







学习自https://www.bilibili.com/video/BV1J441137V6
RNN,CNN网络的缺点
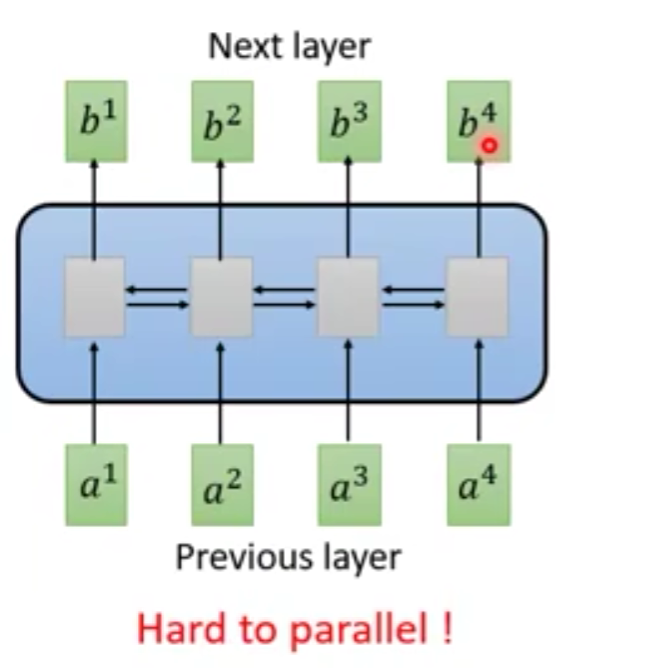
难以平行化处理,比如我们要算 b 4 b^4 b4,我们需要一次将 a 1 a^1 a1~ a 4 a^4 a4依次进行放入网络中进行计算。
于是有人提出用CNN代替RNN
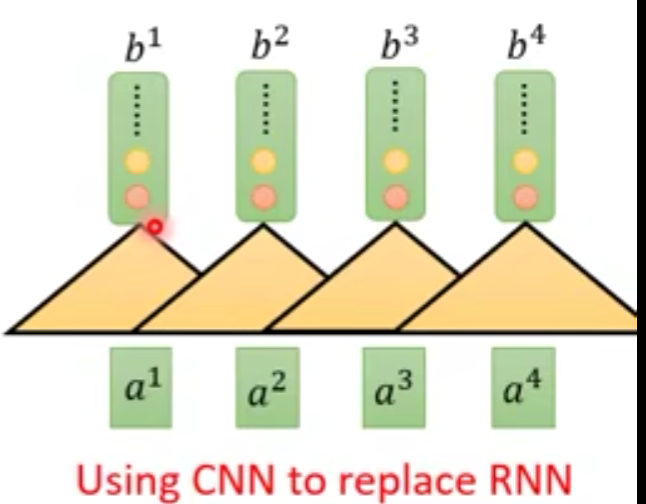
三角形表示输入,
b
1
b^1
b1的结果是由
a
1
,
a
2
a^1,a^2
a1,a2产生。
a
1
a^1
a1~
a
4
a^4
a4可以同时并行输入到CNN中。
但是,这么做的话可以表示的内容非常有限,解决方法是再往上继续建造。
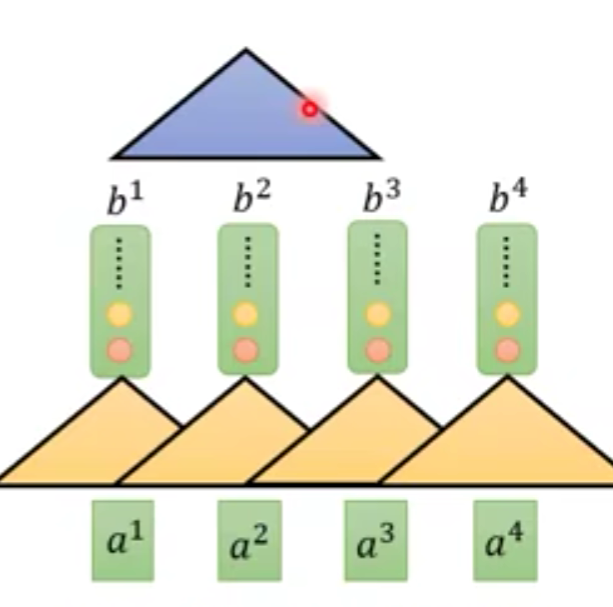
这样的话,蓝色的输入,就相当于获得了
a
1
a^1
a1~
a
4
a^4
a4的输入。
CNN的优点就是可以同时计算,缺点就是需要叠很多层。
self-Attention层
self-Attention层要做的就是,既能达到RNN的功能,同时又能像CNN一样平行化。
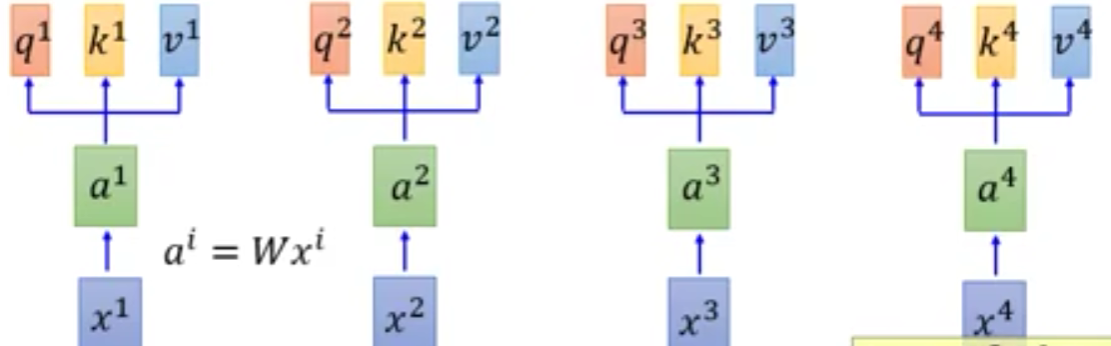

self-attention层运作步骤
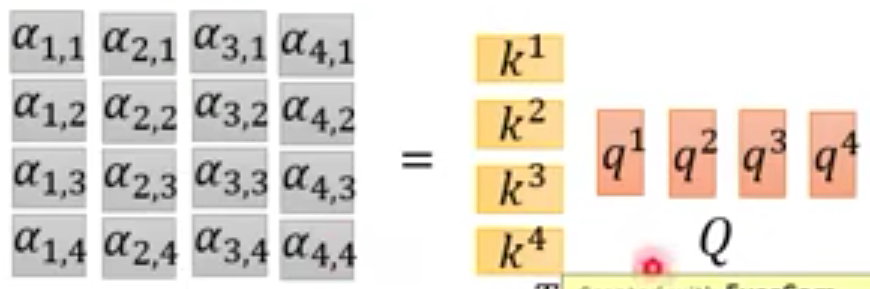
- 拿每个q与每个k进行attention运算
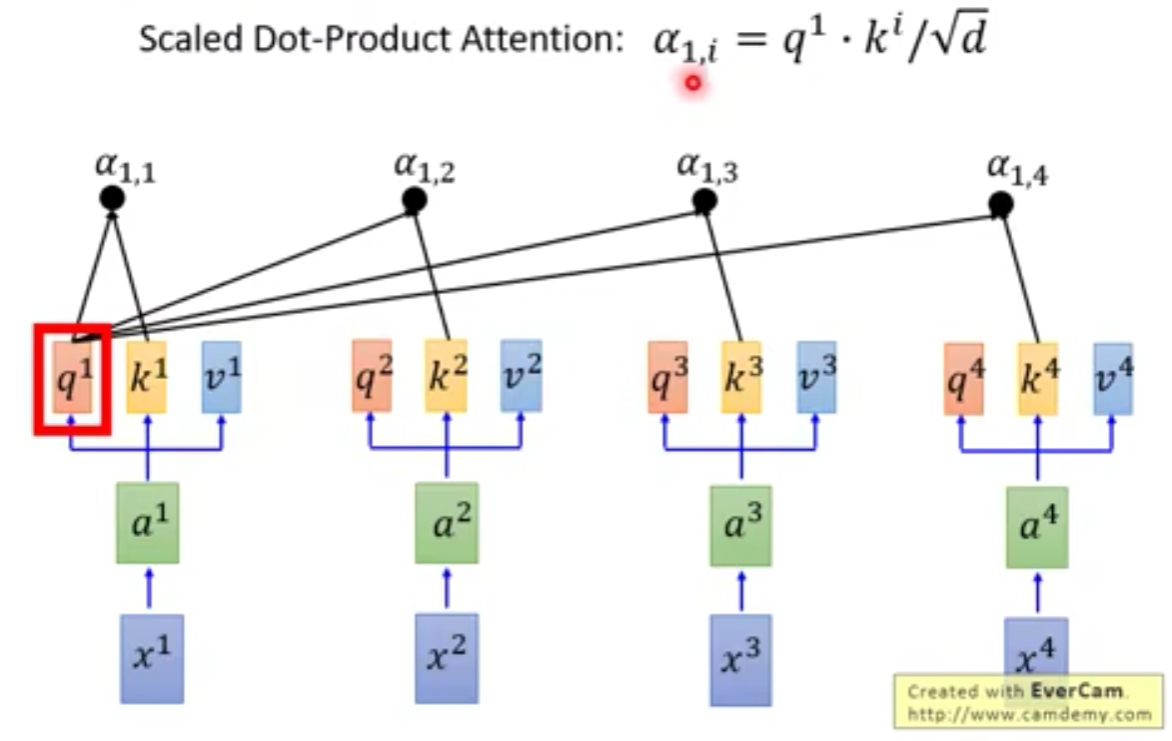
d d d为 q , k q,k q,k的维度,这个可以理解为是为了平衡维度带来的影响,因为维度越大,点乘出来的结果就会相应的较大,所以除以维度可以消除一部分影响。 - 然后再统一做一下softmax
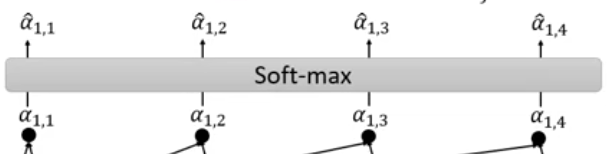
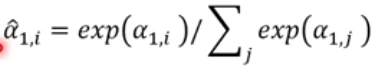
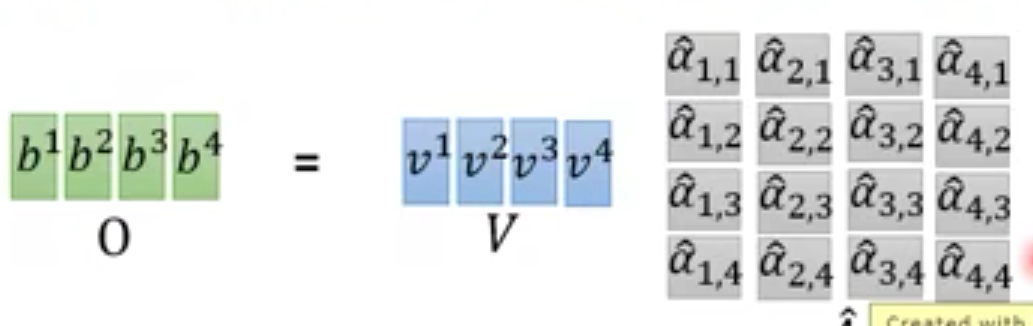
- 随后
a
^
\hat{a}
a^再和
v
v
v相乘
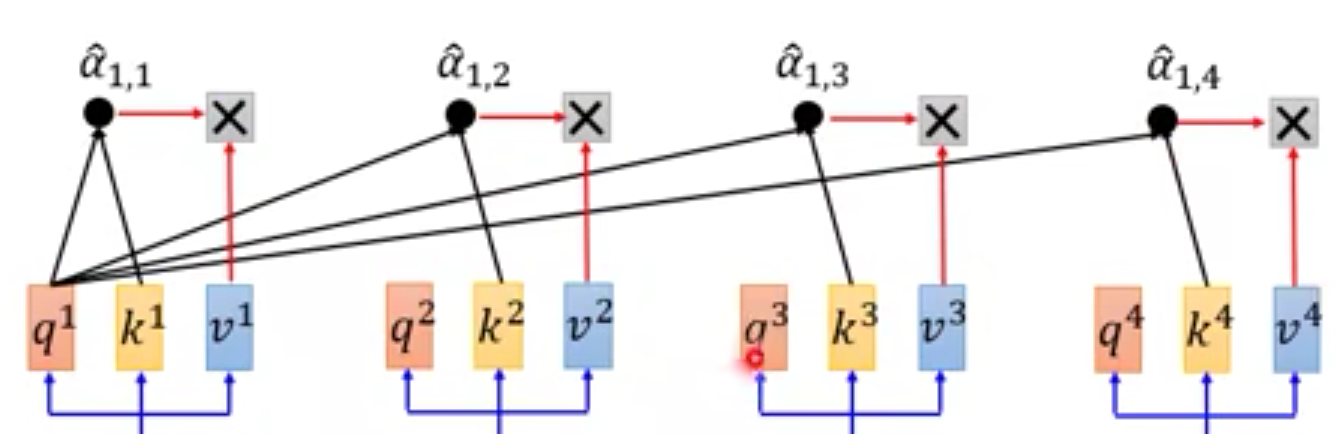
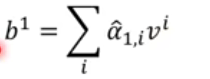
这样,计算 b 1 b^1 b1既可以并行计算,也能获取到 x 1 x^1 x1~ x 4 x^4 x4的全部数据。
如何并行化
可以把上一层的内容统统放入到矩阵中,进行一次矩阵乘法即可算出下一层。而矩阵乘法可以用GPU加速。
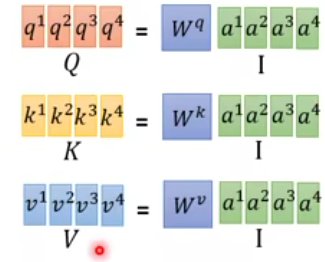
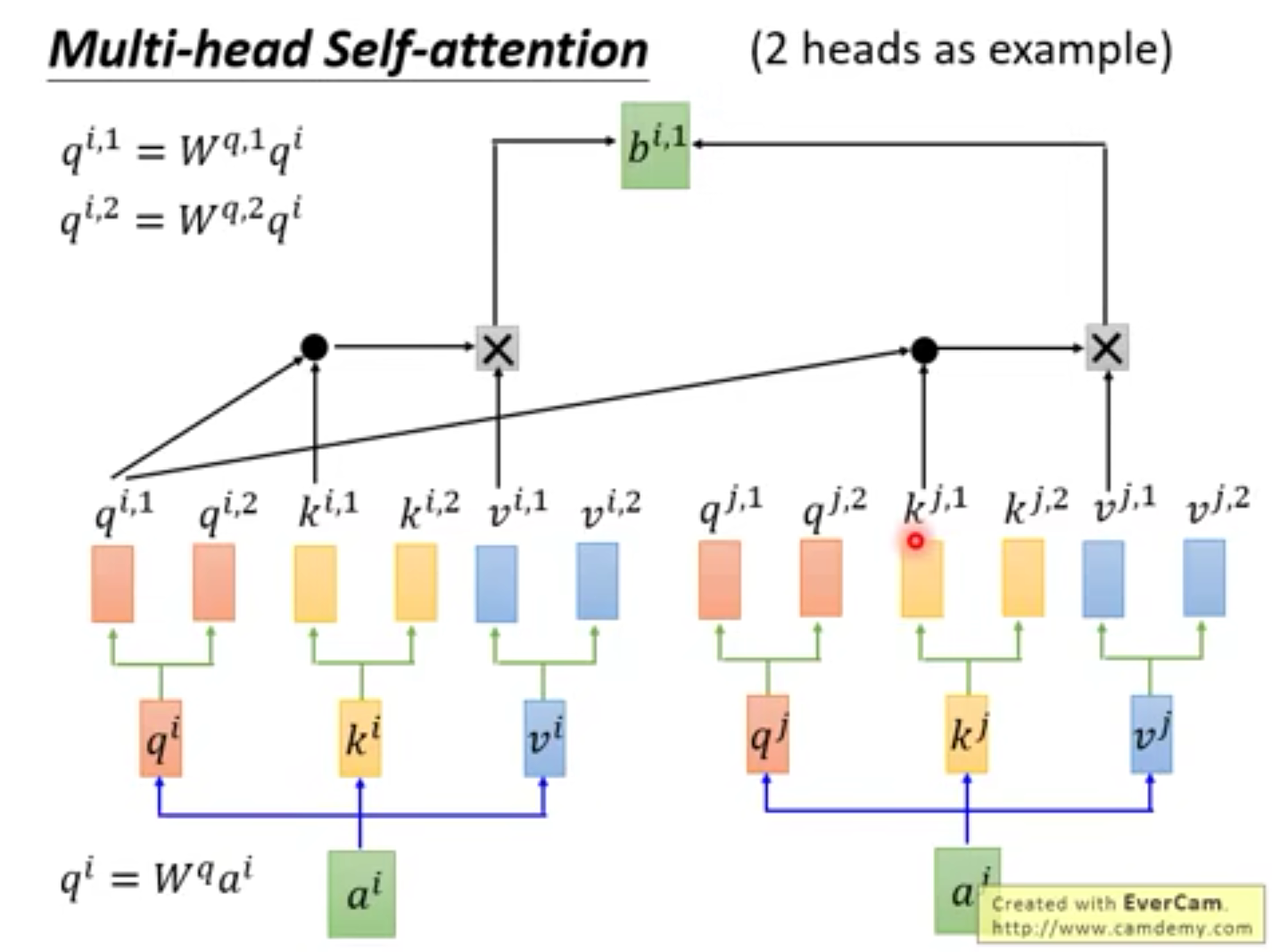
q
,
k
,
v
q,k,v
q,k,v也是可以用多层的。
Position Encoding
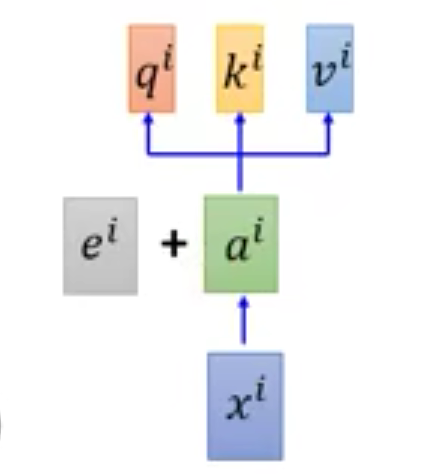
实际上,
x
x
x序列的位置信息是不重要的,因为每个位置都有一个独一无二的
e
i
e^i
ei向量与它相加,依次来表示位置信息。这个
e
i
e^i
ei不是从数据中学到的,而是人为赋值的。
Sequence To Sequence
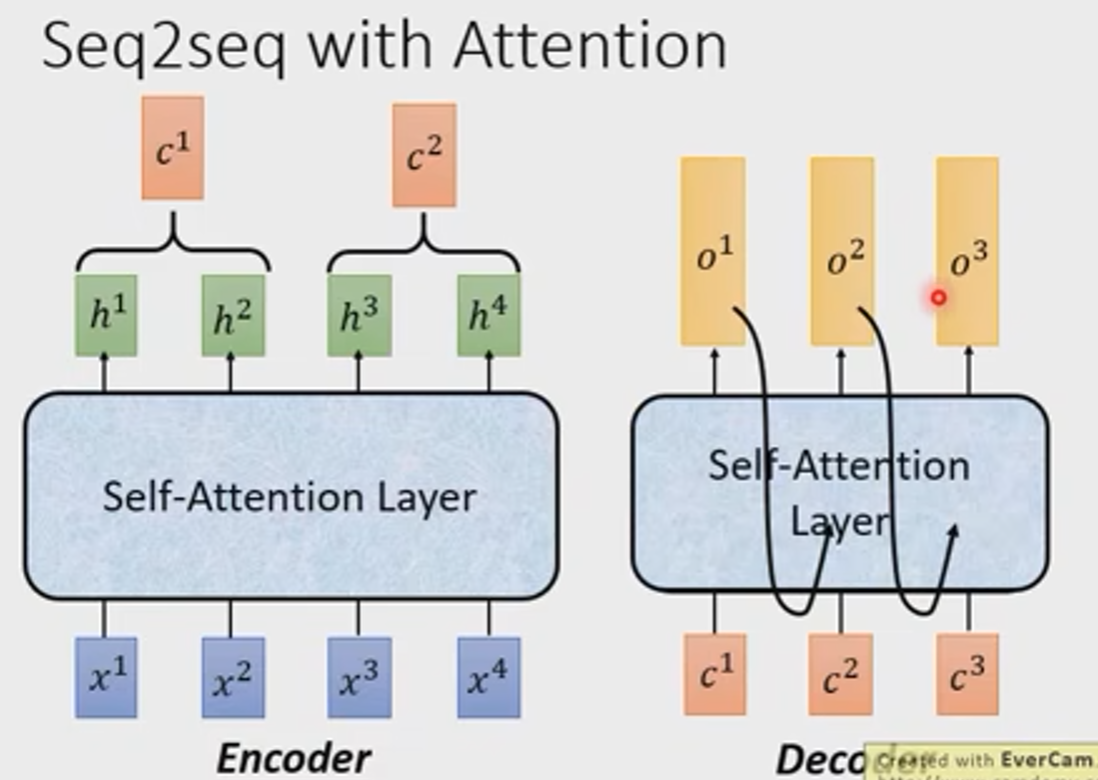
在Sequence To Sequence模型中,就可以用self-Attention层来代替RNN或者CNN。
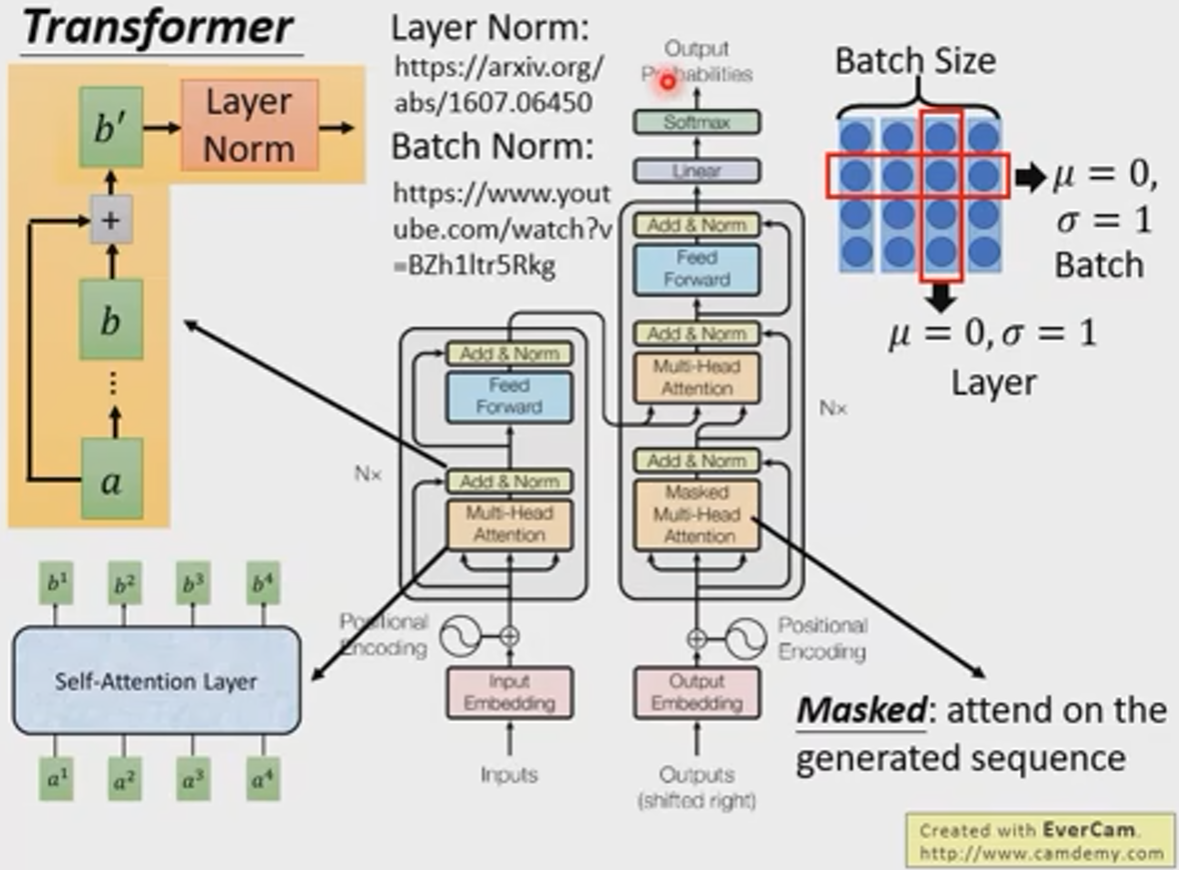
Transformer
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









