' else 'upper left'
plt.legend(loc=location)
plt.title(str(mode))
plt.savefig(os.path.join(out_dir, mode + '.png'))
plt.close()
seed is all you need
model_trainer.py里print改成logger.info

添加参数
# model_trainer.py
import torch
import numpy as np
from collections import Counter
class ModelTrainer:
@staticmethod
def train_one_epoch(data_loader, model, loss_f, optimizer, scheduler, epoch_idx, device, log_interval, max_epoch, logger):
model.train() ## model变为可训练的状态
num_cls = model.fc.out_features
conf_mat = np.zeros((num_cls, num_cls))
loss_sigma = []
loss_mean = 0
acc_avg = 0
path_error = []
#不断循环data_loader取数据
for i, data in enumerate(data_loader):
inputs, labels, path_imgs = data
# inputs, labels = data # batch的类型 4维BCHW
inputs, labels = inputs.to(device), labels.to(device) #移动到GPU上
# forward & backward
outputs = model(inputs)
loss = loss_f(outputs.cpu(), labels.cpu())
optimizer.zero_grad() ###***优化器梯度清零***
loss.backward() #反向传播
optimizer.step() #参数更新
# 统计loss
loss_sigma.append(loss.item())
loss_mean = np.mean(loss_sigma) #loss均值
# 统计混淆矩阵
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)): # per sample
cate_i = labels[j].cpu().numpy()
pred_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pred_i] += 1.
if cate_i != pred_i:
path_error.append((cate_i, pred_i, path_imgs[j]))# FlowerDataset类里要return输出img_path,这里才能用
acc_avg = conf_mat.trace() / conf_mat.sum()# 预测正确(对角线)的除以所有的样本数
# 每10个iteration 打印一次训练信息
if i % log_interval == log_interval - 1:
logger.info("Training: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".
format(epoch_idx + 1, max_epoch, i + 1, len(data_loader), loss_mean, acc_avg))
# print("epoch:{} sampler: {}".format(epoch_idx, Counter(label_list)))
scheduler.step()
return loss_mean, acc_avg, conf_mat, path_error
@staticmethod
def valid_one_epoch(data_loader, model, loss_f, device):
model.eval()
num_cls = model.fc.out_features
conf_mat = np.zeros((num_cls, num_cls))
loss_sigma = []
path_error = []
for i, data in enumerate(data_loader):
inputs, labels, path_imgs = data
# inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
#上下文管理器,使得不再计算梯度
with torch.no_grad():
outputs = model(inputs)
# 计算loss
loss = loss_f(outputs.cpu(), labels.cpu())
# 统计混淆矩阵
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)):
cate_i = labels[j].cpu().numpy()
pred_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pred_i] += 1.
if cate_i != pred_i:
path_error.append((cate_i, pred_i, path_imgs[j]))# FlowerDataset类里要return输出img_path,这里才能用
# 统计loss
loss_sigma.append(loss.item())
#avg
acc_avg = conf_mat.trace() / conf_mat.sum()
return np.mean(loss_sigma), acc_avg, conf_mat, path_error
train.py
#train.py
import torch
import os
import time
from torchvision import transforms, models
from datasets.flower_dataset import FlowerDataset
from utils.model_trainer import ModelTrainer
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import transforms, models
from configs.config import cfg
from utils.common import setup_seed, setup_logger, show_confMat, plot_line
import argparse
import shutil
import pickle
parser = argparse.ArgumentParser(description='Training')
parser.add_argument('--lr', default=None, type=float, help='learning rate') # required = True 强制要求该参数
parser.add_argument('--bs', default=None, type=int, help='training batch size')
parser.add_argument('--max_epoch', type=int, default=None, help='number of epoch')
args = parser.parse_args()
# 断言判断: config和args冲突时,优先使用args
cfg.lr0 = args.lr if args.lr else cfg.lr0
cfg.batch_size = args.bs if args.bs else cfg.batch_size
cfg.max_epoch = args.max_epoch if args.max_epoch else cfg.max_epoch
if __name__ == "__main__":
# 设置固定随机种子,便于复现结果
setup_seed(42) # seed is all you need ##42
logger = setup_logger(cfg.log_path, 'w')
# 1. 参数配置
os.makedirs(cfg.output_dir, exist_ok=True)
# 2. 数据相关
# 实例化dataset(train和valid)
train_dataset = FlowerDataset(img_dir=cfg.train_dir, transform=cfg.train_transform)
valid_dataset = FlowerDataset(img_dir=cfg.valid_dir, transform=cfg.valid_transform)
# 组装dataloader。shuffle打乱。num_workers多少个子进程(0和1的区别)
train_loader = DataLoader(train_dataset, cfg.batch_size, shuffle=True, num_workers=cfg.num_workers)
valid_loader = DataLoader(valid_dataset, cfg.batch_size, shuffle=False, num_workers=cfg.num_workers)
# 3. 实例化网络模型
model = models.resnet18(pretrained=True) # imagenet上预训练的 全连接层fc 1000个类别,本项目是102种flowers所以要重定义fc
#原始维度
in_features = model.fc.in_features
#线性层全连接层 改写out_features
fc = nn.Linear(in_features=in_features, out_features=cfg.num_cls)
model.fc = fc
#把模型转到GPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device=device)
# 4. 优化器相关
#loss函数 交叉熵损失
loss_fn = nn.CrossEntropyLoss()
#优化器实例化 SGD:随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=cfg.lr0, momentum=cfg.momentum, weight_decay=cfg.weight_decay)
#学习率的下降策略实例化
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=cfg.milestones, gamma=cfg.decay_factor)
# 打印如下信息
logger.info(
"cfg:\n{}\n loss_f:\n{}\n scheduler:\n{}\n optimizer:\n{}\n model:\n{}".format(
cfg, loss_fn, lr_scheduler, optimizer, model
)
)
#5. for循环loop
logger.info("start train...")
# 初始化 每个字典里包含一个训练集和一个验证集
loss_rec = {"train": [], "valid": []}
acc_rec = {"train": [], "valid": []}
best_acc, best_epoch = 0, 0
t_start = time.time()
for epoch in range(cfg.max_epoch):
# 一次epoch的训练
# 按batch形式取数据
# 前向传播
# 计算Loss
# 反向传播计算梯度
# 更新权重
# 统计Loss 准确率
loss_train, acc_train, conf_mat_train, path_error_train = ModelTrainer.train_one_epoch(
train_loader, model,
loss_f=loss_fn,
optimizer=optimizer,
scheduler=lr_scheduler,
epoch_idx=epoch,
device=device,
log_interval=cfg.log_interval,
max_epoch=cfg.max_epoch,
logger=logger,
)
# 一次epoch验证
# 按batch形式取数据
# 前向传播
# 计算Loss
# 统计Loss 准确率
loss_valid, acc_valid, conf_mat_valid, path_error_valid = ModelTrainer.valid_one_epoch(
valid_loader,
model, loss_fn,
device=device,
)
# 打印训练集和验证集上的指标状态
logger.info("Epoch[{:0>3}/{:0>3}] Train Acc: {:.2%} Valid Acc:{:.2%} Train loss:{:.4f} Valid loss:{:.4f} LR:{}". \
format(epoch + 1, cfg.max_epoch, acc_train, acc_valid, loss_train, loss_valid,
optimizer.param_groups[0]["lr"]))
# 绘制混淆矩阵
classes = list(range(cfg.num_cls))
show_confMat(conf_mat_train, classes, "train", cfg.output_dir, epoch=epoch, verbose=epoch == cfg.max_epoch - 1)
show_confMat(conf_mat_valid, classes, "valid", cfg.output_dir, epoch=epoch, verbose=epoch == cfg.max_epoch - 1)
# 记录训练信息
loss_rec["train"].append(loss_train), loss_rec["valid"].append(loss_valid)
acc_rec["train"].append(acc_train), acc_rec["valid"].append(acc_valid)
# 绘制Loss和acc曲线
plt_x = list(range(1, epoch + 2))
plot_line(plt_x, loss_rec["train"], plt_x, loss_rec["valid"], mode="loss", out_dir=cfg.output_dir)
plot_line(plt_x, acc_rec["train"], plt_x, acc_rec["valid"], mode="acc", out_dir=cfg.output_dir)
#保存模型
checkpoint = {
"model": model.state_dict(),
"epoch": epoch,
#"model": model.state_dict(),保存模型权重和名称
#另一种可以存成"model": model
}
torch.save(checkpoint, f"{cfg.output_dir}/last.pth")
if best_acc < acc_valid:
# 更新 保存验证集上表现最好的模型
best_acc, best_epoch = acc_valid, epoch
shutil.copy(f"{cfg.output_dir}/last.pth", f"{cfg.output_dir}/best.pth")
# 保存错误图片的路径
err_imgs_out = os.path.join(cfg.output_dir, "error_imgs_best.pkl")
error_info = {}
error_info["train"] = path_error_train
error_info["valid"] = path_error_valid
with open(err_imgs_out, 'wb') as f:
pickle.dump(error_info, f)
#训练结束的log提示
t_use = (time.time() - t_start) / 3600 #单位是秒,除以之后保留三位小数点
logger.info(f"Train done, use time {t_use:.3f} hours, best acc: {best_acc:.3f} in :{best_epoch}")
parse_error_imgs.py 文件夹下的图片是预测错误的图片
# 将错误分类的图片挑出来,进行观察
import os
import pickle
import shutil
def load_pickle(path_file):
with open(path_file, "rb") as f:
data = pickle.load(f)
return data
if __name__ == '__main__':
path_pkl = r"error_imgs_best.pkl的路径"
data_root_dir = r"数据集路径"
out_dir = path_pkl[:-4] # 输出文件目录
error_info = load_pickle(path_pkl)
for setname, info in error_info.items(): # [train, valid]
for imgs_data in info:
label, pred, path_img_rel = imgs_data
path_img = os.path.join(data_root_dir, os.path.basename(path_img_rel))
img_dir = os.path.join(out_dir, setname, str(label), str(pred)) # 图片文件夹
os.makedirs(img_dir, exist_ok=True)
shutil.copy(path_img, img_dir) # 复制文件
print("Done")
reorder_flower_dataset.py将flower数据集按类别排放,便于分析
# 将flower数据集按类别排放,便于分析
import os
import shutil
from tqdm import tqdm
if __name__ == '__main__':
root_dir = r"数据集路径"
path_mat = os.path.join(root_dir, "imagelabels.mat")
reorder_dir = os.path.join(root_dir, "reorder")
jpg_dir = os.path.join(root_dir, "jpg")
from scipy.io import loadmat
label_array = loadmat(path_mat)["labels"]
names = os.listdir(jpg_dir)
names = [p for p in names if p.endswith(".jpg")]
for img_name in tqdm(os.listdir(jpg_dir)):
path = os.path.join(jpg_dir, img_name)
if not img_name[6:11].isdigit():
continue
img_id = int(img_name[6:11])
col_id = img_id - 1
cls_id = int(label_array[:, col_id]) - 1 # from 0
out_dir = os.path.join(reorder_dir, str(cls_id))
os.makedirs(out_dir, exist_ok=True)
shutil.copy(path, out_dir) # 复制文件
print("Done")
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









