







Job提交流程图解
Standalone集群模式
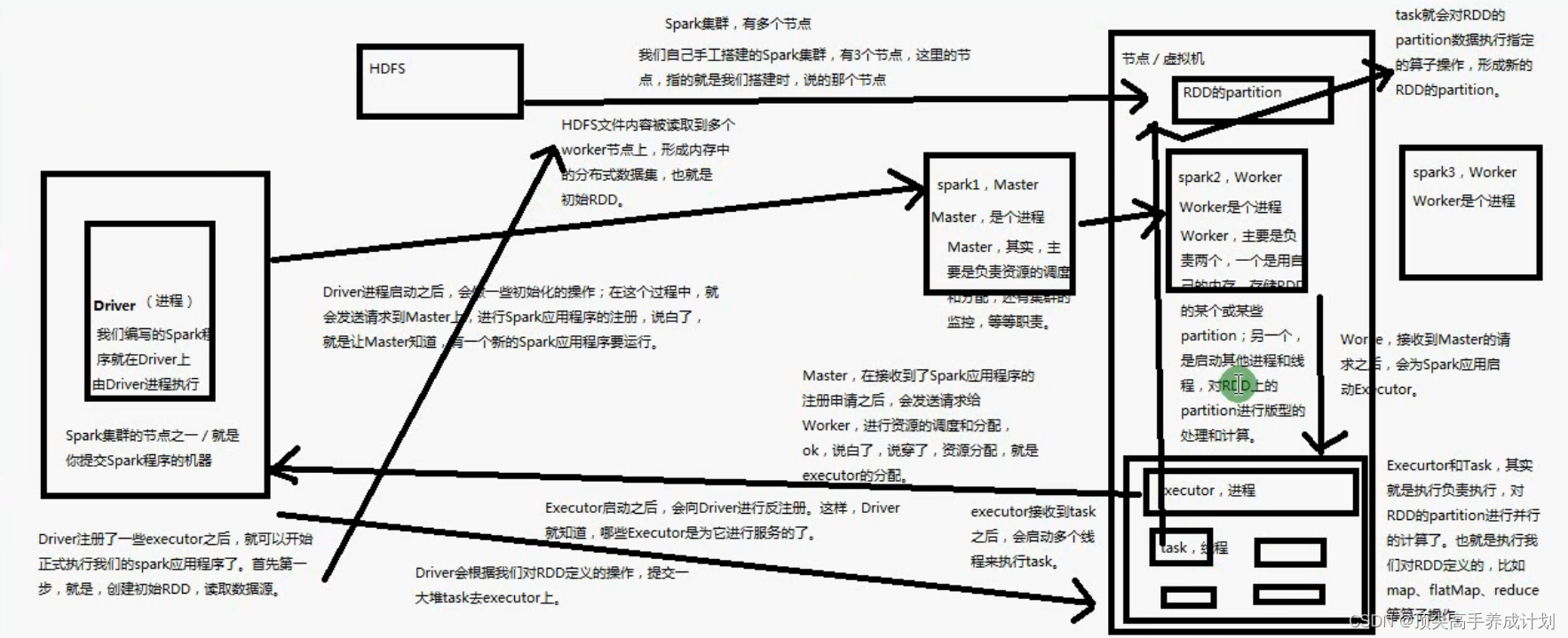
提交任务流程
- 初始化SparkContext的时候会创建一个Driver进程,并且向Master上面进行注册
- Driver注册完以后,Master开始给Executor在Work上面分配资源(每一个Work上面可以创建多个Executor进程)
- Executor分配好以后,就会向Driver注册汇报自己的情况,然后就开始在hdfs上的文件被读取到多个Work内存上面去,形成内存中的分布式数据集,也就是RDD
- 然后就是Driver对于每一个RDD的分区操作装换成一个Task给Executor执行
Yarn模式
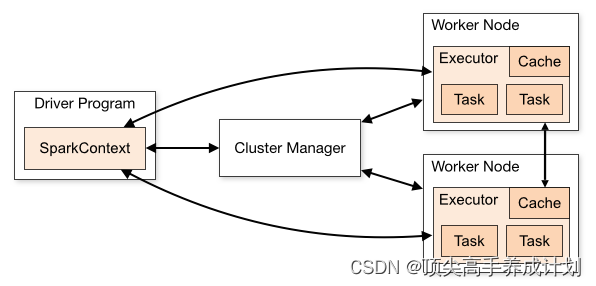
执行流程
- SparkContext执行初始化一个Driver,让后向Yarn上面申请资源,当申请到资源以后,Yarn开始为Exector申请资源
- Exector申请资源到资源向Driver进行注册
- 然后就是获取hdfs上面的文件被分布式读取到Work上面形成分布式数据集RDD
- Driver执行RDD的操作的时候就会封装成Task发送给Exector执行
RDD(弹性式数据集)详解
简介
RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性:
- 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- RDD 拥有一个用于计算分区的函数 compute;
- RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
RDD[T] 抽象类的部分相关代码如下:
// 由子类实现以计算给定分区
def compute(split: Partition, context: TaskContext): Iterator[T]
// 获取所有分区
protected def getPartitions: Array[Partition]
// 获取所有依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取优先位置列表
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 分区器 由子类重写以指定它们的分区方式
@transient val partitioner: Option[Partitioner] = None
spark core默认提供创建RDD的方式
- 通过集合创建
- 通过本地文件
- 通过hdfs
获取RDD方式
集合得到RDD
java版
public class JavaReduceSum {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local").setAppName("JavaReduceSum");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
List<Integer> target = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = javaSparkContext.parallelize(target)
.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
System.out.println(sum);
javaSparkContext.close();
}
}
scala版
object ScalaReduceSum {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaReduceSum").setMaster("local")
val sc = new SparkContext(conf)
val target: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 5)
val sum: Int = target.reduce(_ + _)
println(sum)
}
}
parallelize后面设置分区数量,官方建议partition为core的2~4倍
本地文件的方式
java版
public class JavaTextLength {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaTextLength");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> lineTextString = javaSparkContext.textFile("data");
Integer textLength = lineTextString.map(new Function<String, Integer>() {
@Override
public Integer call(String text) throws Exception {
return text.length();
}
}).reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
System.out.println(textLength);
javaSparkContext.close();
}
}
scala版
object ScalaTextLength {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaTextLength").setMaster("local")
val sc = new SparkContext(conf)
val target: Int = sc.textFile("data")
.map(_.length).reduce(_ + _)
println(target)
}
}
打包提交到集群(打包maven插件在阶段一提供了)
object ScalaTextLength {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaTextLength")
val sc = new SparkContext(conf)
val target: Int = sc.textFile("hdfs://hadoop102:8020/data.txt")
.map(_.length).reduce(_ + _)
println(target)
}
}
注意:
提交到集群要保证每一个work上面都有这个文件才行
bin/spark-submit \
--class com.zhang.one.scala.ScalaTextLength \
--master yarn \
/home/bigdata/module/spark-3.0.0-bin-hadoop3.2/original-sparkstart-1.0-SNAPSHOT.jar
1、SparkContext.wholeTextFiles方法,可以针对一个目录中的大量小文件,返回
<filename,fileContent>组成的pair,作为一个PairRDD,而不是普通的RDD。普通的
textFile(O返回的RDD中,每个元素就是文件中的一行文本:
2、SparkContext.sequenceFile[K,VI)方法,可以针对SequenceFile创建RDD,K和V泛型
类型就是SequenceFile的key和value的类型。K和V要求必须是Hadoop的序列化类型,比如
IntWritable、Text等.
3、SparkContext.hadoopRDD方法,对于Hadoop的自定义输入类型,可以创建RDD。该
方法接收JobConf、InputFormatClass、Key和Value的Class..
4、SparkContext.objectFile方法,可以针对之前调用RDD.saveAsObjectFile(0创建的对象
序列化的文件,反序列化文件中的数据,并创建一个RDD.
transformation和action原理图解
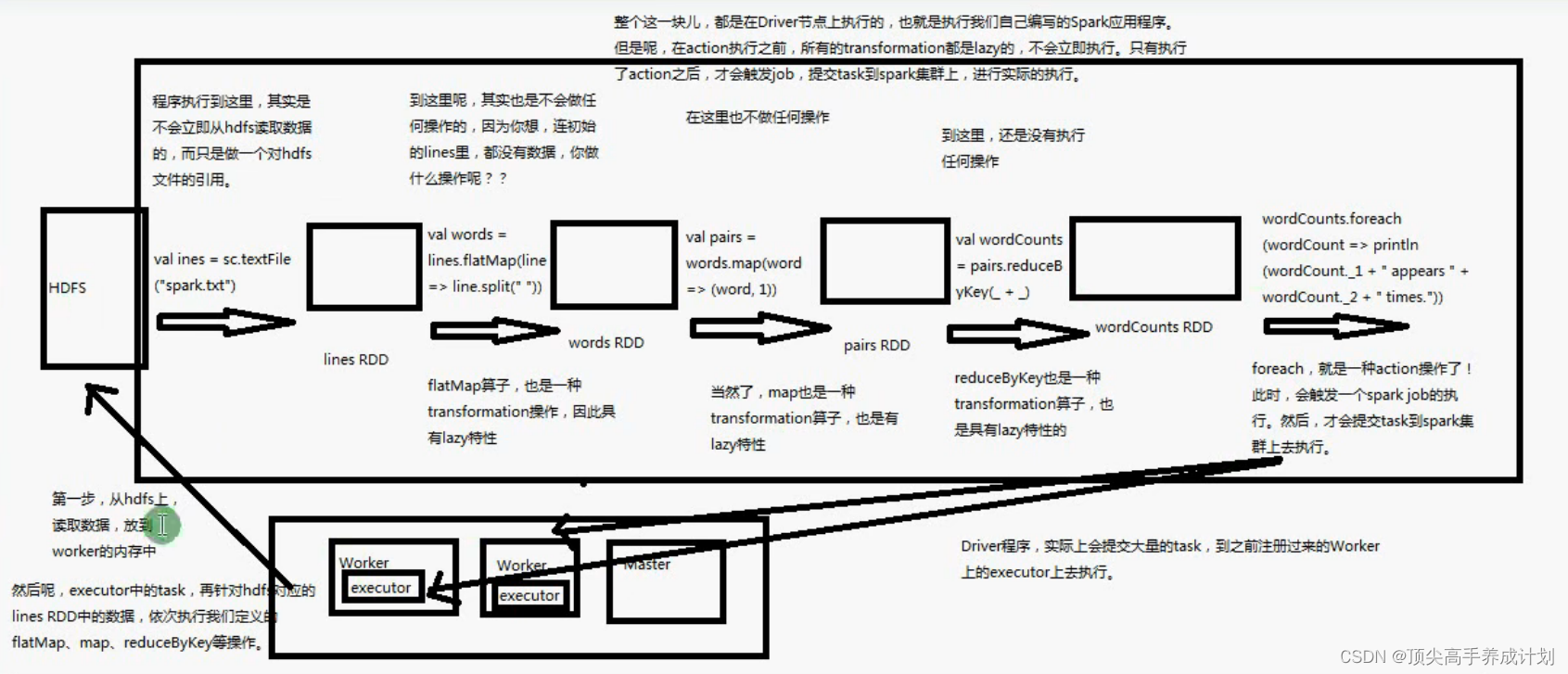
- transformationo是RDD一系列的装换操作,它们的调用都是lazy的,只有调用了action的时候才会真正的提交了一个spark job
- 在Driver和Exector建立好联系以后,执行一个action操作这个时候就会根据要求去hdfs分布式读取文件到Work节点,形成RDD,然后根据 transformation和action封装成Task交给Executor执行
案例巩固
统计文本每一行出现的次数
hello spark
hello java
hello spark
java版本
public class JavaTextLineCount {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaTextLineCount");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> lineText = javaSparkContext.textFile("data");
//mapToPair是一个装换成key,value的transformation
JavaPairRDD<String, Integer> mapText = lineText.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String line) throws Exception {
return new Tuple2<>(line,1);
}
});
//对key,value执行shuffle分组求和,reduceByKey有一个预聚合的功能
JavaPairRDD<String, Integer> reduceLineCount = mapText.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
//执行action操作
reduceLineCount.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> result) throws Exception {
System.out.println("("+result._1+" ,"+result._2+")");
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaTextLineCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaTextLineCount")
.setMaster("local")
val sc = new SparkContext(conf)
sc.textFile("data")
.map((_,1)).reduceByKey(_+_).foreach(println)
sc.stop()
}
}
常用的transformation操作
map
java版本
public class JavaMap {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaMap");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//从集合中得到RDD
JavaRDD<Integer> numRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
//第一个参数是原始的值,第二个参数是要输出的值
//call方法调用以后就是最终要得到的值
//比如这里输入了1,2,3通过map以后就是2,4,6
JavaRDD<Integer> numMapRDD = numRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer num) throws Exception {
return num * 2;
}
});
numMapRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaMap")
val sc = new SparkContext(conf)
val numRDD: RDD[Int] = sc.parallelize(Array(1, 2, 3))
numRDD.map(_*2).foreach(println)
sc.stop()
}
}
filter
java版本
public class JavaFilter {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaFilter");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> numRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
//call函数的调用符合要求的就是返回true,不要的就是false
//这里输入了1,2,3那么输出就是2满足要求
JavaRDD<Integer> evenNumRDD = numRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer targetNum) throws Exception {
return targetNum % 2 == 0;
}
});
evenNumRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer result) throws Exception {
System.out.println(result);
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaFilter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaFilter")
val sc = new SparkContext(conf)
val numRDD: RDD[Int] = sc.parallelize(Array(1, 2, 3))
numRDD.filter(_%2==0).foreach(println)
sc.stop()
}
}
flatmap
java版本
public class JavaFlatMap {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaFlatMap");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> lineTextRDD = javaSparkContext.parallelize(Arrays.asList("hello spark", "hello java"));
//FlatMapFunction第一个参数是传入的参数,第二个是返回的参数类型
//call方法的调用的作用是比如传入hello spark->Iterator<String>("hello","spark")
//意思就是输入一个值,得到处理这个值得一个迭代器集合
JavaRDD<String> flatMapRDD = lineTextRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//执行action
flatMapRDD.foreach(new VoidFunction<String>() {
@Override
public void call(String result) throws Exception {
System.out.println(result);
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaFlatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaFlatMap")
.setMaster("local")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.parallelize(Array("hello spark", "hello java"))
lineRDD.flatMap(_.split(" ")).foreach(println)
sc.stop()
}
}
groupBykey
java版本
public class JavaGroupByKey {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaGroupByKey");
//模拟每一个学生的成绩
List<Tuple2<String, Integer>> target = Arrays.asList(
new Tuple2<String, Integer>("stu1", 100),
new Tuple2<String, Integer>("stu2", 90),
new Tuple2<String, Integer>("stu1", 80),
new Tuple2<String, Integer>("stu2", 78)
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//根据元组类型得到并行的RDD
JavaPairRDD<String, Integer> tupleRDD = javaSparkContext.parallelizePairs(target);
//把key相同的数据放在一个集合里面去
//比如<stu1,(100,80)>
JavaPairRDD<String, Iterable<Integer>> groupResult = tupleRDD.groupByKey();
groupResult.foreach(new VoidFunction<Tuple2<String, Iterable<Integer>>>() {
@Override
public void call(Tuple2<String, Iterable<Integer>> result) throws Exception {
System.out.println("========"+result._1+"========");
Iterator<Integer> resultIter = result._2.iterator();
while (resultIter.hasNext()){
System.out.println(resultIter.next());
}
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaGroupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaGroupByKey")
.setMaster("local")
var target=Array(
("stu1",100),
("stu2",90),
("stu1",80),
("stu2",78),
)
val sc = new SparkContext(conf)
sc.parallelize(target)
.groupBy(_._1)
.foreach(
item=>{
println("====="+item._1+"=========")
item._2.foreach(println)
}
)
sc.stop()
}
}
reduceByKey
java版本
public class JavaReduceByKey {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaGroupByKey");
//模拟每一个学生的成绩
List<Tuple2<String, Integer>> target = Arrays.asList(
new Tuple2<String, Integer>("stu1", 100),
new Tuple2<String, Integer>("stu2", 90),
new Tuple2<String, Integer>("stu1", 80),
new Tuple2<String, Integer>("stu2", 78)
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//根据元组类型得到并行的RDD
JavaPairRDD<String, Integer> tupleRDD = javaSparkContext.parallelizePairs(target);
//Function2第一个参数一第一个值,第二个类型是第二个累加的值,第三个是返回值得类型
//call传入的是,由于reduceByKey是把key相同的数据进行了分组处理,num1就是上一次的累加和值,num2是
//要累加值,要返回的就是处理后的值,也就是下一次计算的num1,就像滚雪球的场景
JavaPairRDD<String, Integer> reduceRDD = tupleRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
reduceRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> result) throws Exception {
System.out.println(result._1+": "+result._2);
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaGroupByKey")
.setMaster("local")
var target=Array(
("stu1",100),
("stu2",90),
("stu1",80),
("stu2",78),
)
val sc = new SparkContext(conf)
sc.parallelize(target)
.reduceByKey(_+_).foreach(
item=>{
println(item._1+": "+item._2)
}
)
sc.stop()
}
}
sortByKey
java版本
public class JavaSortByKey {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("JavaSortByKey")
.setMaster("local");
List<Tuple2<Integer, String>> target = Arrays.asList(
new Tuple2<Integer, String>(100, "tom"),
new Tuple2<Integer, String>(90, "zhangsan"),
new Tuple2<Integer, String>(200, "lisi"),
new Tuple2<Integer, String>(10, "wanwu")
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<Integer, String> targetRDD = javaSparkContext.parallelizePairs(target);
//根据tuple的key进行排序,默认是升序排序,如果参数为false那么就是降序排序
//比如上面得到的数据就是
//(200,lisi)
//(100,tom)
//(90,zhangsan)
//(10,wanwu)
JavaPairRDD<Integer, String> sortRDD = targetRDD.sortByKey(false);
sortRDD.foreach(new VoidFunction<Tuple2<Integer, String>>() {
@Override
public void call(Tuple2<Integer, String> result) throws Exception {
System.out.println("("+result._1+","+result._2+")");
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaSortByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaSortByKey")
val targetData: Array[(Int, String)] = Array(
(100, "tom"),
(90, "zhangsan"),
(200, "lisi"),
(10, "wanwu")
)
val sc = new SparkContext(conf)
sc.parallelize(targetData)
.sortByKey()
.foreach(println)
sc.stop()
}
}
join
java版本
public class JavaJoin {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaJoin");
List<Tuple2<Integer, String>> stuInfo = Arrays.asList(
new Tuple2<Integer, String>(1, "zhangsan"),
new Tuple2<Integer, String>(2, "lisi"),
new Tuple2<Integer, String>(3, "wanwu")
);
List<Tuple2<Integer, Integer>> soreInfo = Arrays.asList(
new Tuple2<Integer, Integer>(1, 90),
new Tuple2<Integer, Integer>(1, 10),
new Tuple2<Integer, Integer>(2, 20),
new Tuple2<Integer, Integer>(3, 100)
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//得到学生的RDD
JavaPairRDD<Integer, String> stuRDD = javaSparkContext.parallelizePairs(stuInfo);
//得到分数的RDD
JavaPairRDD<Integer, Integer> soreRDD = javaSparkContext.parallelizePairs(soreInfo);
//join操作比如这个例子就是stuRDD里面的元素迭代的就是从上到下一条一条的去匹配soreRDD
//如果匹配到了就连接得到一个以它们相同的key,值是它们分别的值作为结果返回
//比如上面的例子返回的结果
//(1,(zhangsan,90)
//(1,(zhangsan,10)
//(3,(wanwu,100)
//(2,(lisi,20)
JavaPairRDD<Integer, Tuple2<String, Integer>> resultRDD = stuRDD.join(soreRDD);
resultRDD.foreach(new VoidFunction<Tuple2<Integer, Tuple2<String, Integer>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> result) throws Exception {
System.out.println("("+result._1+","+"("+result._2._1 + ","+result._2._2+")");
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaJoin")
.setMaster("local")
val stuInfo: Array[(Int, String)] = Array(
(1, "zhangsan"),
(2, "lisi"),
(3, "wanwu")
)
val soreInfo= Array(
(1,90),
(1,80),
(2,90),
(3,90)
)
val sc = new SparkContext(conf)
val stuRDD: RDD[(Int, String)] = sc.parallelize(stuInfo)
val scoreRDD: RDD[(Int, Int)] = sc.parallelize(soreInfo)
stuRDD.join(scoreRDD)
.foreach(println)
sc.stop()
}
}
cogroup
java版本
public class JavaCoGroup {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaJoin");
List<Tuple2<Integer, String>> stuInfo = Arrays.asList(
new Tuple2<Integer, String>(1, "zhangsan"),
new Tuple2<Integer, String>(1, "lisi"),
new Tuple2<Integer, String>(3, "wanwu")
);
List<Tuple2<Integer, Integer>> soreInfo = Arrays.asList(
new Tuple2<Integer, Integer>(1, 90),
new Tuple2<Integer, Integer>(1, 10),
new Tuple2<Integer, Integer>(2, 20),
new Tuple2<Integer, Integer>(3, 100)
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//得到学生的RDD
JavaPairRDD<Integer, String> stuRDD = javaSparkContext.parallelizePairs(stuInfo);
//得到分数的RDD
JavaPairRDD<Integer, Integer> soreRDD = javaSparkContext.parallelizePairs(soreInfo);
//cogroupRDD的作用就是把key相同的RDD连接在一块,得到的结果就是key是连接的key
//value是一个Tuple2,value中的Tuple2._1是第一个RDD里面相同key的所有元素的集合,Tuple2._2是第二个RDD所有相同key的集合
//如有有一半没有那么就是为空的集合
//例如上面的例子输出
//(1,([[zhangsan, lisi]],[[90, 10]])
//(3,([[wanwu]],[[100]])
//(2,([[]],[[20]])
JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> cogroupRDD = stuRDD.cogroup(soreRDD);
cogroupRDD.foreach(new VoidFunction<Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> result) throws Exception {
System.out.println("("+result._1+","+"("+Arrays.asList(result._2._1)+","+Arrays.asList(result._2._2)+")");
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaCoGroup {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaJoin")
.setMaster("local")
val stuInfo: Array[(Int, String)] = Array(
(1, "zhangsan"),
(1, "lisi"),
(3, "wanwu")
)
val soreInfo= Array(
(1,90),
(1,80),
(2,90),
(3,90)
)
val sc = new SparkContext(conf)
val stuRDD: RDD[(Int, String)] = sc.parallelize(stuInfo)
val scoreRDD: RDD[(Int, Int)] = sc.parallelize(soreInfo)
//返回
//(1,(CompactBuffer(zhangsan, lisi),CompactBuffer(90, 80)))
//(3,(CompactBuffer(wanwu),CompactBuffer(90)))
//(2,(CompactBuffer(),CompactBuffer(90)))
stuRDD.cogroup(scoreRDD)
.foreach(println)
sc.stop()
}
}
常用的action操作
reduce
java版本
public class JavaReduce {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaReduce");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> initDataRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
Integer result = initDataRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
System.out.println(result);
javaSparkContext.close();
}
}
scala版本
object ScalaReduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaReduce")
val sc = new SparkContext(conf)
val result: Int = sc.parallelize(Array(1, 2, 3))
.reduce(_ + _)
println(result)
sc.stop()
}
}
collect
scala版本
object ScalaReduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaReduce")
val sc = new SparkContext(conf)
//使用collect是把数据收集到Driver上面得到结果,如果数据量太大很容易出现OOM
//所以推荐直接使用foreach,它是在每一个work上面运行
// sc.parallelize(Array(1, 2, 3))
// .foreach(println)
sc.parallelize(Array(1, 2, 3))
.collect().foreach(println)
sc.stop()
}
}
count
java版本
public class JavaCount {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaCount");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> initDataRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
//得到RDD里面元素的个数
long result = initDataRDD.count();
System.out.println(result);
javaSparkContext.close();
}
}
scala版本
object ScalaCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaCount")
.setMaster("local")
val sc = new SparkContext(conf)
val result: Long = sc.parallelize(Array(1, 2, 4))
.count()
println(result)
sc.stop()
}
}
take
java版本
public class JavaTake {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("JavaTake")
.setMaster("local");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> initDataRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5));
List<Integer> take = initDataRDD.take(2);
//他的作用和collect差不多,都是把所有的RDD的数据拿过来
//但是,take只是获取前面几条
for (Integer integer : take) {
System.out.println(integer);
}
javaSparkContext.close();
}
}
scala版本
object ScalaTask {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaTask")
val sc = new SparkContext(conf)
sc.parallelize(Array(1,2,3,4,5))
.take(2)
.foreach(println)
sc.stop()
}
}
saveAsTextFile
java版本
public class JavaSaveAsTextFile {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaSaveAsTextFile");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> initData = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6));
//保存的路径为一个文件夹
initData.saveAsTextFile("output");
sparkContext.close();
}
}
scala版本
object ScalaSaveAsTextFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaTask")
val sc = new SparkContext(conf)
sc.parallelize(Array(1,2,3,4,5))
.saveAsTextFile("output")
sc.stop()
}
}
countByKey
java版本
public class JavaCountByKey {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaCountByKey");
List<Tuple2<Integer, Integer>> soreInfo = Arrays.asList(
new Tuple2<Integer, Integer>(1, 90),
new Tuple2<Integer, Integer>(1, 10),
new Tuple2<Integer, Integer>(2, 20),
new Tuple2<Integer, Integer>(3, 100)
);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<Integer, Integer> initDataRDD = javaSparkContext.parallelizePairs(soreInfo);
//对于key相同的进行分组求和,得到一个map结果
Map<Integer, Long> result = initDataRDD.countByKey();
for (Map.Entry<Integer, Long> item : result.entrySet()) {
System.out.println(item.getKey()+":"+item.getValue());
}
javaSparkContext.close();
}
}
foreach
上面写过挺多次了,它就是遍历RDD里面的元素,不过它是在远程执行的
RDD持久化
首先不使用RDD会有什么问题?
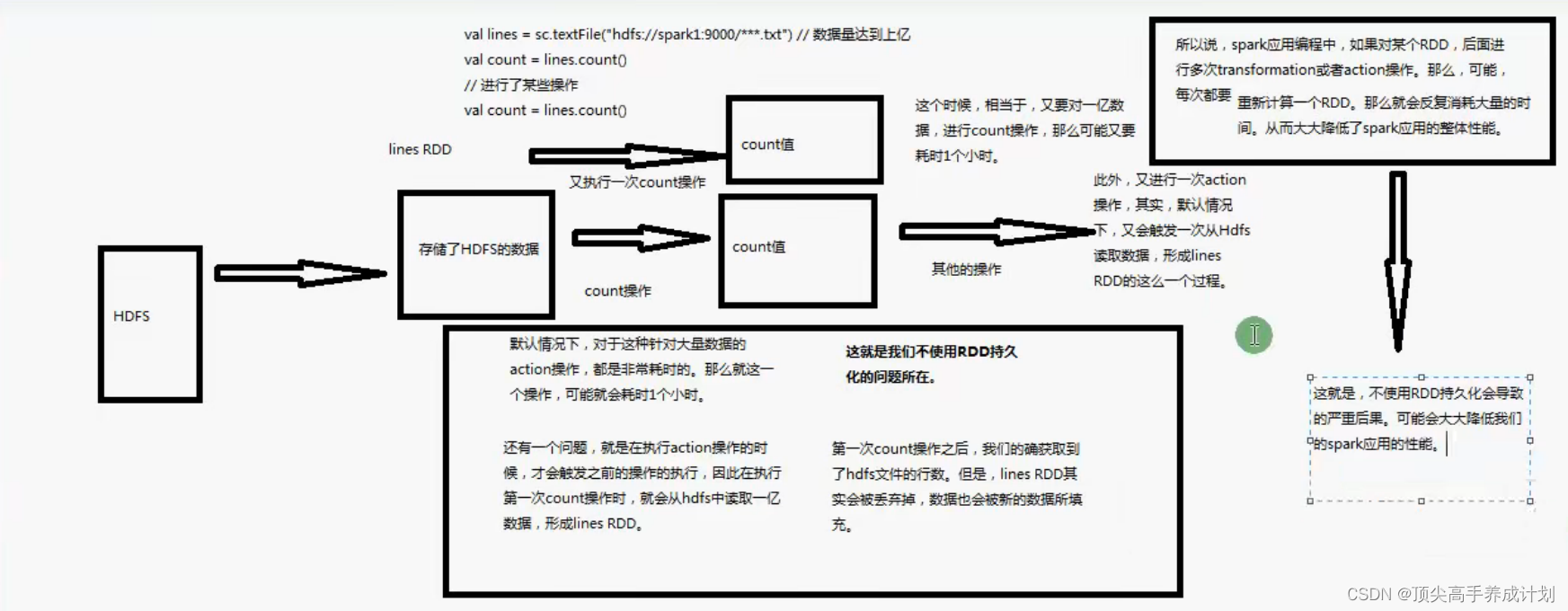
如果,如果在计算复杂的算子并且会在后面重复利用的时候如果不使用持久化,那么他就会重新的去进行计算
使用持久化功能以后
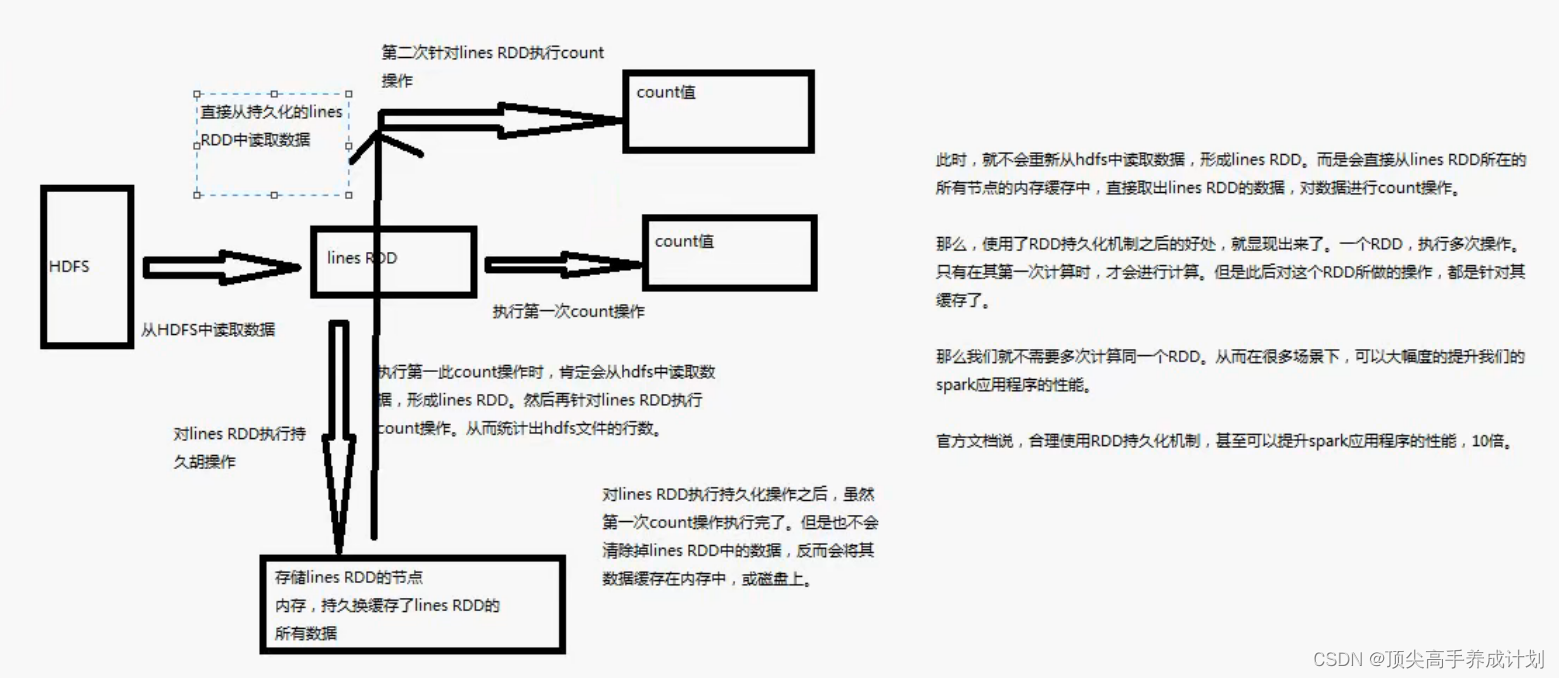
例子
object ScalaCache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaCount")
.setMaster("local")
val sc = new SparkContext(conf)
val initDataRDD: RDD[String] = sc.textFile("C:\\Users\\zhang\\Desktop\\sparkstart\\src\\main\\java\\com\\zhang\\one\\scala")
//在transformation后面或者textFile后面加上cache就会在内存中进行持久化
initDataRDD.cache();
val currentTime: Long = System.currentTimeMillis()
val l: Long = initDataRDD.count()
val endTime: Long = System.currentTimeMillis()
println("resultTime: "+(endTime-currentTime).toString)
val currentTime1: Long = System.currentTimeMillis()
val l1: Long = initDataRDD.count()
val endTime1: Long = System.currentTimeMillis()
println("resultTime: "+(endTime1-currentTime1).toString)
sc.stop()
}
}
- cache地城调用的是persist(StorageLevel.MEMORY_ONLY)持久化到内存
- 在shuffle过程中RDD也是会自动持久化,为了避免重新计算
StorageLevel
-
MEMORY_ONLY持久化在jvm内存里面
-
MEMORY_AND_DISK当内存存不下的时候会存储到磁盘
-
MEMORY_AND_DISK_SER可以对java对象序列化之后持久化
-
DISK_ONLY存储在磁盘上面
-
MEMORY_ONLY_2 后面有一个2的就是复制一份到其他的节点起到容错的作用
广播变量
- 它是给每一个节点拷贝一份数据,不是给每一个task拷贝一份数据(为了节约网络开销,提升性能)
- 它是只读的属性
图解广播变量
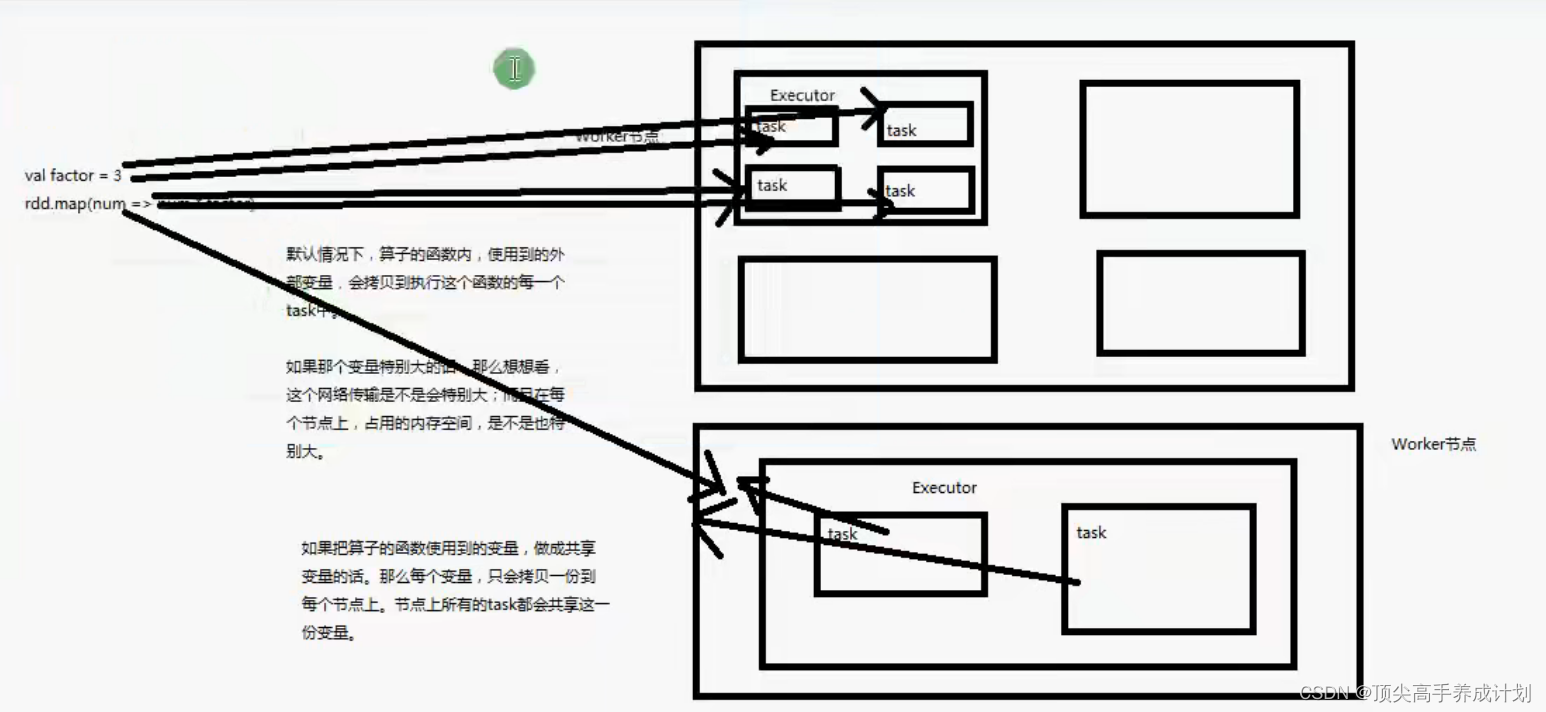
使用例子
java版本
public class JavaBroadVariable {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaBroadVariable");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<Integer> initDataRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
final Integer factor=2;
//声明广播变量,传入你要广播的是数据,然后返回Broadcast<T>
Broadcast<Integer> integerBroadcast = javaSparkContext.broadcast(factor);
JavaRDD<Integer> result = initDataRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer num) throws Exception {
//获取广播变量
Integer value = integerBroadcast.value();
return num * value;
}
});
result.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer item) throws Exception {
System.out.println(item);
}
});
javaSparkContext.close();
}
}
scala版本
object ScalaBroadVariable {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaBroadVariable")
.setMaster("local")
val sc = new SparkContext(conf)
val initDataRDD: RDD[Int] = sc.parallelize(Array(1, 2, 3))
val factor=2;
//声明广播变量
val broadCastFactor: Broadcast[Int] = sc.broadcast(factor)
initDataRDD.map(
item=>{
//使用广播变量
val bfactor: Int = broadCastFactor.value
bfactor*item
}
).foreach(println)
sc.stop()
}
}
Accumulator(累加变量&共享变量)
java版本例子
public class JavaAccumulator {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaAccumulator");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//声明一个共享变量
LongAccumulator javaAccumulator = javaSparkContext.sc().longAccumulator();
JavaRDD<Integer> initDataRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3));
initDataRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num1) throws Exception {
//累加变量使用
javaAccumulator.add(num1);
}
});
//读取到值
System.out.println(javaAccumulator.value());
}
}
scala版本
object ScalaAccumulator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaAccumulator")
val sc = new SparkContext(conf)
//声明累加变量
val acc: LongAccumulator = sc.longAccumulator
val initDataRDD: RDD[Int] = sc.parallelize(Array(1, 2, 3))
initDataRDD.foreach(
item=>{
//使用
acc.add(item)
}
)
//获取值
println(acc.value)
}
}
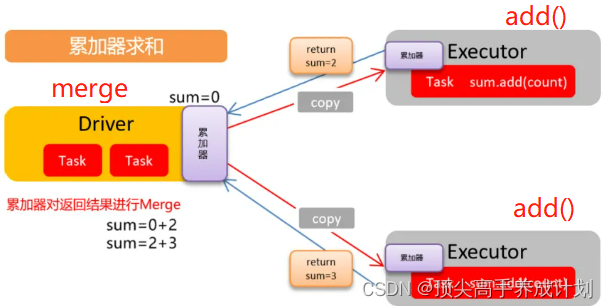
图解
先自定义一个累加器
object ScalaAccumulatorV2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaAccumulatorV2")
val sc = new SparkContext(conf)
// sc.longAccumulator()
val initDataRDD: RDD[Int] = sc.parallelize(Array(1, 2, 3))
val acc = new MyAcc
sc.register(acc,"myacc")
initDataRDD.foreach(
item=>{
acc.add(item)
}
)
println(acc.value)
sc.stop()
}
}
//自定义一个累加器
class MyAcc extends AccumulatorV2[Long,Long]{
//这个变量是每一个task里面都有
private var result:Long=0;
//设置判断是为空的条件,意思就是怎么表名它是为空
override def isZero: Boolean = result==0
//复制这个对象
override def copy(): AccumulatorV2[Long, Long] = new MyAcc
//重制变量
override def reset(): Unit = result=0
//累加操作
override def add(v: Long): Unit = {
result=result+v
}
override def merge(other: AccumulatorV2[Long, Long]): Unit = {
val otherAcc: Long = other.value
result=result+otherAcc
}
//得到最后的值
override def value: Long = result
}
上面的程序如下图
自定义key实现二次排序
java版本
准备数据(结果要求如果第一个数字相同那么就比较第二个)
1 5
2 4
3 6
1 3
2 1
自定义排序key
public class MyOrderKey implements Ordered<MyOrderKey> , Serializable {
//定义第一个值
private Integer firstValue;
//定义第二个值
private Integer secoundValue;
public MyOrderKey() {
}
public MyOrderKey(Integer firstValue, Integer secoundValue) {
this.firstValue = firstValue;
this.secoundValue = secoundValue;
}
@Override
public int compare(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
//这里是第一个值可以比较的情况
return firstValue-that.firstValue;
}else{
//这里是第一个值相同的情况
return secoundValue-that.secoundValue;
}
}
//这个是判断小于的情况
@Override
public boolean $less(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
return firstValue-that.firstValue<0;
}else{
if(secoundValue-that.secoundValue!=0){
return secoundValue-that.secoundValue<0;
}
}
return false;
}
//这个是大于的情况
@Override
public boolean $greater(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
return firstValue-that.firstValue>0;
}else{
if(secoundValue-that.secoundValue!=0){
return secoundValue-that.secoundValue>0;
}
}
return false;
}
//这里是小于等于的情况
@Override
public boolean $less$eq(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
return firstValue-that.firstValue<=0;
}else{
if(secoundValue-that.secoundValue!=0){
return secoundValue-that.secoundValue<=0;
}
}
return false;
}
@Override
public boolean $greater$eq(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
return firstValue-that.firstValue>=0;
}else{
if(secoundValue-that.secoundValue!=0){
return secoundValue-that.secoundValue>=0;
}
}
return false;
}
@Override
public int compareTo(MyOrderKey that) {
if(firstValue-that.firstValue!=0){
//这里是第一个值可以比较的情况
return firstValue-that.firstValue;
}else{
//这里是第一个值相同的情况
return secoundValue-that.secoundValue;
}
}
public Integer getFirstValue() {
return firstValue;
}
public void setFirstValue(Integer firstValue) {
this.firstValue = firstValue;
}
public Integer getSecoundValue() {
return secoundValue;
}
public void setSecoundValue(Integer secoundValue) {
this.secoundValue = secoundValue;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyOrderKey that = (MyOrderKey) o;
return Objects.equals(getFirstValue(), that.getFirstValue()) && Objects.equals(getSecoundValue(), that.getSecoundValue());
}
@Override
public int hashCode() {
return Objects.hash(getFirstValue(), getSecoundValue());
}
@Override
public String toString() {
return "MyOrderKey{" +
"firstValue=" + firstValue +
", secoundValue=" + secoundValue +
'}';
}
}
实现根据key二次排序代码
public class JavaSecondKeyOrder {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local")
.setAppName("JavaSecondKeyOrder");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> initDataRDD = javaSparkContext.textFile("data");
JavaPairRDD<MyOrderKey, Integer> myOrderKeyIntegerJavaPairRDD = initDataRDD.mapToPair((PairFunction<String, MyOrderKey, Integer>) s -> {
String[] s1 = s.split(" ");
return new Tuple2<>(new MyOrderKey(Integer.valueOf(s1[0]), Integer.valueOf(s1[1])), 1);
});
//根据key进行排序
myOrderKeyIntegerJavaPairRDD.sortByKey(false)
.map((Function<Tuple2<MyOrderKey, Integer>, String>) sortResult -> sortResult._1.getFirstValue() + " " + sortResult._1.getSecoundValue())
.foreach((VoidFunction<String>) result -> System.out.println(result));
javaSparkContext.close();
}
}
得到的结果
3 6
2 4
2 1
1 5
1 3
scala版本
自定义key
class ScalaSecondKeyOrder(val firstValue:Int,val secoundValue:Int) extends Ordered[ScalaSecondKeyOrder] with Serializable {
override def compare(that: ScalaSecondKeyOrder): Int = {
if(firstValue-that.firstValue!=0){
firstValue-that.firstValue
}else{
secoundValue-that.secoundValue
}
}
}
实现
object ScalaSecondKeyTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("ScalaSecondKeyTest")
val sc = new SparkContext(conf)
sc.textFile("data")
.map(
item=>{
val strs: Array[String] = item.split(" ")
val orderKey = new ScalaSecondKeyOrder(strs(0).toInt, strs(1).toInt)
(orderKey,1)
}
).sortByKey(false)
.map{
item=>{
item._1.firstValue.toString+" "+item._1.secoundValue.toString
}
}
.foreach(println)
sc.stop()
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











