







 本文介绍了HTTP请求的基础知识,包括请求的四部分(URL、请求方法、请求头、请求体)以及常见的HTTP响应状态码和响应头。通过学习,能够理解GET和POST方法的区别,以及如何在Python中构建HTTP请求。
本文介绍了HTTP请求的基础知识,包括请求的四部分(URL、请求方法、请求头、请求体)以及常见的HTTP响应状态码和响应头。通过学习,能够理解GET和POST方法的区别,以及如何在Python中构建HTTP请求。
近期在用python编写http请求的代码,先学习一下基础知识--http请求,写篇博客保存记录一下。
网络爬虫的第一步就是爬取网页(获取源代码),爬取网页要向web服务器发送请求构造的http请求,获得所需数据的http响应。
HTTP的基本原理
在浏览器中输入URL,按回车键或点击搜索按钮,这是浏览器向Web服务器发送一个HTTP请求,Web服务器接收到这个请求后进行解析和处理,然后返回给浏览器对应的HTTP响应,之后浏览器对HTTP响应进行解析,显示网页内容。
打开Google浏览器,按Ctrl+Shift+I,打开开发者工具,选择“网络”。在搜索框中输入https://www.baidu.com,回车后查看记录表。
进入百度网页,选择点击记录www.baidu.com选项,然后选择右侧的请求头。请求头显示对的是HTTP请求和响应的详细信息。
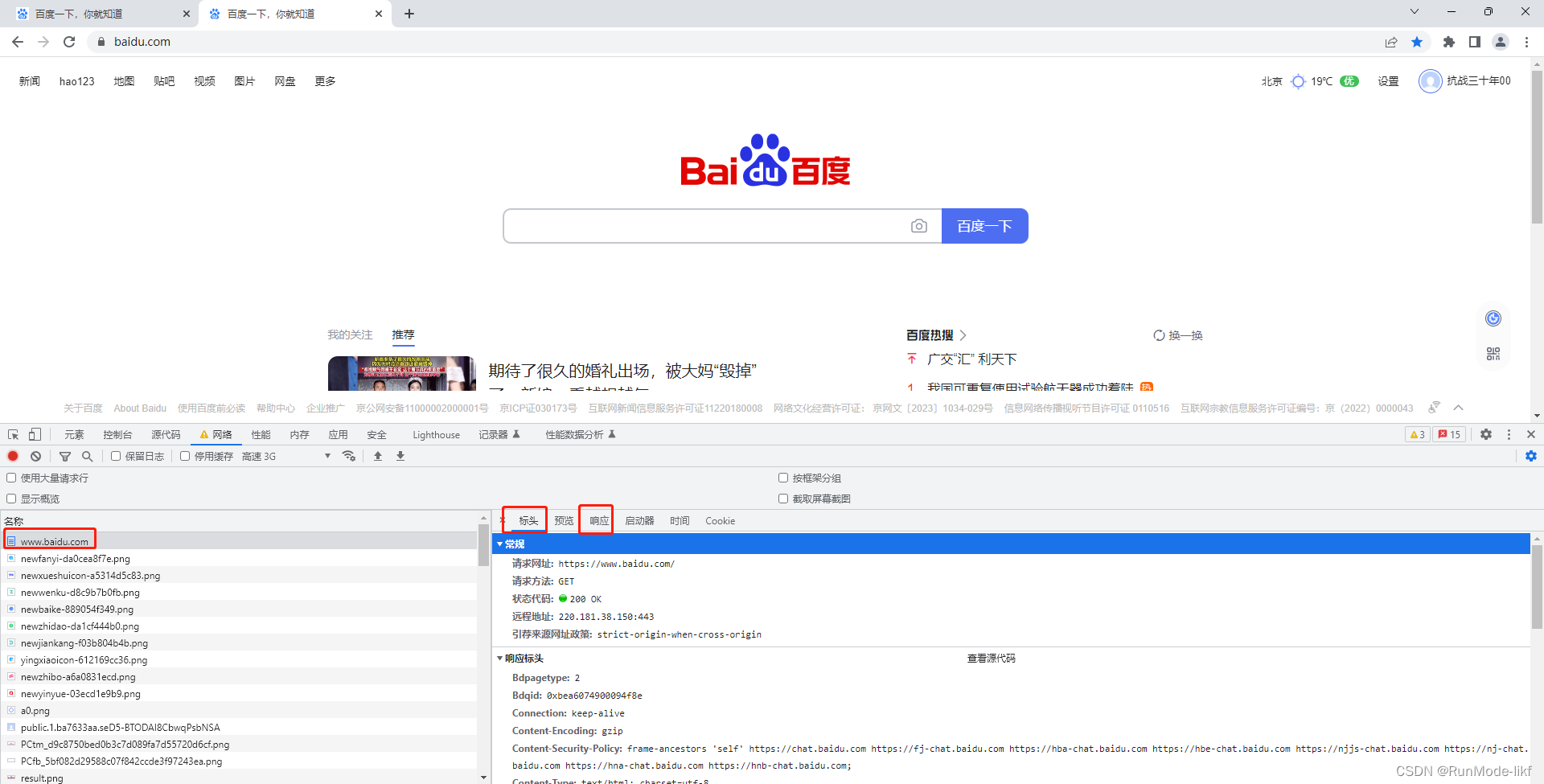
HTTP请求分为以下四部分内容:
1请求的网站(Request URL)
URL可以唯一确定请求资源。例如:https://www.baidu.com/
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









