







原理图
filter的功能是对元素进行过滤,对每个元素应用f函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉。 内部实现相当于生成FilteredRDD(this,sc.clean(f))。
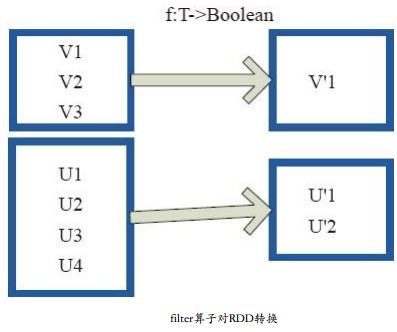
图中,每个方框代表一个RDD分区。 T可以是任意的类型。通过用户自定义的过滤函数f,对每个数据项进行操作,将满足条件,返回结果为true的数据项保留。 例如,过滤掉V2、 V3保留了V1,将区分命名为V1’。
源码
/**
* Return a new RDD containing only the elements that satisfy a predicate.
*/
def filter(f: T => Boolean): RDD[T] = {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}上手使用
scala> var rdd = sc.makeRDD(1 to 10,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:27
scala> rdd.filter(_ >3).collect
res1: Array[Int] = Array(4, 5, 6, 7, 8, 9, 10)














 2693
2693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









