






Elasticsearch、Kibana 和 Logstash 通常被统称为 ELK 堆栈
在软件项目中一般充当:数据存储和搜索、日志管理、数据可视化等功能角色
成员介绍
ElasticSearch
- 定义:Elasticsearch是一个基于Lucene的分布式、RESTful风格的搜索和数据分析引擎
- 主要功能:
- 全文搜索:可以快速地执行全文搜索,返回相关性最高的结
- 实时索引:支持实时索引数据,意味着数据可以几乎实时地被搜索到
- 分布式架构:设计为分布式系统,可以水平扩展,处理PB级的数据
- 数据分析:除了搜索,还可以执行复杂的数据分析,如聚合、排序和过滤
- 使用场景:日志分析、实时监控、搜索引擎、数据仓库等
Kibana
- 定义:Kibana是一个为Elasticsearch设计的开源数据可视化和分析工具
- 主要功能:
- 可视化:提供丰富的可视化选项,如柱状图、折线图、饼图、地图等,帮助用户直观地理解数据
- Dashboard:可以创建和共享交互式的Dashboard,展示多个可视化结果
- 探索数据:允许用户通过简单的界面探索Elasticsearch中的数据
- 实时展示:与Elasticsearch结合,可以实时展示数据变化
- 使用场景:与Elasticsearch配合使用,进行数据可视化、日志分析、业务监控等
Logstash
- 定义:Logstash是一个开源的服务器端数据处理管道,它能够同时从多个来源采集数据,转换数据,然后将数据发送到指定的“stash”(存储库)中
- 主要功能:
- 数据采集:能够从各种数据源(如日志文件、系统事件、网络包、社交媒体 feeds 等)中采集数据
- 数据转换:可以将非结构化的日志数据转换为结构化的JSON格式,便于后续处理和分析
- 数据输出:可以将处理后的数据发送到各种目的地,如Elasticsearch、数据库、消息队列等
- 使用场景:日志管理、数据转换、集成各种不同数据源
从Docker开始
镜像准备
从Docker @ Elastic网站中可以看到Elastic的所有项目的Docker镜像以及更新时间
从Documentation网站中可以学习这些项目的官方文档
这里我们主要使用ELK三个项目,在这里我们以8.16.1版本为案例分别拉取三个镜像:
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.16.1
docker pull docker.elastic.co/logstash/logstash:8.16.1
docker pull docker.elastic.co/kibana/kibana:8.16.1创建Network
docker network create elastic搭建ElasticSearch
启动命令
docker run --name es01 --net elastic -p 9200:9200 -it \
-e "ELASTIC_PASSWORD=elastic" \
-v /docker/elasticsearch/data:/usr/share/elasticsearch/data \
-d docker.elastic.co/elasticsearch/elasticsearch:8.16.1
内容说明
--name es01:容器的名字可以自定义随便改
--net elastic:指定容器连接到名为 elastic 的 Docker 网络。这使得该容器能够与同一网络中的其他容器进行通信。
-p 9200:9200:这个选项将宿主机的 9200 端口映射到容器的 9200 端口,允许从外部访问 Elasticsearch 的 HTTP API。访问 http://localhost:9200 将会链接到容器中的 Elasticsearch 服务。
-it: 这个组合选项使容器以交互模式运行,并分配一个伪终端。虽然这个选项在后台运行的容器中不总是必要,但在调试时很有用。
-e "ELASTIC_PASSWORD=elastic": 这个选项设置环境变量 ELASTIC_PASSWORD,用于配置 Elasticsearch 的默认用户(elastic)的密码为 elastic。这对安全性非常重要。
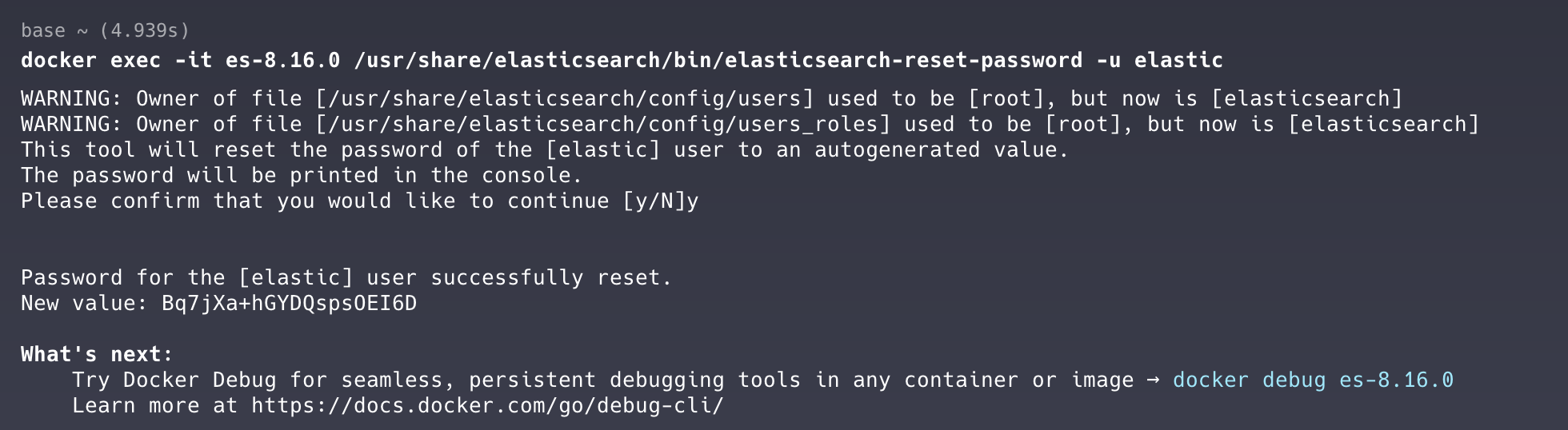
如果不打算在环境变量里指定固定的密码,后续可以通过此命令获取一个重置后的新密码
docker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic注意: -it 后面是es容器的自定义名称
通过执行命令之后会得到一个new value ,里面就是 用户名 elastic 的密码
-v /docker/elasticsearch/data:/usr/share/elasticsearch/data: 这个选项将宿主机的 /docker/elasticsearch/data 目录挂载到容器的 /usr/share/elasticsearch/data 目录。这使得 Elasticsearch 的数据可以持久化存储,即使容器被删除或重新启动,数据也不会丢失。
-v 后面 是两个路径 用冒号(:)分开,其中左侧是宿主机本地的路径,后面是容器内部的路径,即使不自己手动去创建这个文件夹,在执行命令之后,也会自动创建,所以确定好位置之后,把自定义的位置设置在冒号左侧即可
-d: 这个选项让容器在后台运行(即“分离模式”)。这样你可以继续在终端中执行其他命令,而不必保持容器的终端打开。
docker.elastic.co/elasticsearch/elasticsearch:8.16.1: 这是要运行的 Docker 镜像。
启动成功之后:查看控制台:
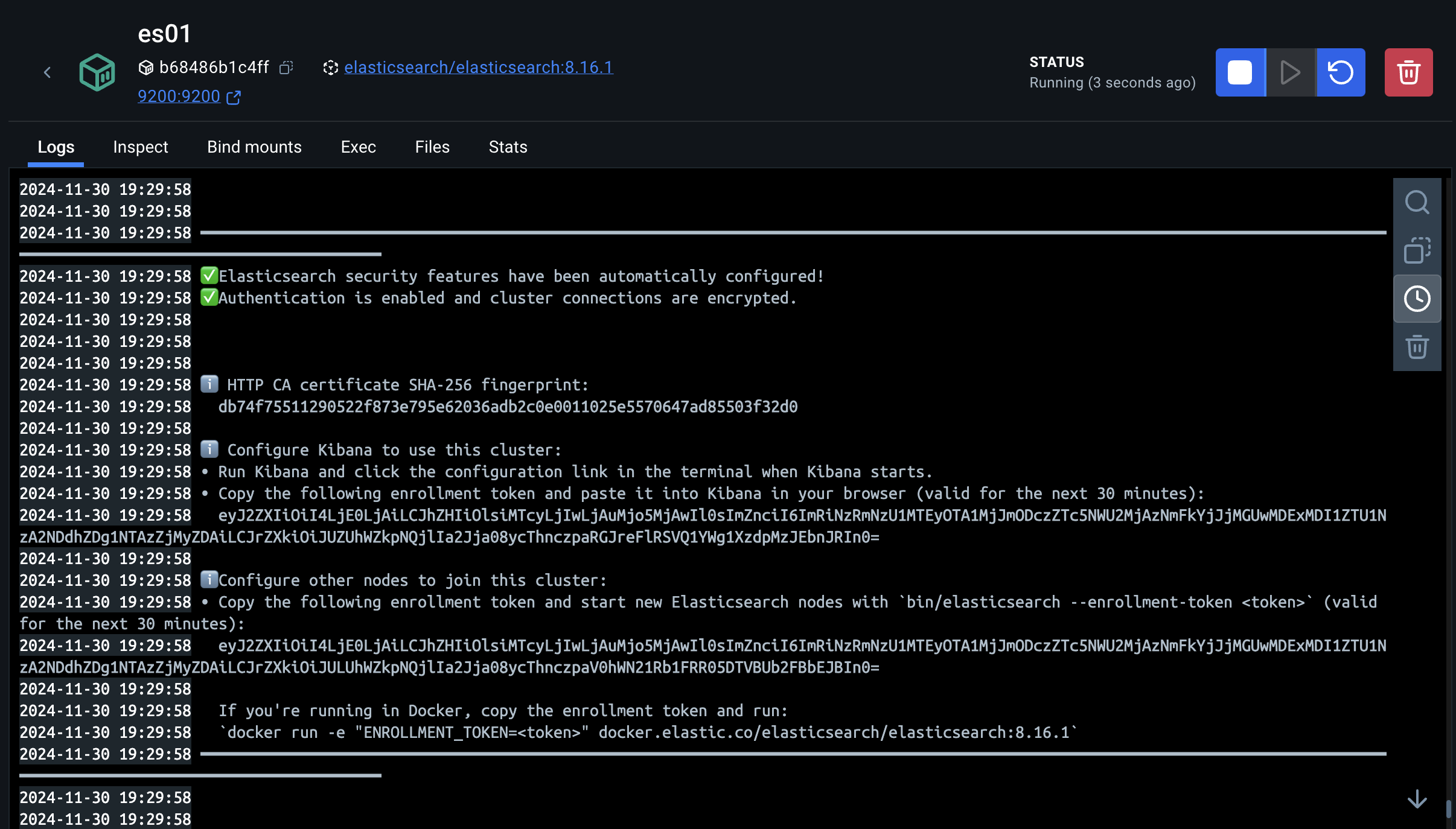
ES的最新镜像在容器内部创建了证书以及生成了一段Kibana的token,这个token可以先保存下来,或者后续自己手动生成都可以
验证
访问9200
容器启动成功之后,通过:https://localhost:9200/ (注意,这里是https)
- 从 Elasticsearch 7.x 版本开始,默认启用了安全功能,包括对 REST API 的 HTTPS 访问。这意味着默认情况下,Elasticsearch 会要求通过安全连接进行访问。
- 如果你在启动 Elasticsearch 时配置了安全设置(如设置了用户密码),Elasticsearch 会要求使用 HTTPS 进行访问。
成功访问后的内容大概长这样,也就意味着ES已经成功启动:
关闭https(可选)
如果需要关闭https,那么通过命令行进入容器内部
docker exec -it es01 /bin/bash或者通过docker desktop,或者portainer 访问,最后编辑elasticsearch的配置文件
vi /usr/share/elasticsearch/config/elasticsearch.yml将https禁用掉(不推荐)
xpack.security.enabled: false搭建kibana
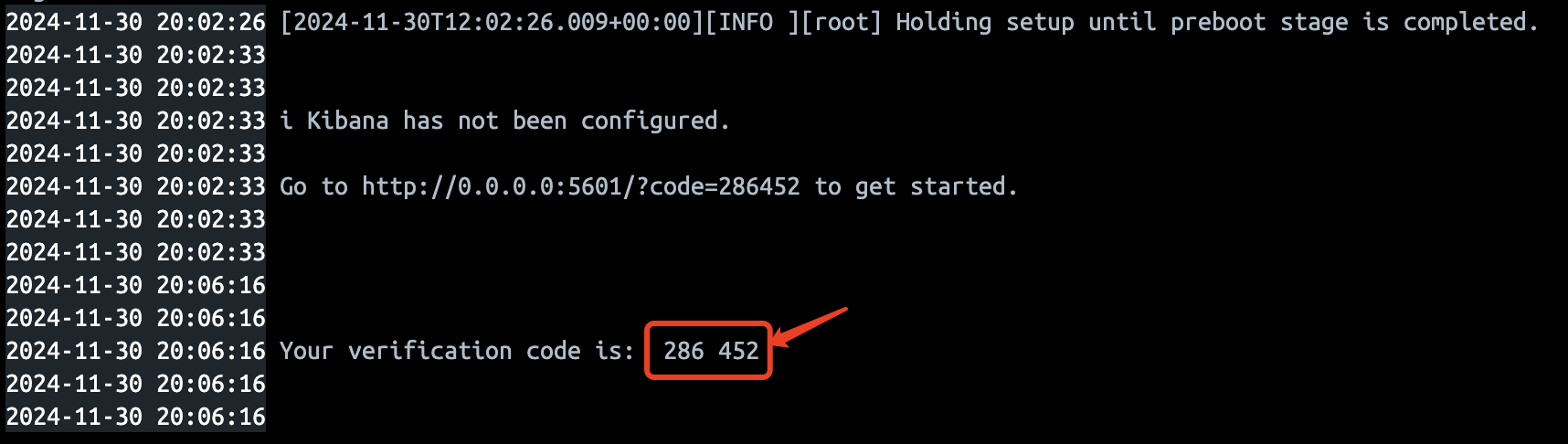
刚才在启动ES的时候,控制台日志中,ES自动为用户创建了一个token,用于和kibana的绑定,没有保存下来也无所谓,通过下面这个命令可以从ES里再拿到一个新的
docker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
启动命令
docker run --name kibana01 --net elastic -p 5601:5601 -d docker.elastic.co/kibana/kibana:8.16.1配置
启动成功之后通过http://localhost:5601/访问到kibana页面可以看到一个标题是Configure Elastic to get started 的 输入框,在这里将token输入进去
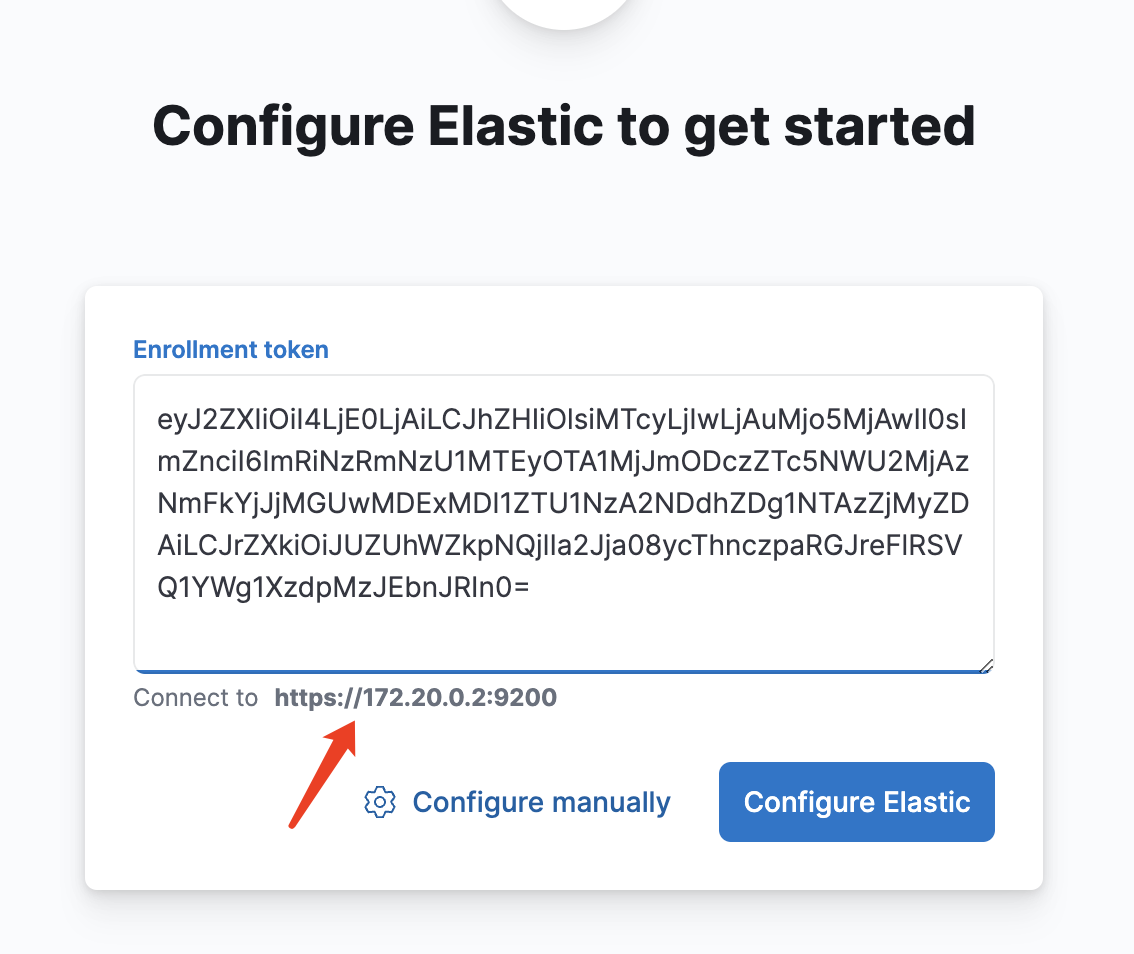
这里一定要将kibana和es设置在一个network中,可以看到上方,由于kibana和es在一个network里,所以kibana已经匹配到es的位置
如果点击提交配置,提示错误
Couldn't configure Elastic
Generate a new enrollment token or configure manually.
那么就需要再使用命令去拿一个新的
docker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
点击配置Elastic之后弹出一个框要求输入验证码
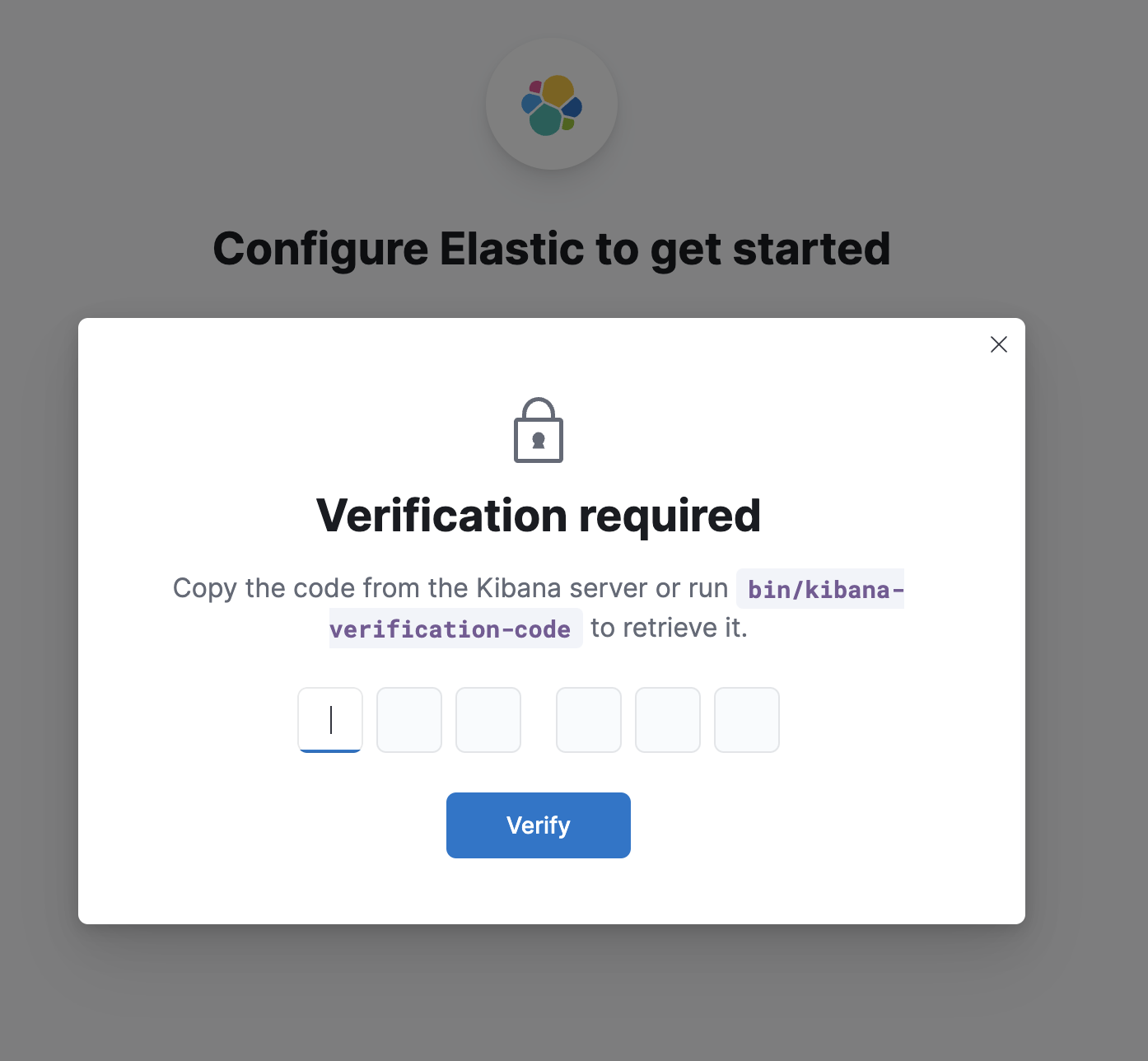
这个验证码其实在Kibana启动的时候,控制台日志中会输入一个验证码尅有拿来直接用,如果没有拿到这个验证码,根据上面的提示,进到kibana容器内部,通过bin目录下面的,kibana-verification-code再拿一个
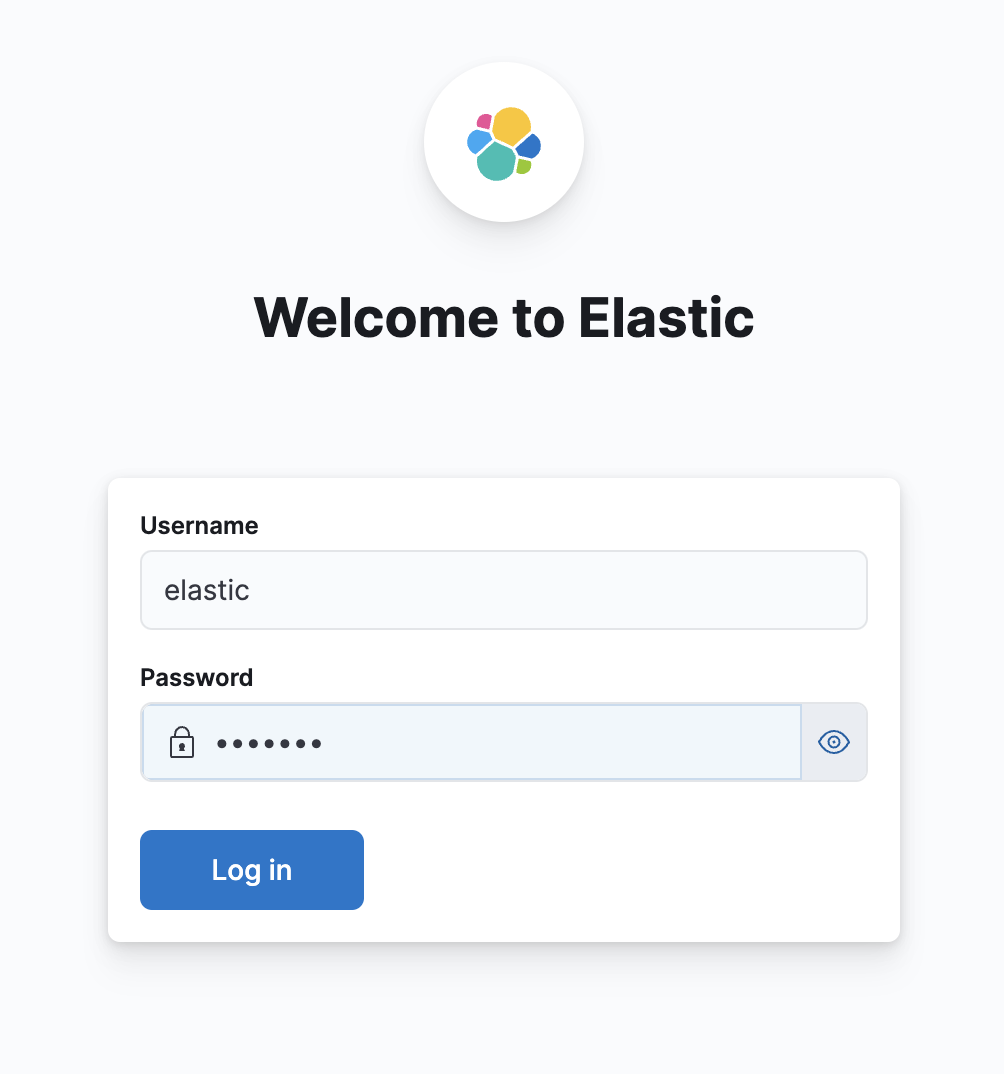
验证
配置成功后弹出用户名密码登录,这里输入安装ES时设置的用户名密码,如果按照上文中的命令启动的es,那么用户名密码都是elastic
设置中文环境
按照上文的方式进入kibana之后,kibana默认的配置中是没有国际化支持的,这个需要自己去配置,只需要加一行配置即可
命令行输入命令进入容器:
使用一下命令将容器 kibana01中的kibana.yml配置文件复制到命令行当前文件夹
docker cp kibana01:/usr/share/kibana/config/kibana.yml .打开kibana.yml文件之后在文件最下方加一行
i18n.locale: "zh-CN"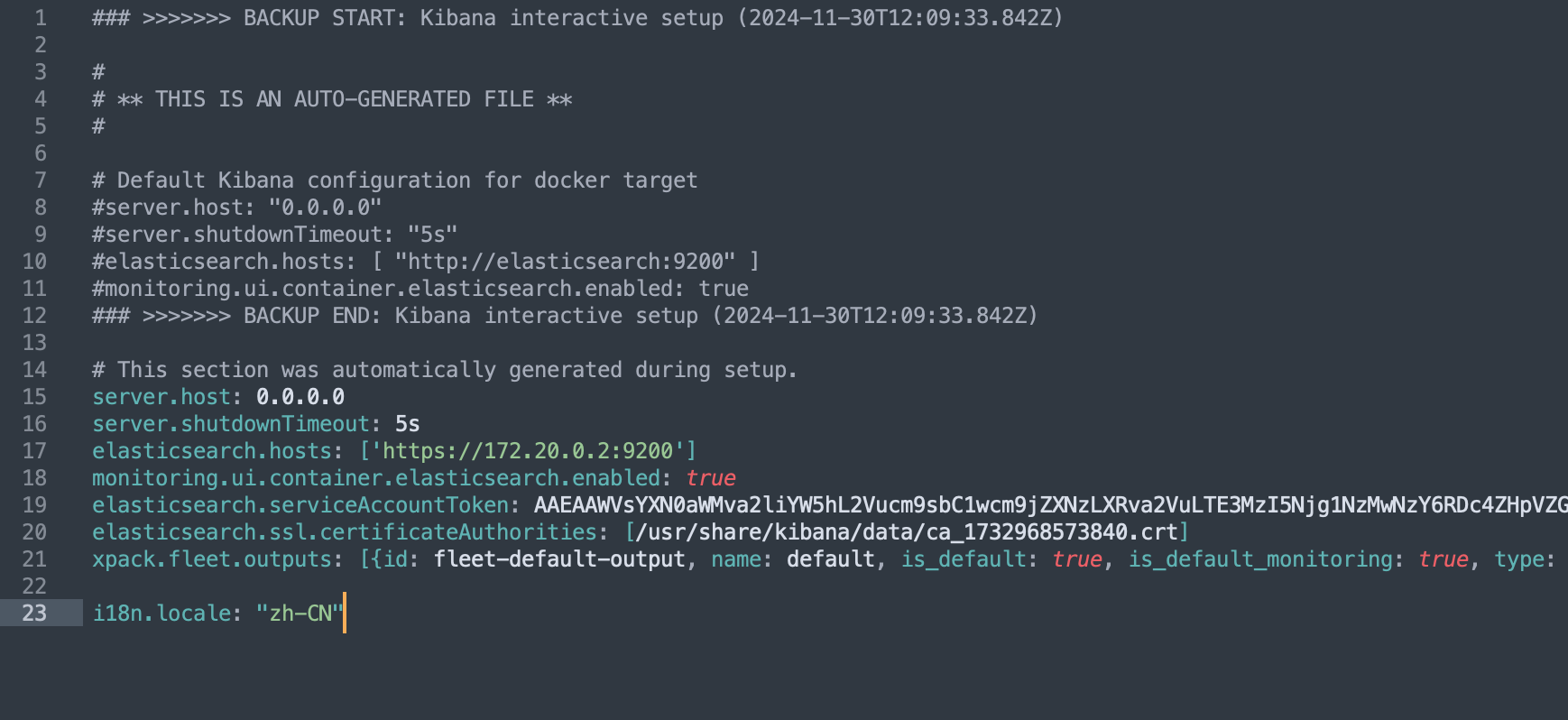
保存之后再通过命令把当前文件夹下的kibana.yml文件复制到kibana01容器中去:
docker cp kibana.yml kibana01:/usr/share/kibana/config/kibana.yml然后重启容器:
docker restart kibana01重新输入用户名密码进入界面,发现已经都变成中文了
搭建Logstash
概念
logstash最主要的功能是从input获取数据,通过filter处理,再输出到指定的地方 ,官网给出的示例图是,从DataSource中拿到数据,然后经过Logstash的处理,先是将数据input进来,然后经过各种filters过滤,然后输出到某个地方。
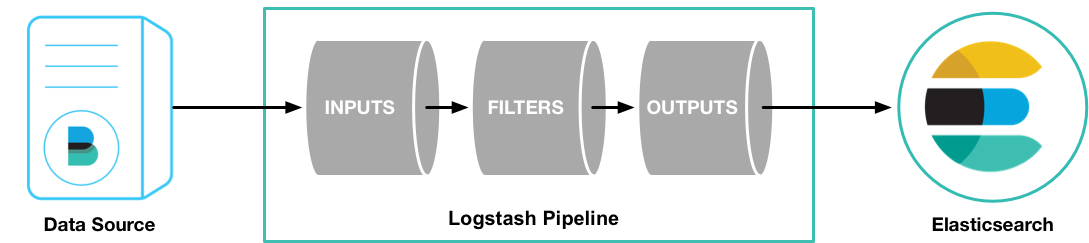
Logstash管道有两个必需的元素,输入和输出,过滤器是可选内容。
关于输入
Logstash的输入插件非常丰富,不单单是数据库,控制台,它几乎可以处理任何类型的数据输入需求。随着技术的不断发展,Logstash支持的输入源也在不断增加。
例如:用户可以直接从命令行输入数据、文件、syslog、TCP/UDP、Beats、JDBC、ES、Kafka、Redis、HTTP/HTTPS等,更多可以参阅:Input plugins | Logstash Reference [8.16] | Elastic
关于输出
Logstash 提供了多种输出插件,用于将处理后的数据发送到不同的目的地,比如ES、Redis、文件、Kafka、Email、TCP/UDP等,更多可以参阅:Output plugins | Logstash Reference [8.16] | Elastic
关于过滤器
Logstash也提供了很多输出插件,最常用的就是 Grok(用于解析和结构化非结构化日志数据),其他还有很多具体可以参阅:Filter plugins | Logstash Reference [8.16] | Elastic
启动准备
Logstash配置
Logstash有两个部分值得挂载到宿主机本地配置,一个是Config一个是pipeline,关于config部分,如果直接启动一个logstash8.x镜像,可以进入镜像看到一个默认的配置文件:/usr/share/logstash/config/logstash.yml,内容是
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]http.host: “0.0.0.0” :代表所有可用的 IPv4 地址。当你设置 Logstash 监听在这个地址上时,它可以从任何网络接口接收连接,包括局域网、公网接口等
xpack.monitoring.elasticsearch.hosts:这个配置项指定了 Logstash 应该将监控数据发送到哪个 Elasticsearch 实例,这里默认是写了一个elasticsearch:9200,但要与我们在docker中配置的es连接,其实要把它更改成我们自定义的容器名。
如果ES设置的有用户名密码,以及登录校验的配置,那么需要再在这个配置文件中,加上自己的用户名密码:
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "elastic"流水线配置
Logstash的默认流水线配置如下,可以看到一个input和一个output,这是一个简单的输入输出,但是这是结合Filebeat的一个默认配置
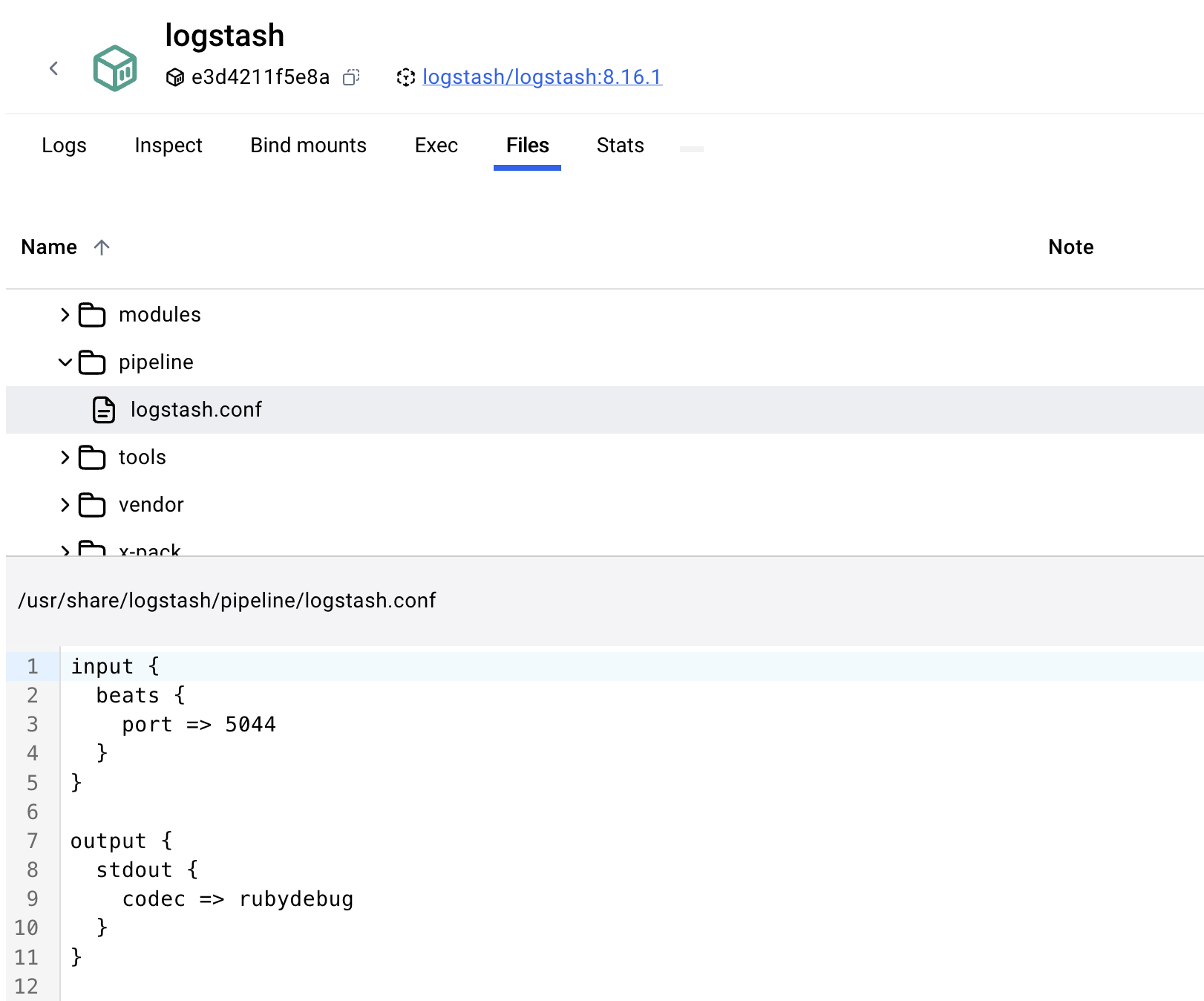
在学习使用Logstash之前先弄一个简单的流水线配置跑起来即可:
input {
generator {
count => 10
message => '{"title":"helloworld","content":["red","blud","yellow"]}'
codec => json
}
}
output {
stdout {
codec => rubydebug
}
}
-
input { }:这是 Logstash 配置文件中定义输入插件的区域。在这个大括号内,你可以指定一个或多个输入源。 -
generator:这是一个内置的输入插件,用于生成测试数据。它不会从外部源读取数据,而是根据配置生成指定数量的数据。 -
count => 10:这指定了 Logstash 应该生成多少个事件。在这个例子中,它会生成 10 个事件。 -
message => '{"title":"helloworld","content":["red","blud","yellow"]}':这是生成的事件的内容。每个事件都将包含这个 JSON 字符串。 -
codec => json:这告诉 Logstash 使用 JSON 编解码器来解析消息字段。这意味着 Logstash 会将message字段中的 JSON 字符串解析为一个 Logstash 事件。
-
output { }:这是 Logstash 配置文件中定义输出插件的区域。在这个大括号内,你可以指定一个或多个输出目标。 -
stdout { }:这里指定了stdout输出插件。这个插件允许 Logstash 将处理后的数据发送到标准输出(通常是命令行界面)。 -
codec => rubydebug:这是对stdout插件的一个配置,指定了使用rubydebug编解码器。rubydebug编解码器以人类可读的格式(通常是 JSON)输出事件数据。这意味着当你输入数据时,Logstash 不仅会输出数据,还会以格式化的 JSON 形式展示事件的所有字段,包括一些内置的字段(如@timestamp、@version和message)以及可选的host字段。
将两个文件保存好位置之后,便可以开始启动了
启动命令
docker run -it --name logstash \
--network elastic \
-v /docker/logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /docker/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml docker.elastic.co/logstash/logstash:8.16.1启动之后可以看到,控制台打印了10次 在pipeline中配置的message
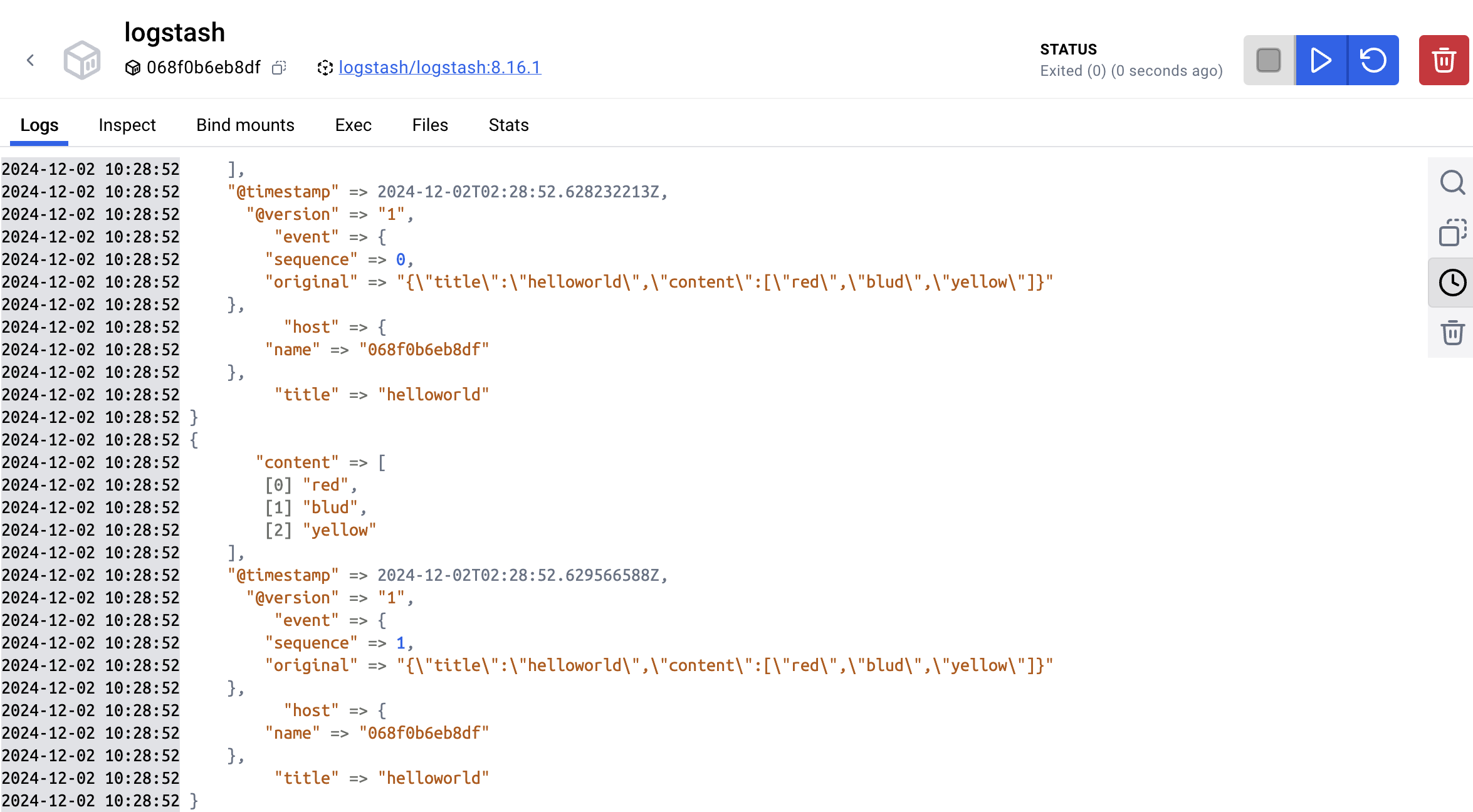
后续根据自己的业务需要去配置流水线,然后重启容器即可

















 3653
3653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









