







Python爬虫爬取ajax动态加载页面——证监会法规爬取
最近自学了一些爬虫方面的知识,正好寒假实习,老板让我把证监会的法规都爬下来,现学现用 -.-
1. 所用工具
-
python3.7
-
request库
-
re库
-
time库
-
docx库
-
webdriver(可选)
2. 网页分析
首先放上网页url:https://neris.csrc.gov.cn/falvfagui/
经过翻页我们可以发现该网站在不同页的url是相同的,判断使用了ajax(异步 JavaScript 和 XML)动态加载。
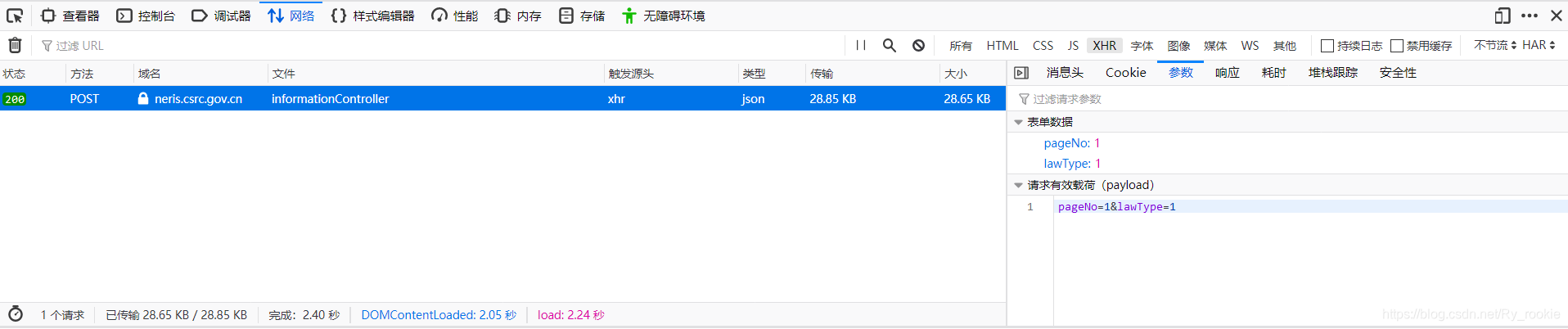
F12查看后发现采用了post方法发送了一个表单数据为{pageNo:1,lawType:1}的请求,请求网址为https://neris.csrc.gov.cn/falvfagui/rdqsHeader/informationController
点击后几页后发现规律:pageNo代表页面号,lawType永远是1,我们采用request库的post方法向该url发送请求后可以返回一个json文件。
 打开后能看到法规的基本信息。
打开后能看到法规的基本信息。
打开法规子网页,如法炮制。

也是采用了post方法,请求网址为:https://neris.csrc.gov.cn/falvfagui/rdqsHeader/lawlist,secFutrsLawId 后面的字符串就是主页json文件中的信息,打开json文件。

法规内容被写到了cntnt项中。
至此,我们大致的思路就是先通过post向主网址发送请求,解析json文件,利用正则表达式获取secFutrsLawId ,再向法规子网址post包含secFutrsLawId 的请求,解析收到的json文件,利用正则表达式找到法规内容,写入文档,大功告成~
PS:也可以使用selenium库中的webdriver中的一个函数来等待ajax页面加载完成后爬取,但因为需要启动浏览器,并且要等待页面全部加载完成,故爬取效率,不多赘述了。Wait(browser, **).until(Expect.presence_of_element_located((By.ID, "***"))) -
遇到的问题
初学爬虫,好多坑也不知道,只好跳进去再爬出来。
HTTPSConnectionPool(host=‘xxxxx’, port=443): Max retries exceeded with url:xxxxxxxx
主要是因为请求次数过多,请求没有关闭导致的。
解决方法:
1 增加重试次数
requests.adapters.DEFAULT_RETRIES = 5
2 关闭多余的连接
s = requests.sessions s.keep_alive = False
或headers={'Connection': 'close'}
OpenSSL.SSL.Error: [(‘SSL routines’, ‘tls_process_server_certificate’, ‘certificate verify failed’)]
因为该网址采用了HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer)
解决方法:
在post方法中加入参数
verify=False
再加一句requests.packages.urllib3.disable_warnings()解除安全警告
ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接
主要是因为url请求太过频繁。
解决方法:
1 连接后记得关闭
r.close()
2 sleep一段时间后再进行操
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









