







你对于大型语言模型(LLMs)的复杂世界以及围绕它们的技术术语感到好奇吗?
理解从训练和微调的基础方面到转换器和强化学习的尖端概念,是揭开驱动现代人工智能大语言模型神秘面纱的第一步。
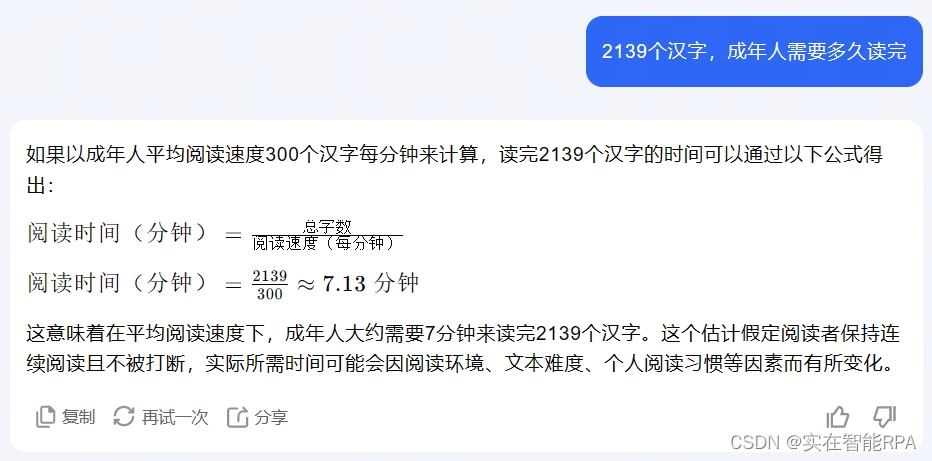
在本文中,我们将深入探讨 25 个关键术语,以增强你的技术词汇量(最起码跟朋友聊大模型时,本文的2139字可以硬控对方7.13分钟)。
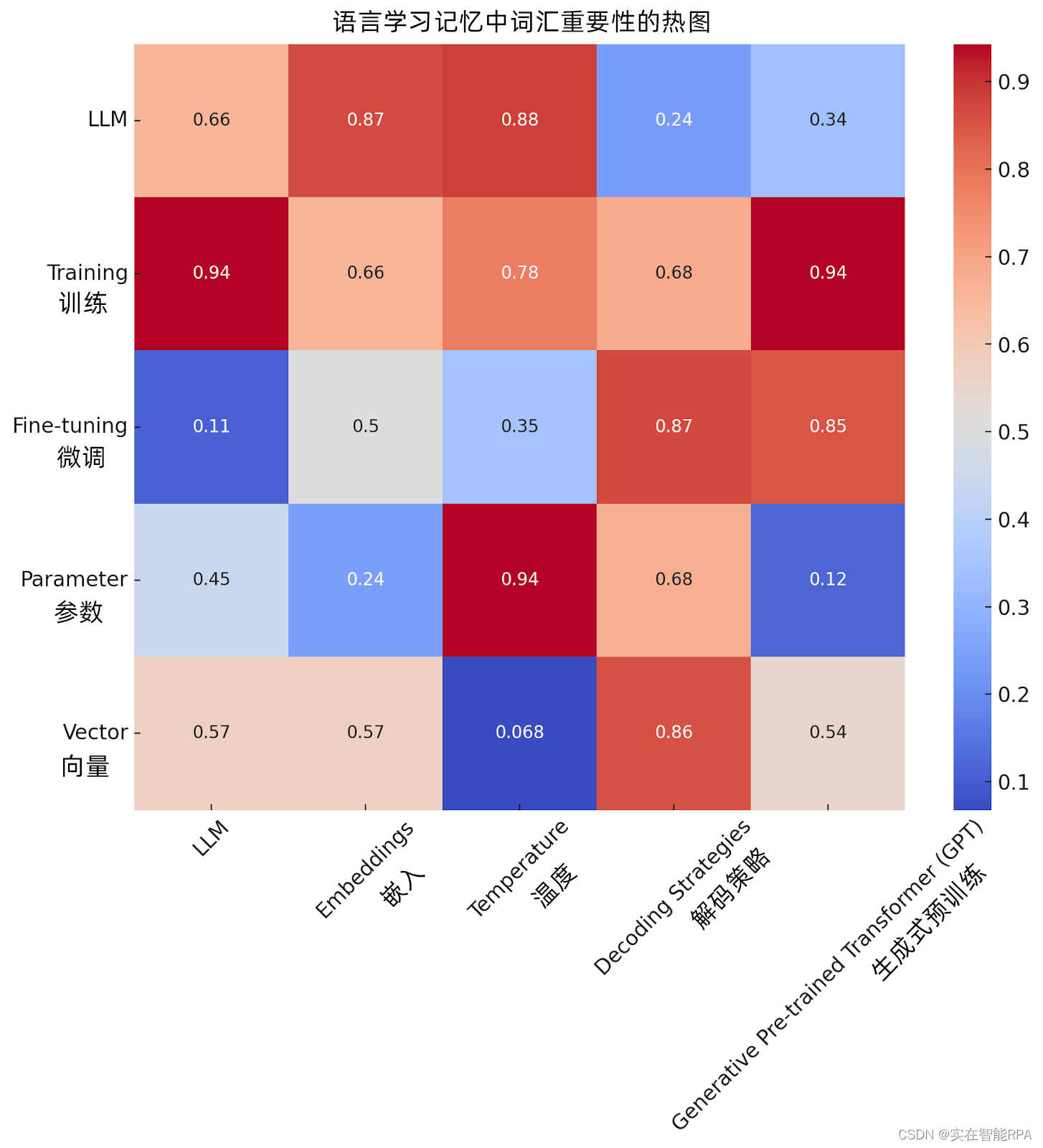
热图代表了在LLMs的背景下术语的相对重要性。
1.LLM (大语言模型)
大型语言模型(LLMs)是先进的人工智能系统,它们在广泛的文本数据集上进行训练,以理解和生成类似人类的文本。它们使用深度学习技术以相关性强的方式处理和生成语言。LLMs 的发展,如 OpenAI 的 GPT 系列、谷歌的 Gemini、Anthropic AI 的 Claude 和 Meta 的 Llama 模型,标志着自然语言处理的重大进步。
2.培训
训练是指通过将语言模型暴露给大型数据集来教会它理解和生成文本的过程。模型学会预测序列中的下一个词,并通过调整其内部参数,随着时间的推移提高其准确性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











