






XPath详解:http://www.360doc.com/content/15/0301/22/9183209_451827261.shtml
XPath是获取xml中数据的一种方式,其简单语法结构如下(引用自w3c):
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
XML 实例文档
我们将在下面的例子中使用这个 XML 文档。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
1.实例化DocumentBuilderFactory对象,该对象帮助创建DocumentBuilder对象,用于解析。
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();//实例化DocumentBuilderFactory对象
DocumentBuilder bulider = dbf.newDocumentBuilder();
2.用DocumentBuilder对象进行解析
Document doc= bulider.parse(Thread.currentThread().getContextClassLoader().getResourceAsStream("xml文件路径"));
3.实例化Xpath对象
PathFactory factory = XPathFactory.newInstance();//实例化XPathFactory对象,帮助创建XPath对象
XPath xpath = factory.newXPath();
4.获取XML文件的节点,进行操作
XPathExpression compile = xpath.compile("//book");//选取book节点
NodeList nodes = (NodeList)compile.evaluate(doc, XPathConstants.NODESET);//获取book节点的所有节点
xml文件:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
例子:
解析类:
package com.cn.parse;
import java.io.ByteArrayInputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathException;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
public class xmlTojava {
public String xmlTojava(String request){
try {
//使用指定的charset将这个字符串编码为一个字节序列,将结果存储到一个新的字节数组中。
byte[] b = request.getBytes("utf-8");
ByteArrayInputStream sr = new ByteArrayInputStream(b);
//定义一个工厂API,使应用程序能够获得从XML文档生成DOM对象树的解析器。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//指定由该代码生成的解析器将提供对XML名称空间的支持。默认情况下,该值设置为false
factory.setNamespaceAware(false);
//定义从XML文档获取DOM文档实例的API。使用这个类,应用程序程序员可以从XML获取文档
DocumentBuilder builder = factory.newDocumentBuilder();
//文档接口表示整个HTML或XML文档。从概念上讲,它是文档树的根,并提供对文档数据的主要访问
Document document = builder.parse(sr);
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xPath = xPathFactory.newXPath();
//编译XPath表达式以供以后求值
//country/country_name/text() country节点下的country_name节点的值
XPathExpression exception1 = xPath.compile("country/country_name/text()");
XPathExpression exception = xPath.compile("country/provinces/province/province_name/text()");
//在指定的上下文中计算已编译的XPath表达式,并将结果返回为指定的类型。
String countryString = (String)exception1.evaluate(document, XPathConstants.STRING);
String provinceString = (String)exception.evaluate(document,XPathConstants.STRING);
return countryString+"-----"+provinceString;
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
}
main函数:
package com.cn.test;
import com.cn.parse.xmlTojava;
public class test1 {
public static void main(String[] args) {
xmlTojava x = new xmlTojava();
String request=
" <country>"
+" <country_name>中国</country_name>"
+" <provinces>"
+ " <province>"
+ " <province_name>江苏省</province_name>"
+ " <prov_city>南京市</prov_city>"
+ " </province>"
+ " </provinces>"
+ " </country>";
String string = x.xmlTojava(request);
System.out.print(string);
}
}
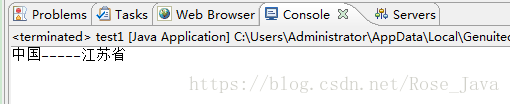
结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









