




在 Agentic Coding 时代,我们常常面临一个核心痛点:想要获得顶尖的回答,你必须先提出一个顶尖的问题。 对于开发者而言,这意味着需要花费大量精力去构思、打磨给AI的“提示词”。一个模糊的指令,如“帮我写个函数”,可能会得到一段过于简单甚至不安全的代码;而一个详尽、结构清晰的提示词,则能直接生成生产环境级别的、考虑周全的解决方案。
如今,这道制约开发效率的难关,正在被 Qoder 攻克。Qoder平台正式上线 **“一键增强提示词(One-click enhancement for prompts)” **功能,将每一位开发者从“提示词”的负担中解放出来,让 Agentic Coding 变得前所未有的轻松和强大。
痛点:当你的想法,跑在了表达能力前面
你是否也曾经历过以下场景?
- 灵光乍现,却难以言表: 脑子里有一个复杂的需求轮廓,但不知道如何将其拆解成AI能理解的步骤和约束条件。
- 反复试错,消耗耐心: 不断修改提示词,与AI进行多轮“拉锯战”,只为了让它输出你真正想要的东西。
- 知识壁垒,限制想象: 不确定某个功能的最佳实践或最安全的实现方式,导致提示词本身存在缺陷。
这些正是Qoder 提示词增强功能要解决的精准靶点。
解决方案:什么是“一键增强提示词”?
Qoder 的“一键增强提示词”是一个内置于代码编辑器和聊天界面中的提示词优化功能,只需点击“增强”按钮,Qoder的背后模型就会在瞬间对你的原始意图进行深度理解和结构化重构。
它不仅仅是同义词替换或简单扩写,而是从多个维度对提示词进行智能升级:
- 需求明确化: 自动识别模糊描述,并将其转化为具体、可执行的任务。例如,将“弄个排序”增强为“使用Python编写一个快速排序算法,要求处理整数列表,包含详细的注释,并考虑输入为空或含重复元素的情况。”
- 场景上下文化: 根据你当前项目的工程结构、对话、相关上下文等重要信息作为额外输入,让优化的提示词更具有针对性。
- 约束条件完善化: 自动补充开发者容易忽略的关键约束,如性能要求、边界条件、错误处理、安全性考量(如SQL注入预防)、代码规范(如PEP8) 等。
- 结构化输出: 将增强后的提示词组织成清晰的模块,如“任务目标”、“输入输出”、“约束条件”、“示例参考”等,让AI模型能够更精准地解析并执行。
功能演示:从“小白”到“专家”的瞬间蜕变
假设你正在开发一个Python网络请求功能,原始提示词是:
“用requests库爬取某个网页的标题。”
这个提示词缺失了大量关键信息(如URL、错误处理、编码问题等)。点击“增强”后,你可能会得到如下优化版本:
【增强后提示词】使用Python的requests库编写一个网络爬虫,用于获取指定网页的HTML标题(即标签中的内容)。要求处理可能的网络异常,并在获取标题后将其打印输出。如果网页没有标题或获取失败,应输出相应的错误提示信息。
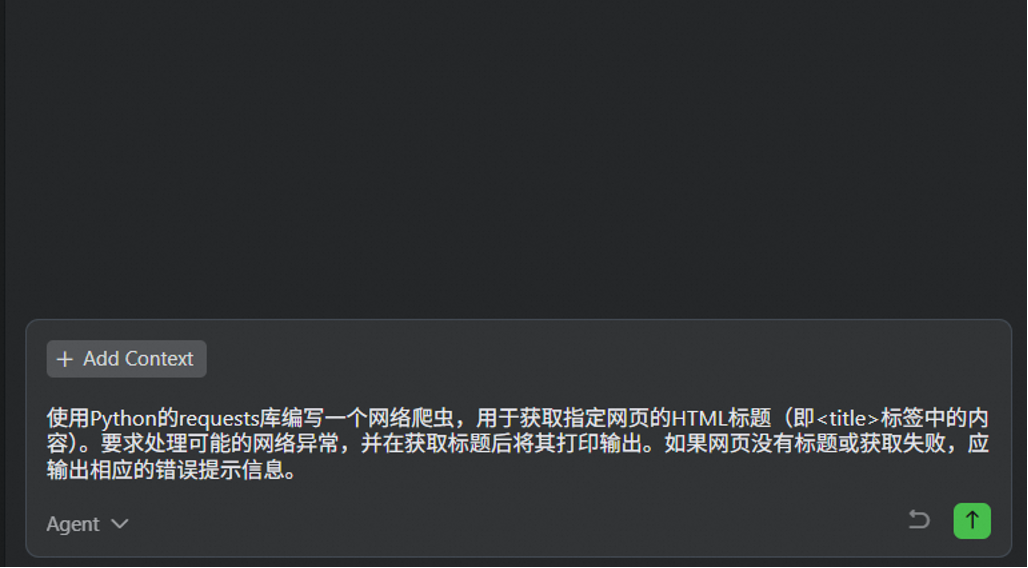
对比之下,后者几乎是一个资深开发者才会写出的完整任务说明书。基于这个增强提示词,Qoder Agent 将能生成一段可直接使用的生产级代码。(补充:如果你对增强的提示词不满意,可以选择右下角撤回,并进行重新优化)
立即尝试
“一键增强提示词”功能的上线,让开发者更高效地与 AI 对话。工具的进化不应该是增加用户的负担,而是通过智能化的方式,消除摩擦,放大创造力。
- 极大提升效率: 节省反复构思和修改提示词的时间,让你更专注于核心逻辑和架构设计。
- 降低使用门槛: 无论是编程新手还是资深专家,都能借此功能释放AI的全部潜力,写出更高质量的代码。
- 学习最佳实践: 通过观察增强后的提示词,你可以快速学习如何向AI清晰地表达复杂需求,无形中提升自己的设计和沟通能力。
未来,我们将继续围绕提示词优化、上下文理解等核心能力进行深度探索,让Qoder成为你编码过程中不可或缺的“第二大脑”。
立即体验Qoder,点击那个神奇的“增强”按钮,感受AI编程效率的质的飞跃!下载 Qoder:https://qoder.com/


















 6727
6727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











