







说明
从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)]该函数返回的是Pair类型的RDD,计算结果是当前RDD和other RDD中每个元素进行笛卡儿计算的结果。最后返回的是CartesianRDD。
上手使用
scala> val rdd1 = sc.makeRDD(List(1,2,3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:27
scala> val rdd2 = sc.makeRDD(List(4,5,6,7))
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:27
scala> val result = rdd1.cartesian(rdd2)
result: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[2] at cartesian at <console>:31
scala> result.collect
res0: Array[(Int, Int)] = Array((1,4), (1,5), (1,6), (1,7), (2,4), (2,5), (2,6), (2,7), (3,4), (3,5), (3,6), (3,7))
笛卡儿积会消耗大量的内存
原理图
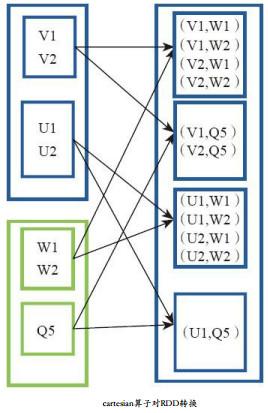
对两个RDD内的所有元素进行笛卡尔积操作。操作后,内部实现返回CartesianRDD。
左侧的大方框代表两个RDD,大方框内的小方框代表RDD的分区。右侧大方框代表合并后的RDD,大方框内的小方框代表分区。大方框代表RDD,大方框中的小方框代表RDD分区。 例如,V1和另一个RDD中的W1、 W2、 Q5进行笛卡尔积运算形成(V1,W1)、(V1,W2)、(V1,Q5)。
源码
/**
* Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of
* elements (a, b) where a is in `this` and b is in `other`.
*/
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = new CartesianRDD(sc, this, other)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









