






之前的实验中,我们会发现使用hadoop时经常出现资源不足等问题。我们可以对hadoop的配置进行优化,以解决这些问题。
hdfs核心参数配置
NameNode内存优化配置
我们可以使用之前编写的脚本xcall.sh,查看进程。
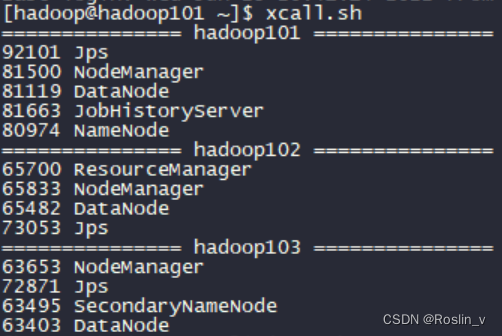
找到NameNode的端口号为80974,让我们来看一下NameNode的动态内存大小。
[hadoop@hadoop101 ~]$ jmap -heap 80974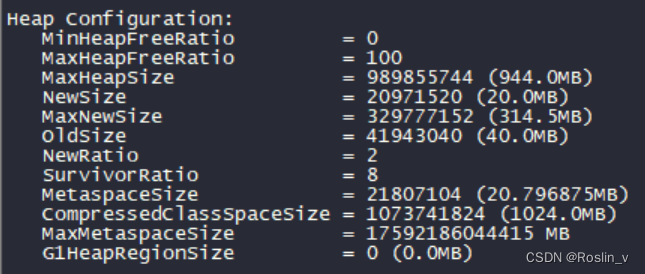
可以看到,MaxHeapSize只有944MB。而当初创建hadoop101时,我们分配给它4GB的内存。我们需要配置hadoop-env.sh,更改默认设置。
[hadoop@hadoop101 ~]$ cd /opt/module/hadoop-3.1.3
[hadoop@hadoop101 hadoop-3.1.3]$ vim etc/hadoop/hadoop-env.sh在配置文件中,找到下面两行,删掉前面的#注释符,并修改。
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"//重新启动集群
[hadoop@hadoop101 hadoop-3.1.3]$ myhadoop.sh stop
[hadoop@hadoop101 hadoop-3.1.3]$ myhadoop.sh start再次按照上述方法查看NameNode的动态内存大小,可以看到,MaxHeapSize已经被我们修改为1GB。
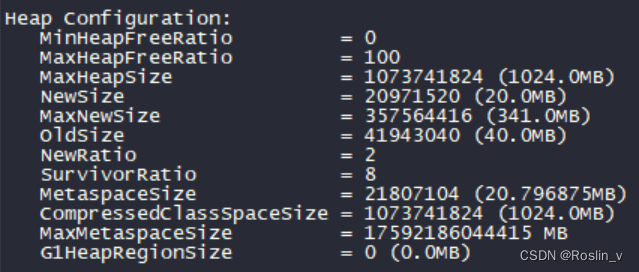
NameNode心跳并发配置
NameNode 有一个工作线程池,用来处理不同 DataNode 的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是 10。
企业经验:dfs.namenode.handler.count=20 × math.log(3),比如集群规模(DataNode 台数)为 3 台时,此参数设置为 21。可通过简单的 python 代码计算该值,代码如下。
//安装python
[hadoop@hadoop101 hadoop-3.1.3]$ sudo yum install -y python
//计算心跳值
[hadoop@hadoop101 hadoop-3.1.3]$ pythonimport math
print int(20*math.log(3))
quit()
得到心跳值为21后,我们可以在hdfs-site.xml中配置。
[hadoop@hadoop101 hadoop-3.1.3]$ vim etc/hadoop/hdfs-site.xml<!--NameNode心跳参数,默认值是10-->
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>开启回收站功能
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除。
[hadoop@hadoop101 hadoop-3.1.3]$ vim etc/hadoop/core-site.xml<!--设置回收功能,默认时间是0禁用-->
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>集群测压
在企业中非常关心每天从 Java 后台拉取过来的数据,需要多久能上传到集群?消费者关心多久能从 HDFS 上拉取需要的数据?为了搞清楚 HDFS 的读写性能,生产环境上非常需要对集群进行压测。
我们可以将三台虚拟机网络都设置为100mbps。在虚拟机-设置-网络适配器-高级中,将两个带宽都设置成电缆(100Mbps)。
//测试是否设置成功
[hadoop@hadoop101 software]$ python -m SimpleHTTPServer
我们到http://hadoop101:8000上,点击下载,会发现下载速度变快了。
如果执行上述命令时进程卡住了,可以ctrl+Z暂停,然后使用下列命令找到python进程的端口号,kill掉就可以了。
netstat -ntlp我们还可以测试一下写的性能。
//向 HDFS 集群写 10 个 128M 的文件
[hadoop@hadoop101 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
测试过程中出现了异常,是因为centos7与java8兼容性处理不是很好,虚拟内存是物理内存的2.1倍,就是物理内存4G,虚拟内存是8.4G。我们在yarn-site.xml中配置,就可以解决问题。
[hadoop@hadoop101 hadoop-3.1.3]$ vim etc/hadoop/yarn-site.xml<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将
其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>//分发脚本
[hadoop@hadoop101 hadoop-3.1.3]$ xsync etc/hadoop/
//重新启动
[hadoop@hadoop101 hadoop-3.1.3]$ myhadoop.sh stop
[hadoop@hadoop101 hadoop-3.1.3]$ myhadoop.sh start测试成功。

















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









