







本文主要对常用的Shell内置命令(Shell Builtin Commands)进行简单总结,另外本文所使用的Linux环境为CentOS Linux release 8.2.2004,所使用的Shell为bash 5.1.0(1)-release。
一、alias
alias [-p] [name[=value] …]
不带参数或使用-p选项,alias将以允许作为输入重用的形式在标准输出上打印别名列表。如果提供了参数,并且给出值,则为指定命令定义一个别名;如果没有给出值,则打印出别名的名称和值。
别名:
- 别名可以用一个字符串替换简单命令中的第一个单词。Shell维护一个别名列表,可以用内置命令
alias和unalias设置和删除别名。- 对于每条简单命令中的第一个单词,如果没被引用(unquoted,没加
'、"、\),Shell都会去检查它是否有别名,如果有,则该单词将被别名中的文本替换。/、$、`、=以及任何Shell元字符或引用字符(quoting characters,'、"、\)都不能出现在别名的名称中;替换文本中可以包含任何有效的Shell输入,包括Shell元字符。- 检查别名时只测试替换文本中的第一个单词,但与正在扩展(被替换)的别名相同的单词不会再次扩展(被替换),意思是不会递归的去扩展(替换)要替换的文本,例如可以把
ls作为ls -F的别名。- 如果别名值的最后一个字符是空格或制表符,则还要检查别名后的下一个命令的单词进行别名扩展。
- 在非交互式Shell中,除非使用
shopt命令设置shell的expand_aliases选项,否则不会进行别名扩展。- Bash在执行某一行或复合命令上的任何命令之前,总是读取至少一整行的输入以及复合命令的所有行,而别名是在读取命令时扩展,不是在执行时。所以同一行中另一个命令定义的别名直到读取下一行输入时才会生效,而该行中该别名之后的命令不受它影响。
- 别名在读取函数定义时扩展而不是在函数执行时,因为函数定义本身就是一个命令,因此,在函数中定义的别名直到该函数执行之后才能使用。
- 为了安全起见,始终在单独的行上定义别名,并且不要在复合命令中使用别名。
简单命令:简单命令是最常使用的命令,它只是一个由空白符(空格或制表符)分隔的单词序列,由Shell的一个控制运算符终止。其中第一个单词通常指定要执行的命令,其余单词都是该命令的参数。
复合命令:复合命令是Shell编程语言结构体,每个结构体都以一个保留字或控制运算符开始,以一个与之对应的保留字或控制运算符结束。复合命令包括循环结构(while、for等)、条件结构(if、case、(( ))、[[ ]]等)和命令组合。
控制运算符:一种执行控制功能的符号(token),包括换行符和以下之一:||、&&、&、;、;;、;&、;;&、|、|&、(或)。
这里以alias不带参数为例,显示当前Shell进程的别名列表:
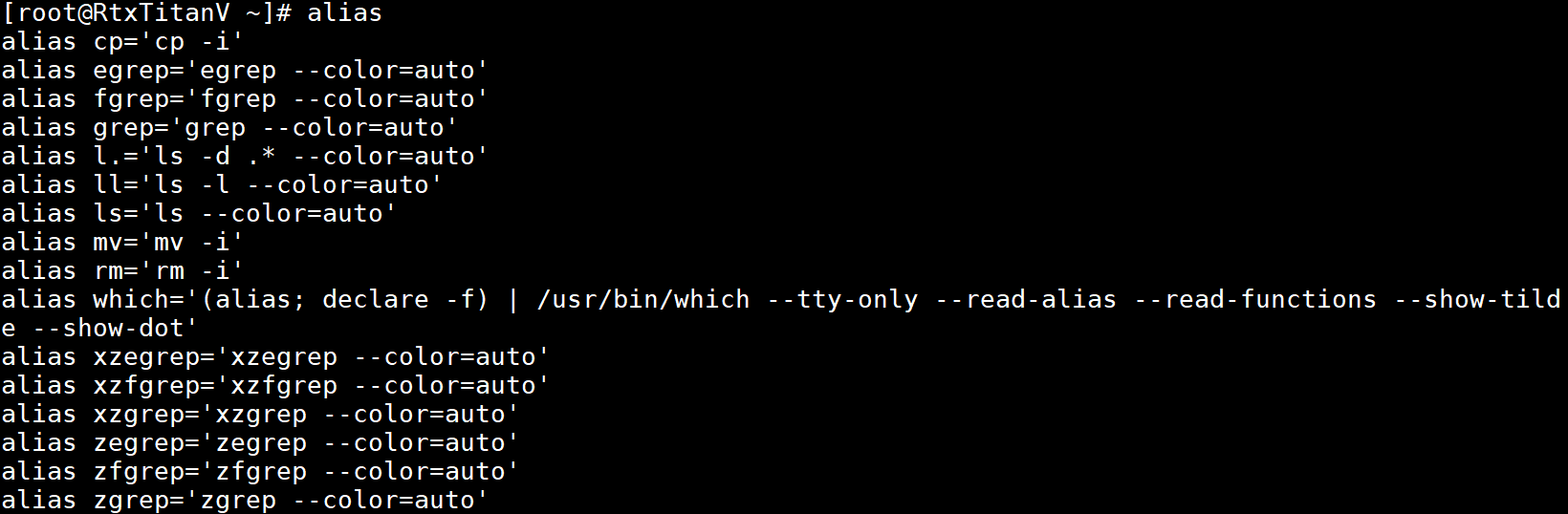
下例给命令ps -l创建一个别名pl,创建别名之后通过alias pl打印出了别名的名称和值,然后使用别名pl就可以执行ps -l:

下例给命令ps -j创建一个别名pj,然后又给pj -l创建别名pjl,这里的pjl会被替换为pj -l,而pj -l第一个单词pj也是一个别名,会被替换为ps -j,而ps在这里不是别名,不会被替换,最终使用pjl也执行了ps -jl:

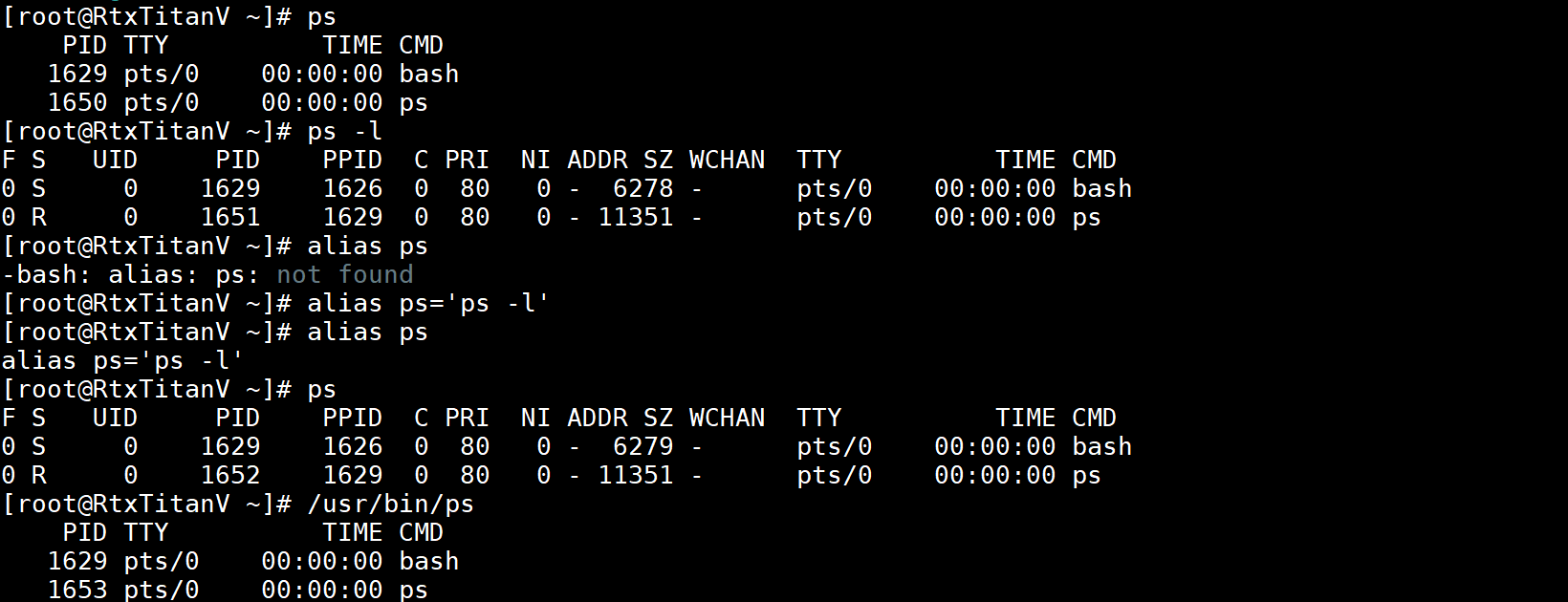
下例给命令ps -l创建一个别名ps,别名ps和命令ps重名,原本的命令ps会被覆盖,因为别名的优先级要高于命令,这时要使用原始的ps,只有使用绝对路径或相对路径来执行,这里的ps会被替换为ps -l,而ps -l的第一个单词与别名ps相同,则ps -l中的ps不会再被替换,即不会递归的去替换要替换的文本:
别名最好不要和系统命令重名。命令执行时的优先级由高到低:
- 用绝对路径或相对路径执行的命令。
- 别名。
- Bash内置命令。
- 按照
$PATH环境变量定义的目录査找的第一条命令。
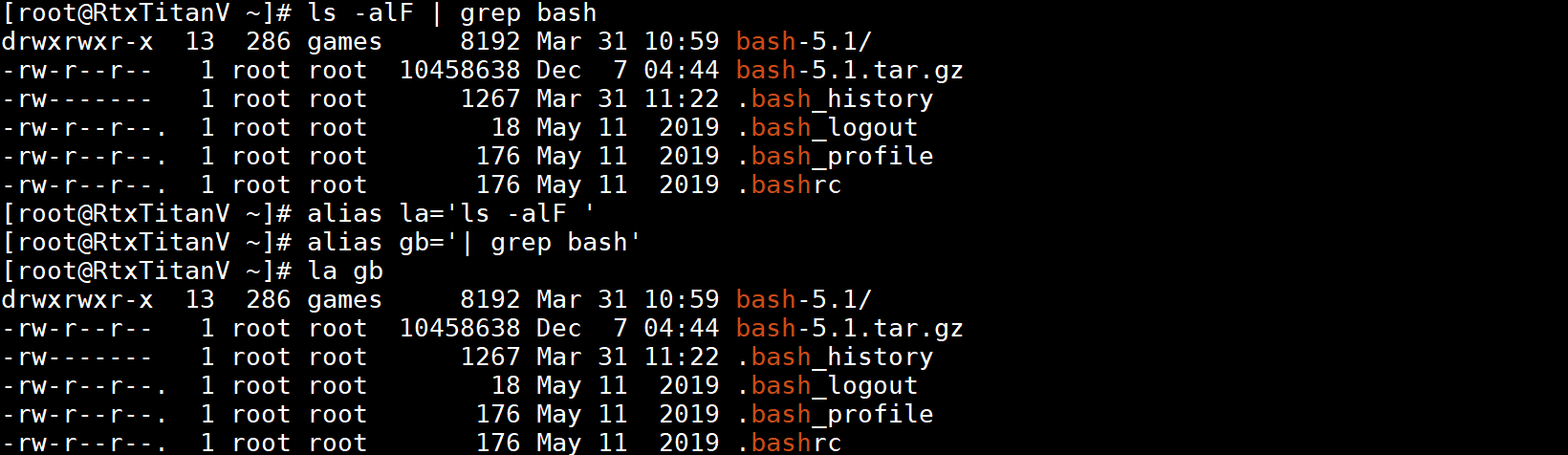
别名值的最后一个字符是空格或制表符时,还要检查别名后的下一个命令的单词进行别名扩展。这样可以把多个别名组合起来,这里以空格为例:
不要在复合命令或函数中使用别名。示例如下:
#!/bin/bash
# 非交互式Shell中要使用别名须用shopt命令设置shell的expand_aliases选项
shopt -s expand_aliases
if [ 1 ]
then
alias pl='ps -l'
# 复合命令中定义的别名要在整个命令结束后才生效
pl
fi
pl
function functest() {
alias la='ls -laF | grep bash'
# 函数中定义的别名要在函数执行之后才生效
la
}
functest
la
执行结果:
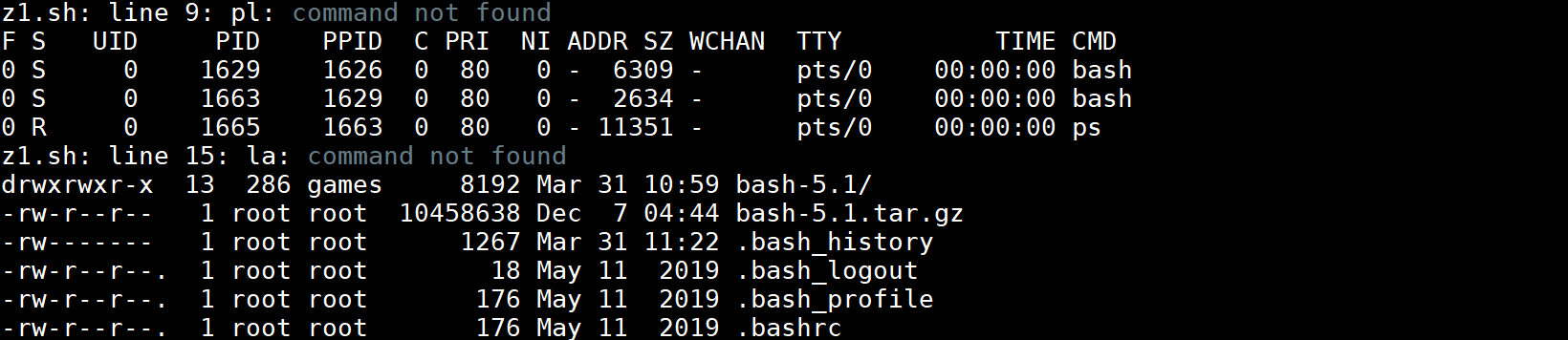
注意在非交互式Shell中要使用别名须用shopt命令设置shell的expand_aliases选项。把上面脚本中的shopt -s expand_aliases去掉后,在Shell脚本中就无法使用别名了,如下所示:

注意,在代码中使用alias命令定义的别名只能在当前Shell进程中使用,当前Shell进程结束后,别名也会随之消失。可以把别名写入配置文件~/.bashrc中,这些别名对启动时会加载该配置文件的Shell都有效。Shell脚本在执行时可以通过登录以加载配置文件的方式使用配置文件中定义的别名。
二、unalias
unalias [-a] [name … ]
从别名列表中删除指定名称的别名,如果提供了-a选项,则删除所有别名。
删除指定别名的示例如下:

删除所有别名:
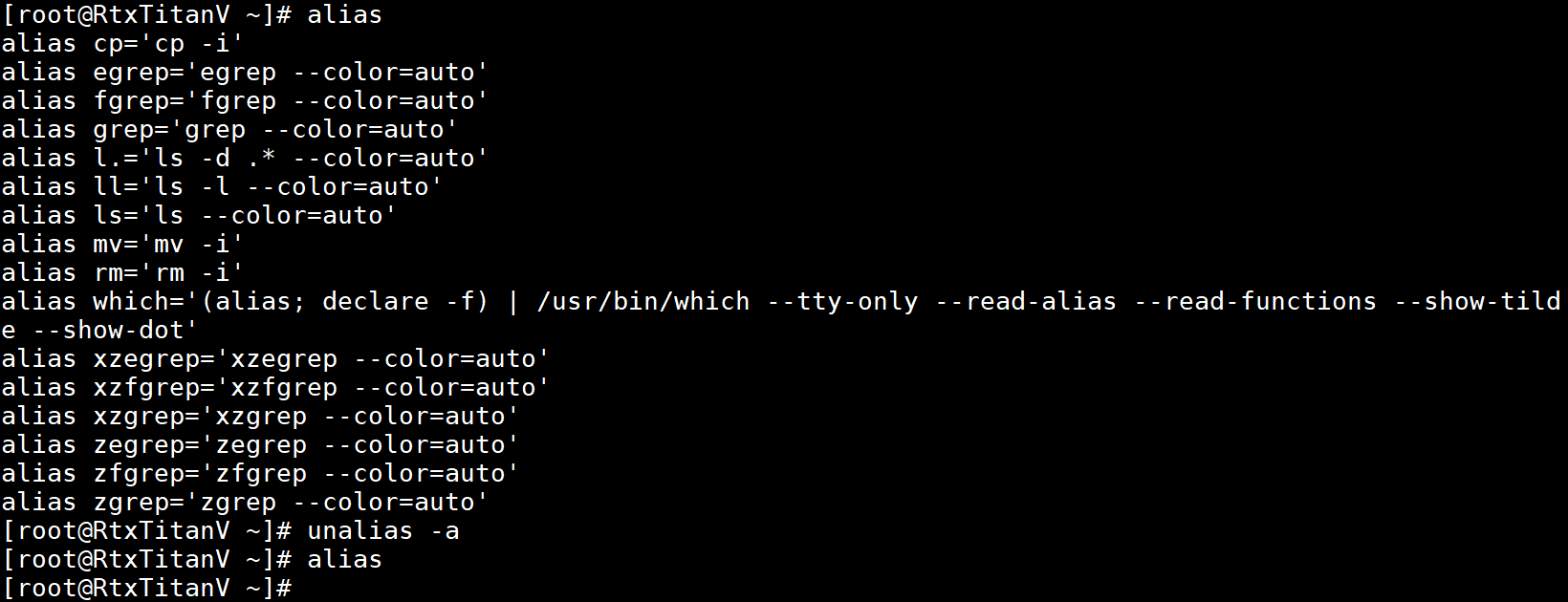
使用unalias删除只能在当前Shell进程生效,对于已经写入配置文件的别名,要想永久删除就需将配置文件中的别名定义删除。
三、exit
exit [n]
退出Shell并将状态n返回给Shell的父进程,如果省略n,则退出状态为最后被执行的命令的退出状态,EXIT陷阱是在Shell终止前执行的。
退出状态:
- 被执行的命令的退出状态是系统调用
waitpid或与其等价的函数所返回的值。退出状态介于0到255之间,Shell可能会特别使用高于125的值,某些情况Shell将使用特殊值来表示特定的错误状态。- 为了便于Shell处理,执行成功的命令退出状态为0,而退出状态非0则表示失败。
- 如果命令接到一个值为N的关键信号而退出,Bash会使用128+N作为它的退出状态。
- 如果未找到命令,则为执行它而创建的子进程将返回状态127。如果命令找到但不是可执行的,返回状态126。
- Bash的条件命令(
if,[[ ]]等)以及部分命令列表使用了退出状态。- 所有Bash内置命令都在成功时返回退出状态0,失败返回非0,如果使用错误(如无效的选项或缺少参数),所有内置命令都会返回退出状态2。
如下示例脚本在输出hello之后就退出并返回退出状态10:
#!/bin/bash
echo "hello"
exit 10
echo "world"
执行结果和退出状态如下:

四、echo
echo [-neE] [arg …]
输出参数,以空格分隔,换行符结束。除非发生写错误,否则返回状态为0。
选项:
-e:启用反斜杠\开头的转义字符的解释。-E:禁用转义字符的解释,即使在默认解释转义字符的系统也是如此。-n:结束时不会输出换行符。
默认情况下可以使用shell选项
xpg_echo动态决定echo是否解释转义字符。echo不解释指选项的结束的--。
echo输出默认以换行符结束,使用-n选项可以结束时不换行,示例如下:
#!/bin/bash
echo "hello"
echo "world"
echo -n "ja"
echo -n "va"
echo "script"
echo "shell"
执行结果:

使用-e可以开启转义字符的解释,-E禁用转义字符的解释,示例如下:
#!/bin/bash
echo "hello\nworld"
# 开启转义字符的解释,\n表示换行
echo -e "hello\nworld"
# 禁用转义字符的解释
echo -E "hello\nworld"
echo "helloworld\c"
# 开启转义字符的解释,\c表示不继续输出,放在最末尾可以达成不换行效果
echo -e "helloworld\c"
# 禁用转义字符的解释
echo -E "helloworld\c"
echo "hello\bworld"
# 开启转义字符的解释,\b表示退格
echo -e "hello\bworld"
# 禁用转义字符的解释
echo -E "hello\bworld"
执行结果:

五、declare
# 下面提到的"名称"都是指的这里的name参数
declare [-aAfFgiIlnrtux] [-p] [name[=value] …]
声明变量并赋予它们属性,如果没有给定名称,则显示变量的值。如果变量名称后面有=值,这个值就会被赋给该名称。除非遇到无效选项、试图用-f foo=bar的形式定义函数、试图给只读变量赋值、没有使用复合赋值语法给数组变量赋值、其中某个名称不是有效shell变量名、试图关闭只读状态的只读属性、试图关闭数组变量的数组状态或试图用-f显示一个不存在的函数,否则返回状态为0。
选项:
-p:显示每个名称的属性和值。-p和名称参数一起使用时,除-f和-F之外的其他选项将被忽略。- 如果
-p不带名称参数,将显示所有具有由其他选项指定的属性的变量的属性和值。如果给定-p而没提供其他选项,则显示所有Shell变量的属性和值。 -f选项限制输出只显示函数。-F选项禁止显示函数定义,只显示函数名和属性。如果使用shopt启用了shell的extdebug选项,则还会显示函数定义所在的源文件名和行号。-F选项隐含了-f。
-a:每个名称都是一个索引数组变量。-A:每个名称都是一个关联数组变量。-f:只使用函数名。-F:禁止显示函数定义,只显示函数名和属性。-g:强制在全局作用域中创建或修改变量,即使在shell函数中执行declare时也是如此。它在所有其他情况下都被忽略。-i:将变量视为整数,对它赋值时会进行算术求值。-I:会使local变量继承周围作用域中任何同名变量的属性(nameref属性除外)和值。如果没有现有的变量,则local变量初始时是未设置的。-l:当给变量赋值时,所有大写字母都转化为小写。禁用upper-case属性。-n:为每个名称赋予nameref属性,使其成为对另一个变量的名称引用(name reference),另一个变量由该名称的值定义。对名称的所有引用、赋值和属性修改(使用或更改-n属性本身除外)都将对名称的值所引用的变量执行。nameref属性无法应用于数组变量。-r:将名称设为只读,之后这些不能用赋值语句对这些名称赋值或用unset删除。-t:为每个名称赋予trace属性,设置了trace属性的函数继承调用它的shell的DEBUG和RETURN
类型的trap。trace属性对变量来说没有特殊意义。-u:当给变量赋值时,所有小写字母都转化为大写。禁用lower-case属性。-x:通过环境把每个名称导出给后续命令(将变量导出为环境变量)。
在选项前使用
+而不是-会关闭该属性,例外的是+a和+A不会销毁数组变量,+r也不会移除只读属性。
当在函数中使用时,declare使每个名称都是局部可见的,和local命令一样,除非使用了-g选项。
当使用-a或-A和复合赋值语法创建数组变量时,附加属性直到后续赋值才生效。
declare不指定名称,显示所有具有指定选项属性的变量的值和属性,如果没指定选项,显示所有变量和函数(不显示属性)。
-f选项限制输出只显示函数。-F禁止显示函数定义,只显示函数名和属性。
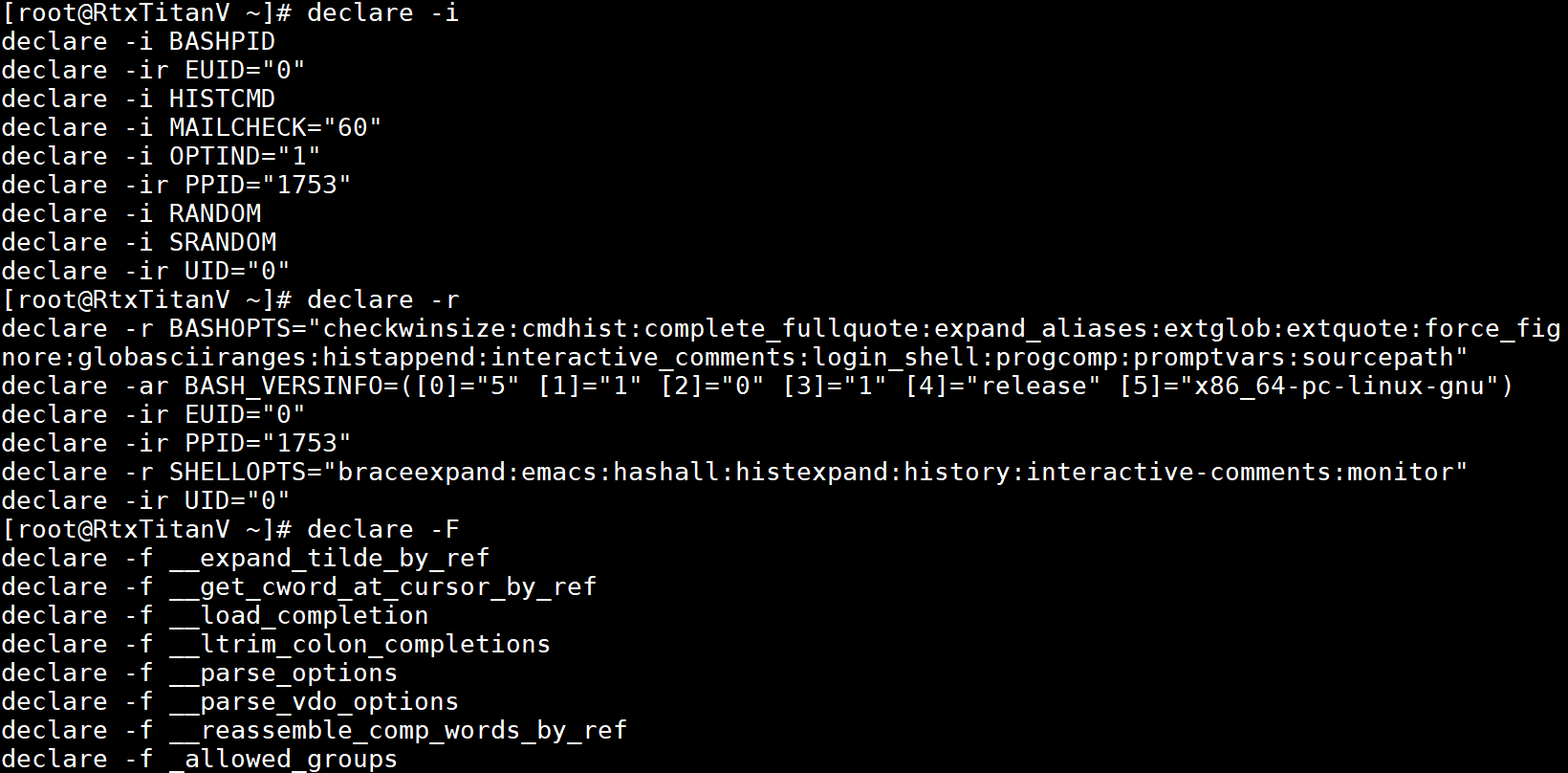
显示所有具有-i、-r属性的变量的属性和值以及显示所有函数的名称和属性(下图只截取了部分函数)的示例如下:
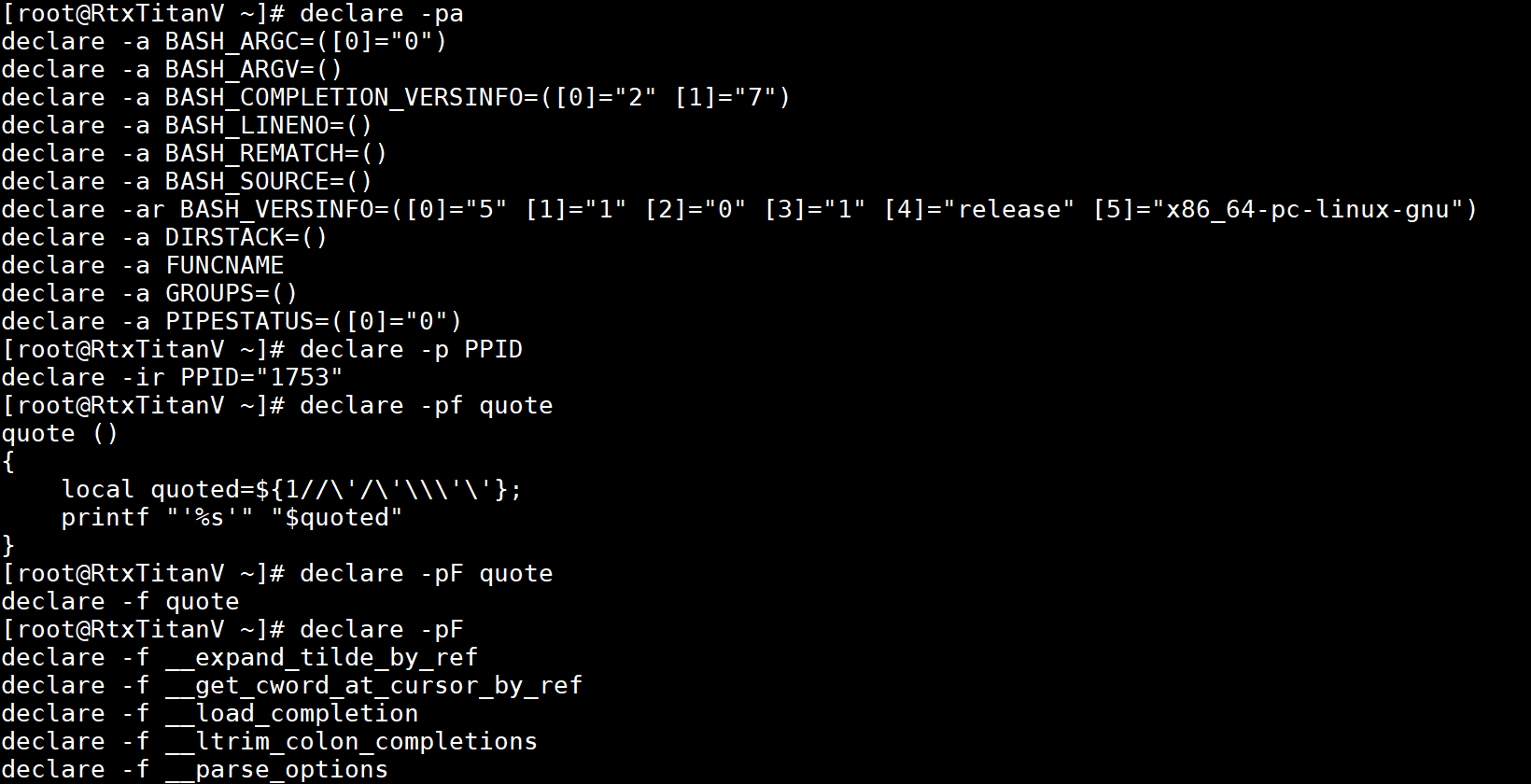
-p可以显示名称的属性和值,带名称参数则显示指定名称的属性和值,不带名称参数,则显示所有具有由其他选项指定的属性的变量的属性和值,如果也没有其他选项则显示所有Shell变量的属性和值。要显示函数需带上-f或-F选项。显示所有具有-a属性的(索引数组)变量的属性和值,显示指定变量的属性和值,显示指定函数的定义,显示指定函数的名称和属性以及显示所有函数的名称和属性(下图只截取了部分函数)的示例如下:
-a和-A可以分别声明索引数组和关联数组。示例如下:
#!/bin/bash
# 声明并创建索引数组
declare -a array1=([0]="sh" [2]="bash" [4]="csh")
# 显示array1的属性和值
declare -p array1
# 输出数组array1中的所有下标
echo ${!array1[@]}
# 输出数组array1中的所有元素
echo ${array1[@]}
# 声明并创建关联数组
declare -A array2=(["name"]="ZhangSan" ["age"]=25 ["tel"]="18912312312")
# 显示array2的属性和值
declare -p array2
# 输出数组array2中的所有下标
echo ${!array2[@]}
# 输出数组array2中的所有元素
echo ${array2[@]}
执行结果:

-i可以将声明的变量视为整数,对它赋值时会进行算术求值,仅支持最基本的数学运算。示例如下:
#!/bin/bash
declare -i result1 result2 result3 result4 result5 result6 result7 result8
m=5
n=3
result1=${m}+${n}
result2=m-n
result3=${m}*${n}
result4=m/n
result5=${m}%${n}
result6=m**n
# 需要用双引号包围,或在小括号前加\转义,形如\(${m}+${n}\)/\(${m}-${n}\),不然会报错
result7="(${m}+${n})/(${m}-${n})"
# 需要用引号(这里单引号和双引号都可以)包围或在小括号前加\转义,不然会报错
result8="(m+n)*(m-n)"
echo "m:${m},n:${n}"
echo "m + n : ${result1}"
echo "m - n : ${result2}"
echo "m * n : ${result3}"
echo "m / n : ${result4}"
echo "m % n : ${result5}"
echo "m ** n : ${result6}"
echo "(m + n) / (m - n) : ${result7}"
echo "(m + n) * (m - n) : ${result8}"
执行结果:

-l和-u可以在变量赋值时进行大小写转换。示例如下:
#!/bin/bash
# 给变量赋值时将所有大写字母转为小写
declare -l var1="HelloWorld"
echo ${var1}
# 给变量赋值时将所有小写字母转为大写
declare -u var2="HelloWorld"
echo ${var2}
执行结果:

-n为每个名称赋予nameref属性,使其成为对另一个变量的名称引用。对名称引用的赋值和属性修改(除-n属性本身)都会对它所引用的变量执行。示例如下:
#!/bin/bash
a="hello"
# 给ref1赋予nameref属性,成为对变量a的名称引用
declare -n ref1="a"
# 给ref2赋予nameref属性,成为对变量ref1的名称引用
declare -n ref2="ref1"
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# 给ref1赋值将对它所引用的变量a赋值
ref1="sh"
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# 给ref2赋值将对它所引用的变量ref1赋值,而给ref1赋值又将对它所引用的变量a赋值
ref2="bash"
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# a没有被声明为整数,赋值时不会进行算术求值
a=5+3
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# 将ref1声明为整数,实际上是将它引用的变量a声明为整数
declare -i ref1
a=5+3
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# 将ref2声明为只读变量,实际上是将它所引用的变量ref1声明为只读,ref1又引用a,最终将a声明为只读变量
declare -r ref2
# 由于a为只读变量,所以不能被修改
a=3
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
# 关闭ref1和ref2的nameref属性
declare +n ref1 ref2
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
ref1=5
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
ref2=2
echo "a : ${a}, ref1 : ${ref1}, ref2 : ${ref2}"
执行结果:

虽然nameref属性无法应用于数组变量,但被赋予nameref属性的变量可以引用数组变量或数组元素的变量。示例如下:
#!/bin/bash
declare -a array1=(1 2 3)
# nameref属性无法应用于数组变量
declare -an arrayref1="array1"
# 查看arrayref1会发现其没有nameref属性
declare -p arrayref1
# nameref属性变量可以引用数组变量
declare -n arrayref2="array1"
declare -p arrayref2
# nameref属性变量也可以引用数组元素
declare -n arrayref3="array1[1]"
declare -p arrayref3
# arrayref1没有nameref属性,对其赋值并不会影响数组array1
arrayref1=(2 4 6)
echo "arrayref1 : ${arrayref1[@]}, array1 : ${array1[@]}"
# arrayref2引用数组array1,对其赋值将对它所引用的变量赋值
arrayref2=(2 4 6)
echo "arrayref2 : ${arrayref2[@]}, array1 : ${array1[@]}"
# arrayref3引用数组元素array1[1],对其赋值将对它所引用的变量赋值
arrayref3=5
echo "arrayref3 : ${arrayref3}, array1[1] : ${array1[1]}"
执行结果:

注意直接使用unset删除nameref属性变量会删除它所引用的变量,要删除nameref变量,需使用unset -n。示例如下:

-r可以声明只读变量,只读变量的值不能改变也不能用unset删除只读变量。示例如下:

-x可以将变量导出为环境变量。示例如下:

-g赋予变量全局属性,在函数中使用declare时,如果不使用-g选项,则相当于使用local命令,声明的变量只能在函数内部使用。示例如下:
#!/bin/bash
function functest() {
# 声明变量a并赋予全局属性
declare -g a="hello"
# 在函数中使用declare声明变量时没使用-g选项,则相当于使用了local命令
# 声明local变量b,但只能在函数内部使用
declare b="world"
# 不用declare定义的变量默认具有全局属性
c="bash"
}
functest
declare -p a b c
echo -e "${a}\n${b}\n${c}"
执行结果:

-I会使local变量继承周围作用域中任何同名变量的属性(nameref属性除外)和值。示例如下:
#!/bin/bash
declare -i a=5 b=3 c=2
declare -n ref="b"
function functest() {
# -I会使local变量继承前一个作用域中任何同名变量的属性(nameref属性除外)和值
# 这里的local变量a会继承前一个作用域中的变量a的属性和值
# 这里的local变量b会继承前一个作用域中的变量b的属性和值
# 这里的local变量ref不会继承前一个作用域中的变量ref的nameref属性,但会继承值
# 没有现有的变量d,则local变量d初始时是未设置的
declare -I a b ref d
# 这里的local变量c不会继承前一个作用域中的变量c的属性和值
declare c
declare -p a b c ref d
echo "local a : ${a}"
echo "local b : ${b}"
echo "local c : ${c}"
echo "local ref : ${ref}"
echo "local d : ${d}"
a=a+1
c=c+1
ref=6
d="hello"
echo "local a : ${a}"
echo "local b : ${b}"
echo "local c : ${c}"
echo "local ref : ${ref}"
echo "local d : ${d}"
}
functest
# 修改函数中local变量的值不会改变函数外的同名变量的值
echo "a : ${a}"
echo "b : ${b}"
echo "c : ${c}"
echo "ref : ${ref}"
执行结果:

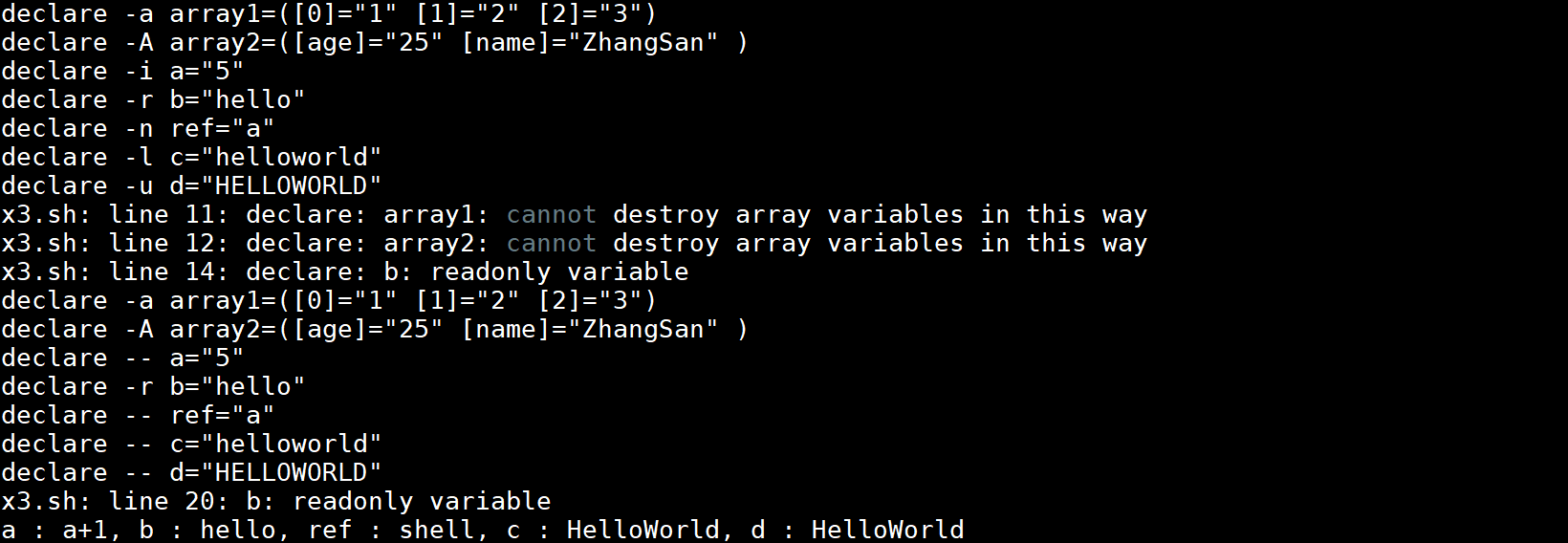
在选项前使用+关闭该属性,例外的是+a和+A不会销毁数组变量,+r也不会移除只读属性。示例如下:
#!/bin/bash
declare -a array1=(1 2 3)
declare -A array2=(["name"]="ZhangSan" ["age"]=25)
declare -i a=5
declare -r b="hello"
declare -n ref="a"
declare -l c="HelloWorld"
declare -u d="HelloWorld"
declare -p array1 array2 a b ref c d
declare +a array1
declare +A array2
declare +i a
declare +r b
declare +n ref
declare +l c
declare +u d
declare -p array1 array2 a b ref c d
a=a+1
b="world"
ref="shell"
c="HelloWorld"
d="HelloWorld"
echo "a : ${a}, b : ${b}, ref : ${ref}, c : ${c}, d : ${d}"
执行结果:
六、read
# 下面提到的"名称"都是指的这里的name参数
read [-ers] [-a aname] [-d delim] [-i text] [-n nchars]
[-N nchars] [-p prompt] [-t timeout] [-u fd] [name …]
从标准输入或者从-u选项参数提供的文件描述符fd中读取一行,通过单词拆分将其拆分为单词,并把第一个单词赋值给第一个名称,第二个单词赋值给第二个名称,依次类推,如果单词比名称多,则把剩余的单词连同分隔符一起赋值给最后一个名称,如果从输入流中读取的单词比名称少,则把剩余的名称赋为空值。如果没有提供名称,则将不带结束分隔符但其他方面未修改的已读行赋值给REPLY变量。除非遇到文件结束标志、读取超时(这种情况返回状态大于128)、发生变量赋值错误(如赋值给只读变量)或提供了无效的文件描述符作为-u的参数,否则退出状态为0。
IFS变量中的字符用来把文本行拆分成单词。反斜杠
\可以用来去除下一个读取的字符的特殊含义以及续行。
选项:
-a aname:把单词赋值给数组变量aname中从0开始的连续下标。在赋值之前把aname中所有元素都删除。其他的名称参数都将被忽略。-d delim:用delim的第一个字符来结束输入行,而不是用换行符。如果delim是空字符串,则将在读取到NUL字符时终止一行。-e:用Readline来获取行,Readline使用当前的编辑设置,如果之前没启用行编辑功能,则使用默认设置。-i text:如果使用Readline来读取行,则文本text会在开始编辑之前被放到编辑缓冲区中。-n nchars:在读取到nchars个字符后返回,而不是读入一整行才返回。如果在定界符(结束符)之前读取的字符数少于nchars,则会使用定界符结束输入行。-N nchars:除非遇到EOF或者read超时,否则read在完全读取到nchars个字符后返回,而不是读入一整行才返回。在输入中遇到的定界符不会被特殊处理,除非读取到nchars个字符,否则不会导致read返回。结果不会根据IFS中的字符进行拆分,这样做的目的是让变量的赋值与所读的字符完全一致(除了反斜杠)。-p prompt:在试图读取任何输入之前显示不带换行符的提示符prompt。只有当输入来自终端时才会显示该提示符。-r:如果指定该选项,反斜杠\将不作为转义字符,被认为是文本的一部分,\newline也不能用作行连续符。-s: 静默模式(Silent mode),如果输入来自终端,则不回显字符。-t timeout:如果没有在超时时间timeout指定的秒数内读取完整的输入行或指定数量的字符,则读取超时并返回失败。timeout可以是带有小数的十进制数。该选项只有在read从终端、管道或其他特殊文件中读取输入时才有效,从普通文件中读取时无效。如果read超时,read将保存读入指定变量名的部分输入。如果timeout为0,则read立即返回,而不尝试读取任何数据。如果指定的文件描述符上有可用输入,则退出状态为0,否则为非0。如果超时,则退出状态大于128。-u fd:从文件描述符fd中读取输入。
从终端读取输入,-p显示提示信息。示例如下:
#!/bin/bash
read -p "Enter user information > " name age tel
echo -e "name : ${name}\nage : ${age}\ntel : ${tel}"
输入的单词和名称一样多,则将输入的单词依次赋值给每个名称。执行结果:
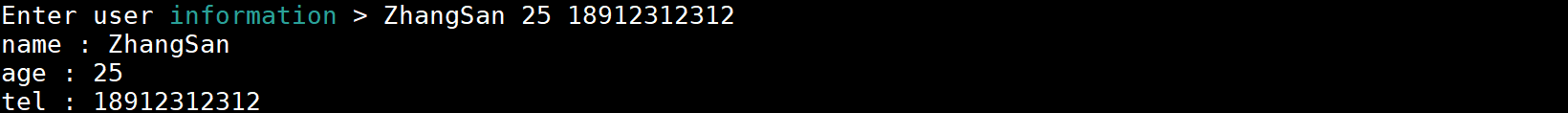
输入的单词比名称多,则将剩余的单词连同分隔符一起赋值给最后一个名称。执行结果:

输入的单词比名称少,则把剩余的名称赋为空值。执行结果:

如果没提供名称,则将不带结束分隔符但其他方面未修改的已读行赋值给REPLY变量。示例如下:

-a选项可以把单词赋值给指定数组,从下标0开始,在赋值之前会把指定数组中所有元素都删除,其他的名称参数都将被忽略。示例如下:
#!/bin/bash
num=(1 2 3)
declare -p num
read -p "Enter a number sequence > " -a num a b c
declare -p num
echo ${!num[@]}
echo ${num[@]}
echo "a : ${a}, b : ${b}, c : ${c}"
执行结果:
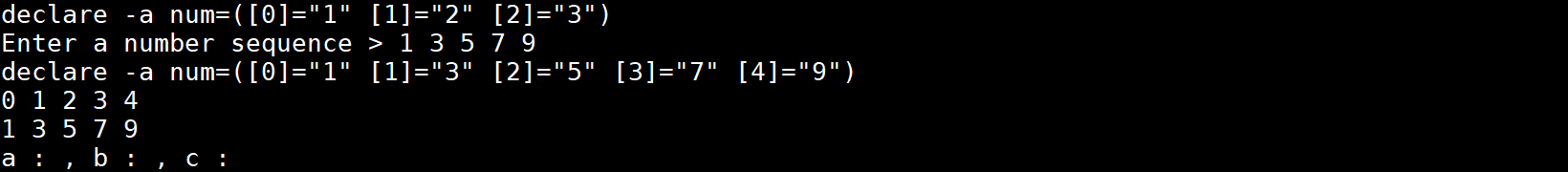
-d可以指定输入的定界符(结束符)。示例如下:
#!/bin/bash
# 用.End的第一个字符.结束输入行
read -d ".End" -p "Enter message > " message
echo -e "\nmessage : ${message}"
执行结果:

-e选项用Readline来获取行,可以对功能键进行编码转换,不会直接显式功能键对应的字符。下例中输入的左右上下、Home键、End键和Del键,在没用-e时,功能失效,显示的功能键对应的字符,使用-e时对功能键进行编码转换,功能没有失效,不显示对应的字符:

-i选项可以使用Readline来读取行,指定的文本会在开始编辑前放到编辑缓冲区。示例如下:

-n选项可以指定读取到多少个字符返回,如果定界符(结束符)之前的读取字符数小于指定读取字符数,则会用定界符结束输入行。示例如下:
#!/bin/bash
read -d "." -n 5 -p "Enter message > " message
if ((${#message}==5))
then
echo -e "\n读取到指定字符数结束输入行"
echo "message : ${message}"
else
echo -e "\n由.结束输入行"
echo "message : ${message}"
fi
读取到5个字符结束输入行,执行结果:

在读取到5个字符之前遇到.,执行结果:

-N选项可以指定读取到多少个字符返回,除非遇到EOF或者read超时,否则都会读取到指定字符数结束输入。在输入中遇到定界符(结束符)不会结束输入,除非读取到指定字符数。示例如下:
#!/bin/bash
# 指定读取到5个字符返回,20秒超时时间
read -d "." -N 5 -t 20 -p "Enter message > " message
echo -e "\nmessage : ${message}"
在输入中遇到定界符.不会结束输入,执行结果:

在读取到指定字符数之前超时会立即结束输入,执行结果:

使用输入重定向从标准输入中读取,在读取到指定字符数之前遇到EOF符也会结束输入,否则读取到指定字符数才结束输入。示例如下:

-r选项不对转义字符进行解释,原样读取。示例如下:
#!/bin/bash
read -p "Enter message1 > " message1
echo "message1 : ${message1}"
read -rp "Enter message2 > " message2
echo "message2 : ${message2}"
执行结果:

终端输入用-s不回显输入字符,-t指定超时时间。示例如下:
#!/bin/bash
# 密码输入没超时并且两次输入密码相同,则密码有效,否则密码无效
if
read -t 20 -sp "Enter password in 20 seconds(once) > " password1 && printf "\n" &&
read -t 20 -sp "Enter password in 20 seconds(again) > " password2 && printf "\n" &&
[[ ${password1} == ${password2} ]]
then
echo "valid password"
else
echo "invalid password"
fi
两次密码输入相同,执行结果:

两次密码输入不相同,执行结果:

第一次输入超时,执行结果:

第二次输入超时,执行结果:

使用-u选项可以从文件描述符fd中读取输入。示例如下:
#!/bin/bash
# 将重定向输入的内容重定向输出到文件中
cat > test.txt << EOF
hello
world
shell
bash
EOF
# 将文件指向文件描述符3,<表示只能读取文件
exec 3<test.txt
# 从文件描述符3中读取,每次循环读取一行输出
while read -u 3 line
do
echo ${line}
done
执行结果:

使用read命令从文件中逐行读取的示例如下:
#!/bin/bash
# 将重定向输入的内容重定向输出到文件中
cat > test.txt << EOF
One line is read
from the standard input
or from the file descriptor fd
supplied as an argument
to the -u option
EOF
function file_read1() {
while read line
do
echo ${line}
done < test.txt
}
function file_read2() {
cat test.txt | while read line
do
echo ${line}
done
}
function file_read3() {
exec 3<test.txt
while read -u 3 line
do
echo ${line}
done
}
echo "输入重定向方式"
file_read1
echo "管道方式"
file_read2
echo "文件描述符方式"
file_read3
执行结果:

七、test和[
# expr为条件表达式
test expr
# 若使用[形式,命令的最后一个参数必须是],[]和test是等价的
# []和expr之间的两个空格是必须的,否则会导致语法错误
[ expr ]
计算条件表达式并返回状态0(true)或1(false)。每个运算符和运算数都必须是独立的参数。test不接受任何选项,也不接受并忽略表示选项结束的参数--。
这里的条件表达式主要由关系运算符(
-eq、-ne、-lt、-le、-gt、-ge)、字符串运算符、文件测试运算符组成。可以使用布尔运算符(-a、-o、!)或小括号()组合表达式,这四个运算符优先级从左到右降序排列:!、()、-a、-o。对表达式的求值结果取决于参数的数量。
test和[内置命令使用一组基于参数数量的规则对条件表达式进行计算:
- 0个参数:表达式为false。
- 1个参数:当且仅当参数不为空时,表达式为true。
- 2个参数:如果第一个参数是
!,当且仅当第二个参数为空时,表达式为true。如果第一个参数是一个单目运算符,则如果单目测试为true,则表达式为true。如果第一个参数不是个有效的单目运算符,则表达式为false。 - 3个参数:如果第二个参数是一个双目运算符,则表达式的结果是把第一和第三个参数作为运算数的双目测试的结果。当有三个参数时,
-a和-o被视为双目运算符。如果第一个参数是!,则结果为使用第二和第三个参数的双参数测试的否定值。如果第一个参数为(并且第三个参数为),则结果是第二个参数这一个参数的测试结果。否则,表达式为false。 - 4个参数:如果第一个参数为
!,则结果与剩余三个参数组成的表达式的值相反,否则,表达式将使用上面的规则根据优先级进行计算。 - 5个或更多参数:表达式将使用上面的规则根据优先级进行计算。
当与
test或[]一起使用时,<或>使用ASCII排序按字典顺序排序。
没有参数和只有1个参数的示例如下:

只有2个参数的示例如下:
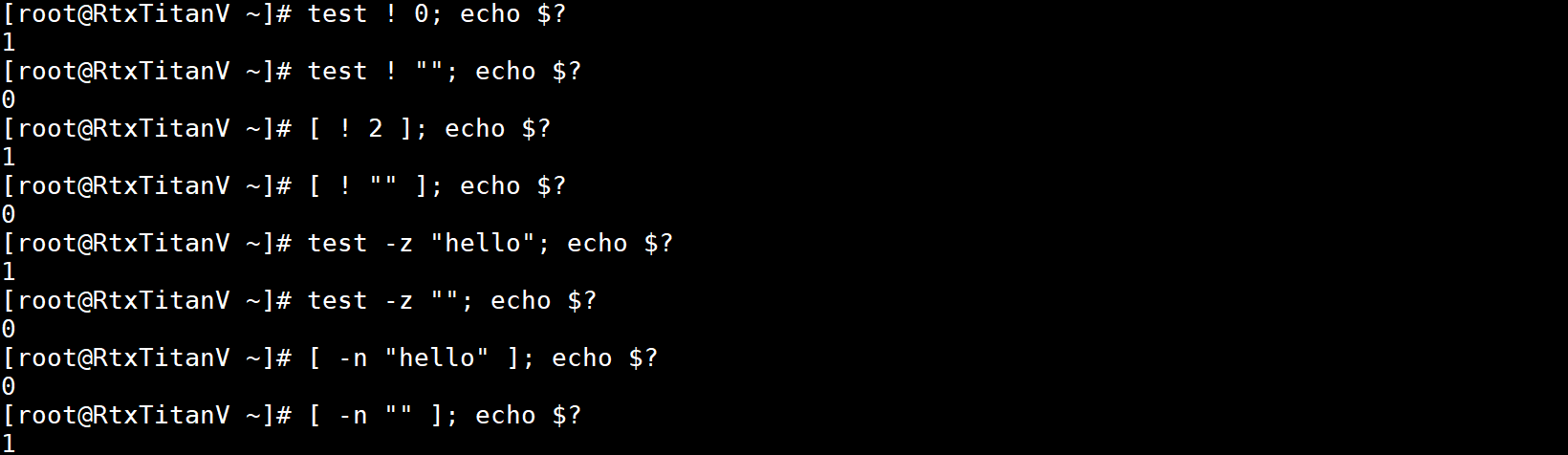
只有3个参数的示例如下:
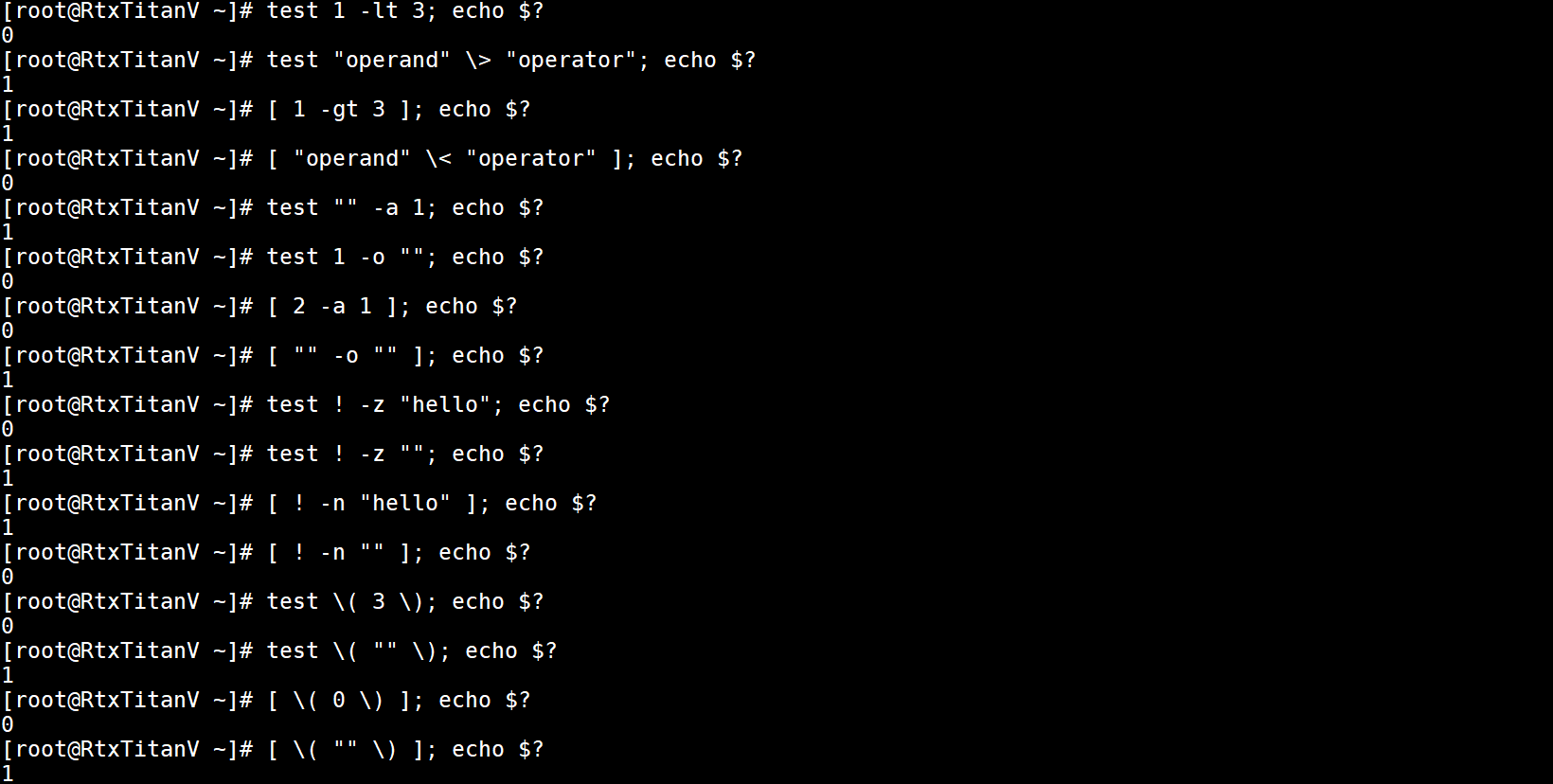
使用test进行整数比较的示例如下:
#!/bin/bash
# 输入一个成绩,判断并输出成绩的等级
read -p "输入考试成绩 > " score
if test ${score} -lt 0 -o ${score} -gt 100; then
echo "输入的成绩有误"
elif test ${score} -ge 90 -a ${score} -le 100; then
echo "优"
elif test ${score} -ge 80 -a ${score} -lt 90; then
echo "好"
elif test ${score} -ge 70 -a ${score} -lt 80; then
echo "良"
elif test ${score} -ge 60 -a ${score} -lt 70; then
echo "及格"
else
echo "不及格"
fi
执行结果:

使用[]进行字符串比较的示例如下:
#!/bin/bash
read -p "输入第一个字符串 > " str1
read -p "输入第二个字符串 > " str2
# 在test或[]中使用变量时建议用双引号引起来,避免变量为空时导致的很多问题或单词拆分造成的错误
if [ -z "${str1}" -o -z "${str2}" ]
then
echo "字符串不能为空"
exit 1
fi
if [ "${str1}" == "${str2}" ]
then
echo "两个字符串相等"
else
echo "两个字符串不相等"
fi
if [ "${str1}" != "${str2}" ]
then
echo "两个字符串不相等"
else
echo "两个字符串相等"
fi
if [ "${str1}" \> "${str2}" ]
then
echo "str1大于str2"
else
echo "str1不大于str2"
fi
if [ "${str1}" \< "${str2}" ]
then
echo "str1小于str2"
else
echo "str1不小于str2"
fi
执行结果:

使用[]进行文件检测的示例如下:
#!/bin/bash
read -p "输入file1的路径 > " file1
read -p "输入file2的路径 > " file2
if [ -a "${file1}" ]
then
echo "-a ${file1} : file1存在"
else
echo "-a ${file1} : file1不存在"
fi
if [ -b "${file1}" ]
then
echo "-b ${file1} : file1是块设备文件"
else
echo "-b ${file1} : file1不是块设备文件"
fi
if [ -c "${file1}" ]
then
echo "-c ${file1} : file1是字符设备文件"
else
echo "-c ${file1} : file1不是字符设备文件"
fi
if [ -d "${file1}" ]
then
echo "-d ${file1} : file1是目录"
else
echo "-d ${file1} : file1不是目录"
fi
if [ -e "${file1}" ]
then
echo "-e ${file1} : file1存在"
else
echo "-e ${file1} : file1不存在"
fi
if [ -f "${file1}" ]
then
echo "-f ${file1} : file1是普通文件"
else
echo "-f ${file1} : file1不是普通文件"
fi
if [ -h "${file1}" ]
then
echo "-h ${file1} : file1是符号链接"
else
echo "-h ${file1} : file1不是符号链接"
fi
if [ -L "${file1}" ]
then
echo "-L ${file1} : file1是符号链接"
else
echo "-L ${file1} : file1不是符号链接"
fi
if [ -r "${file1}" ]
then
echo "-r ${file1} : file1可读"
else
echo "-r ${file1} : file1不可读"
fi
if [ -s "${file1}" ]
then
echo "-s ${file1} : file1大小大于0"
else
echo "-s ${file1} : file1大小为0"
fi
if [ -w "${file1}" ]
then
echo "-w ${file1} : file1可写"
else
echo "-w ${file1} : file1不可写"
fi
if [ -x "${file1}" ]
then
echo "-x ${file1} : file1可执行"
else
echo "-x ${file1} : file1不可执行"
fi
if [ -G "${file1}" ]
then
echo "-G ${file1} : file1被有效组id所拥有"
else
echo "-G ${file1} : file1没有被有效组id所拥有"
fi
if [ -O "${file1}" ]
then
echo "-O ${file1} : file1被有效用户id所拥有"
else
echo "-O ${file1} : file1没有被有效用户id所拥有"
fi
if [ -S "${file1}" ]
then
echo "-S ${file1} : file1是套接字"
else
echo "-S ${file1} : file1不是套接字"
fi
if [ "${file1}" -nt "${file2}" ]
then
echo "${file1} -nt ${file2} : file1比file2新"
else
echo "${file1} -nt ${file2} : file1不比file2新"
fi
if [ "${file1}" -ot "${file2}" ]
then
echo "${file1} -ot ${file2} : file1比file2旧"
else
echo "${file1} -ot ${file2} : file1不比file2旧"
fi
测试用的文件如下:

执行结果:
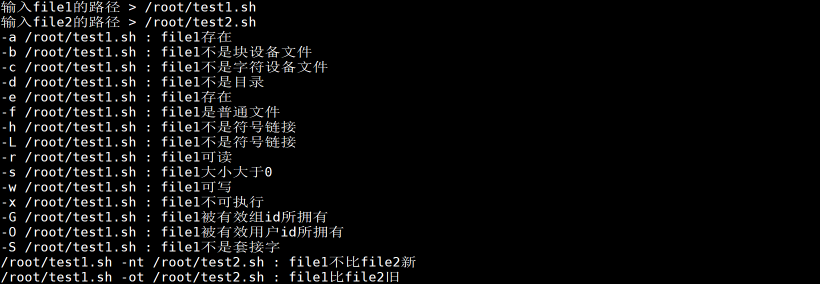
在test或[]中使用变量时建议用双引号引起来,这样能避免变量为空时导致的很多问题或单词拆分造成的错误。
八、type
# 下面提到的"名称"都是指的这里的name参数
type [-afptP] [name …]
对于每个名称,如果把它作为命令名,指示如何解释。如果能找到所有名称,则返回状态为0,否则返回非0。
选项:
-a:type返回包含可执行命名文件的所有位置,当且仅当没有同时使用-p时才包括别名、函数、内置命令、保留字。-f:type不会像内置命令那样试图查找shell函数。-p:type要么返回将要执行的磁盘文件名,要么什么也不返回,如果-t不是返回file的话。-t:打印单个单词,如果名称分别是别名、shell函数、shell内置命令、磁盘文件或shell保留字,则分别打印alias、function、builtin、file或keyword,如果没有找到名称,则不打印任何内容,type返回一个失败状态。-P:强制查找每个名称对应的路径,即使-t不返回file。如果命令在散列表中,则-P和-p打印散列表中的值,它不一定是$PATH中首先找到的文件。
type命令可以解释每个名称的类型,是一个内置命令,还是别名,还是保留字等,找到所有名称才返回0。示例如下:
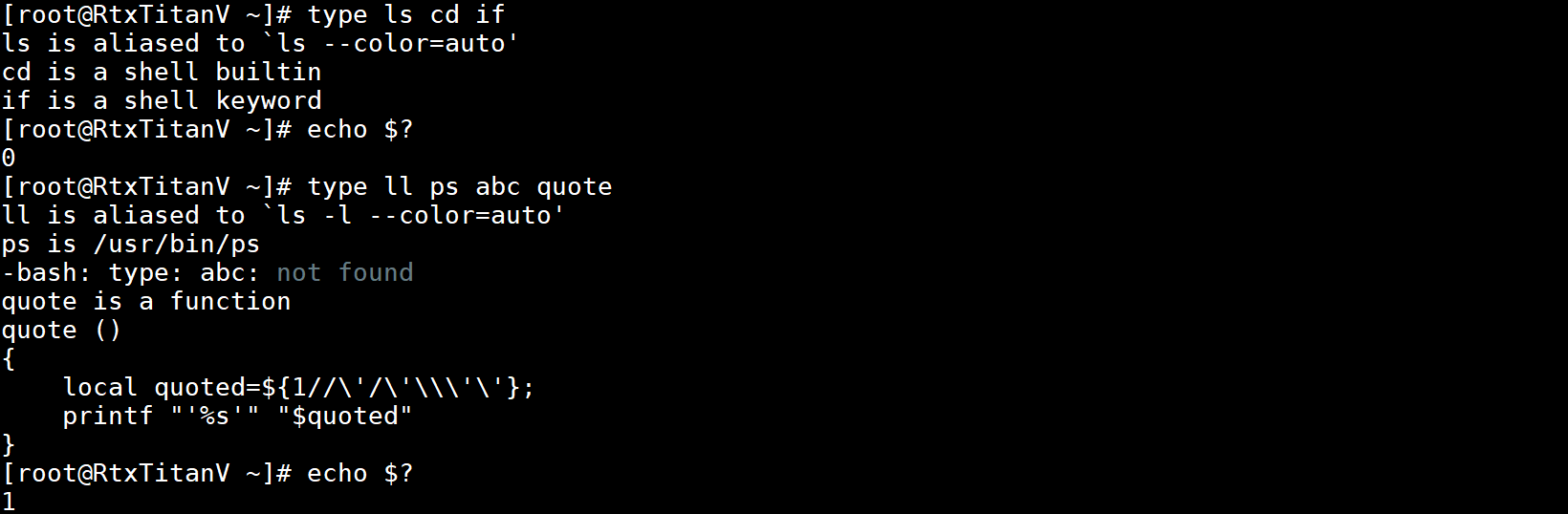
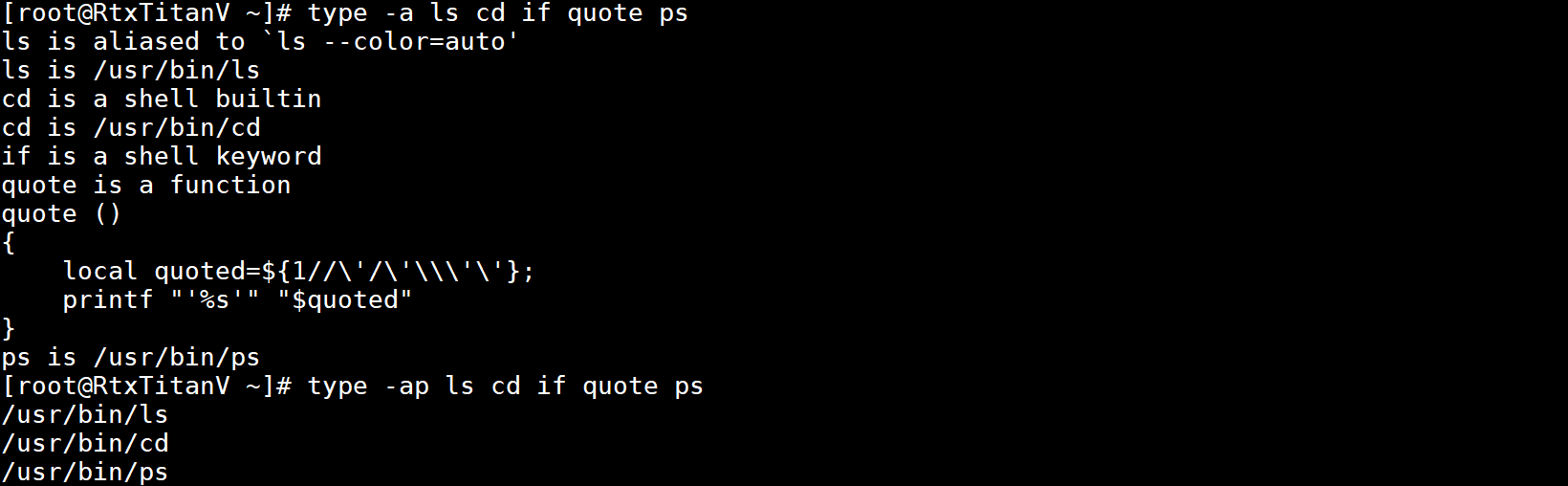
-a选项会打印名称所有可能的类型(没用同时使用-p时才包括别名、函数、内置命令、保留字,否则打印名称文件所有位置)。示例如下:
-f选项不会去查找函数。示例如下:

-p选项只输出-t选项返回file的磁盘文件。示例如下:

-t选项打印别名、shell函数、shell内置命令、磁盘文件或shell保留字对应的单词alias、function、builtin、file或keyword,没有找到名称不打印任何内容,返回失败状态。示例如下:

-P强制查找每个名称对应的路径,即使-t不返回file。示例如下:

九、break
break [n]
从for、while、until或select循环中退出。如果给定n,则退出n层循环,n必须大于或等于1。除非n小于1,否则返回状态为0。
使用break退出单层循环的示例如下:
#!/bin/bash
for (( i=1; ; i++ ))
do
if ((i>9))
then
# 退出外层循环
break
fi
for (( j=1; ; j++ ))
do
if ((j>i))
then
# 退出内层循环
break
fi
echo -n "${i}*${j}=$((i*j)) "
done
echo ""
done
执行结果:

使用break退出多层循环的示例如下:
#!/bin/bash
for (( i=1; ; i++ ))
do
for (( j=1; ; j++ ))
do
if ((i>9))
then
# 退出2层循环
break 2
fi
if ((j>i))
then
# 退出内层循环
break
fi
echo -n "${i}*${j}=$((i*j)) "
done
echo ""
done
执行结果:

十、continue
continue [n]
跳过for、while、until或select的本次循环,继续执行下一次循环。如果给定n,则跳过n层循环中的本次循环(n层循环的每一层都会跳过本次循环),继续执行下一次循环。n必须大于或等于1。除非n小于1,否则返回状态为0。
使用continue跳过单层循环的本次循环的示例如下:
#!/bin/bash
for (( i=1; i<=9 ; i++ ))
do
if ((i%2==0))
then
# 跳过外层循环的本次循环
continue
fi
for (( j=1; j<=i ; j++ ))
do
if ((j%3==0))
then
# 跳过内层循环的本次循环
continue
fi
echo -n "${i}*${j}=$((i*j)) "
done
echo ""
done
执行结果:

使用continue跳过多层循环的本次循环的示例如下:
#!/bin/bash
for (( i=1; i<=9 ; i++ ))
do
for (( j=1; j<=i ; j++ ))
do
if ((j%3==0))
then
# 跳过2层循环的本次循环
continue 2
fi
echo -n "${i}*${j}=$((i*j)) "
done
echo ""
done
echo ""
执行结果:
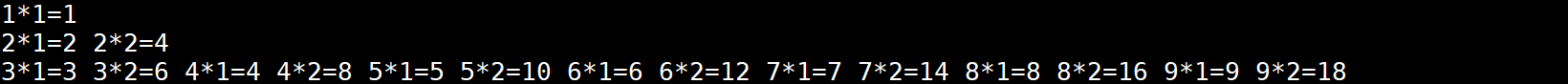
















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











