







大致看了看MPI的一些函数,勉强写出这两个程序,这两个程序的效率不高(这个问题很严重),而且对输入的鲁棒性非常不好(可能并行程序不太需要关注这个)。
只是实现了功能,有非常多优化的空间,如果有时间的话再优化吧。
要求一个行向量和一个方阵的乘积,乘积结果也是一个行向量,用MPI编写并行程序。假设子任务数目总是能被进程数均匀划分。
①方阵按列分配任务
在输入时转置输入,则按列分配就变成了按行分配,只要直接分发给各个进程。
MPI程序
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
int main()
{
int comm_sz;//进程数
int my_rank;//本进程的编号
int i,j;//游标
int allsum=0;//所有进程加和,给0号进程用
int N;//待用户键入的数,表示阶数
int *mat=NULL;//存矩阵数组
int *subMat=NULL;//子矩阵数组
int sum;//保存暂时和
int *result=NULL;//结果
int *allResult=NULL;//总结果
/*****************************************/
MPI_Init(NULL,NULL);//初始化MPI
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz);//获取进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank);//获取本进程号
//读入和广播阶数N
if(my_rank==0)//如果是0号进程
{
printf("Input N:");
scanf("%d",&N);//只有0号进程能接受标准输入
//构建矩阵数组
mat=malloc(N*N*sizeof(int));
}
//将0号进程收到的N广播给所有进程
MPI_Bcast(&N,1,MPI_INT,0,MPI_COMM_WORLD);
//构建向量数组
int *vec=malloc(N*sizeof(int));
//读入和广播向量vec
if(my_rank==0)
{
printf("Input the Vec:\n");
for(i=0;i<N;i++)
scanf("%d",&vec[i]);
}
//将0号进程收到的vec广播给所有进程
MPI_Bcast(vec,N,MPI_INT,0,MPI_COMM_WORLD);
//每个进程构建自己的子矩阵数组
subMat=malloc(N*N/comm_sz*sizeof(int));
//转置地读入和散射矩阵
if(my_rank==0)
{
printf("Input the Mat:\n");
//转置地读入,外循环是列
for(j=0;j<N;j++)
for(i=0;i<N;i++)
scanf("%d",&mat[i*N+j]);
}
//把矩阵的各个列散射到各个向量
MPI_Scatter(mat,
N/comm_sz*N,
MPI_INT,
subMat,
N/comm_sz*N,
MPI_INT,
0,
MPI_COMM_WORLD);
//计算本进程的任务,得到N/comm_sz个数
result=malloc(N/comm_sz*sizeof(int));//存放这些数
for(i=0;i<N/comm_sz;i++)
{
sum=0;
for(j=0;j<N;j++)
{
sum+=vec[j]*subMat[i*N+j];
}
result[i]=sum;
//printf("PID:%d,sum=%d\n",my_rank,sum);
}
if(my_rank==0)
{
allResult=malloc(N*sizeof(int));
//聚集
MPI_Gather(result,
N/comm_sz,
MPI_INT,
allResult,
N/comm_sz,
MPI_INT,
0,
MPI_COMM_WORLD
);
}
else
//聚集
MPI_Gather(result,
N/comm_sz,
MPI_INT,
allResult,
N/comm_sz,
MPI_INT,
0,
MPI_COMM_WORLD
);
//仅在0号进程上统计最后的加和
if(my_rank==0)
{
printf("Final Result:[");
for(i=0;i<N-1;i++)
printf("%d,",allResult[i]);
printf("%d]\n",allResult[i]);
}
MPI_Finalize();//使用完释放为MPI分配的资源
/*****************************************/
free(mat);
free(subMat);
free(result);
free(allResult);
return 0;
}运行结果
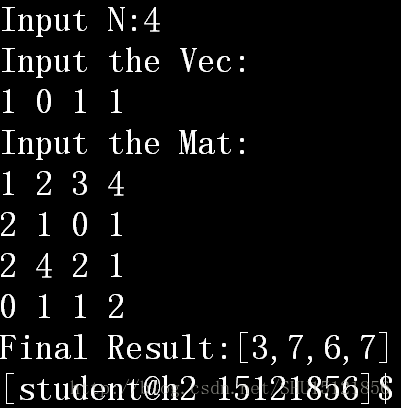
②方阵按块分配任务
这里要求进程数一定是一个完全平方数,而且正好能够把方阵分成这么多的小方阵。做法是先把读入进来的方阵按块子块展开到一行行,然后再分发给各个进程。
MPI程序
#include<mpi.h>
#include<stdio.h>
#include<stdlib.h>
//#include<math.h>
//自己的求平方根的函数,因为math里的sqrt报错
int mysqrt(int k)
{
int i;
for(i=0;i*i<k;i++)
;
if(i*i==k)
return i;
return -1;
}
//重排:将正常的矩阵a按块划分排列后给b
//N:大矩阵阶数,t:子阵维度,blks:每行能放的块数
void reSet(int *a,int *b,int N,int blks)
{
int t=N/blks;//子阵维度
int i,j,k,r;
for(i=0;i<N;i++)//每行(每个进程号)
{
//k为原分块矩阵的左上角位置
//只和进程号i有关
k=(i/blks)*N*t+(i%blks)*t;
for(j=0;j<N;j++)//每列
{
//r为从左上角位置到该位置的偏移值
//只和块内编号j有关
r=j/t+(j%t)*N;
b[i*(t*t)+j]=a[k+r];//k+r即是在原数组中的位置
}
}
}
//输出数组
void printMat(int *a,int n)
{
int i,j;
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
printf("%d ",a[i*n+j]);
printf("\n");
}
}
int main()
{
int i,j;//游标
int N;//大矩阵的阶数
int comm_sz;//总的进程数
int my_rank;//本进程号
int *big_mat=NULL;//大矩阵(方阵)
int *new_mat=NULL;//新的,按分块重排至行的方阵
int *vec=NULL;//整个向量
int numline;//用来记录这个进程在处理的是分块后的第几行
int *myRst=NULL;//用来记录本进程处理的,子向量乘这一块矩阵的结果
int *subMat=NULL;//用来记录本进程要处理的这一块分块矩阵
int blks;//blks:每行能放的块数
int t;//t:子阵维度
int allsum;//总和,给0号进程用
int *allResult=NULL;//总结果向量
/******************************************************/
MPI_Init(NULL,NULL);//初始化MPI
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz);//获取进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank);//获取本进程号
/*①对阶数N的处理(读入和广播)*/
//读入和广播阶数N
if(my_rank==0)//如果是0号进程
{
printf("Input N:");
scanf("%d",&N);//只有0号进程能接受标准输入
//只为0号进程构建大的矩阵数组
big_mat=malloc(N*N*sizeof(int));
}
//将0号进程收到的N广播给所有进程
MPI_Bcast(&N,1,MPI_INT,0,MPI_COMM_WORLD);
//blks:每行能放的块数
blks=mysqrt(comm_sz);
if(blks==-1)
{
printf("Not the total square number!Bye!\n");
return 0;
}
//t:子阵维度
t=N/blks;
/*②构建各个进程的向量和结果数组*/
//为每个进程分配向量数组
vec=malloc(N*sizeof(int));
//读入和广播向量vec
if(my_rank==0)
{
printf("Input the Vec:\n");
for(i=0;i<N;i++)
scanf("%d",&vec[i]);
}
//将0号进程收到的vec广播给所有进程
MPI_Bcast(vec,N,MPI_INT,0,MPI_COMM_WORLD);
//用来记录这个进程在处理的是分块后的第几行
numline=my_rank/blks;
//保存自己计算的结果的向量,阶数就是子矩阵的阶数t
myRst=malloc(t*sizeof(int));
//清空
for(i=0;i<t;i++)
myRst[i]=0;
/*③读入总的矩阵,
然后把分块变换成行,
分发给不同的进程*/
//读入矩阵,变换分块矩阵为分行
if(my_rank==0)
{
printf("Input the Mat:\n");
//读入
for(i=0;i<N;i++)
for(j=0;j<N;j++)
scanf("%d",&big_mat[i*N+j]);
//new_mat存变换后的矩阵
//实际上是每行t*t个元素!但是总元素数还是N*N
new_mat=malloc(N*N*sizeof(int));
//对其进行块划分重排
reSet(big_mat,new_mat,N,blks);
//输出看一下
printf("After change:\n");
printMat(new_mat,N);
}
//为每个进程计算时用到的子矩阵分配空间
//每个子矩阵是t*t的,所以要分配t*t的空间
//只要把变换后的矩阵的一行行传入即可(每行t*t个元素)
subMat=malloc(t*t*sizeof(int));
//把划分后的矩阵(new_mat)的各个行散射到各个进程的subMat中
MPI_Scatter(new_mat,
t*t,
MPI_INT,
subMat,
t*t,
MPI_INT,
0,
MPI_COMM_WORLD);
/*④每个进程各自计算结果
每个进程拿到的子矩阵是一列列排到一行上,
所以只要按子矩阵的维度遍历之,
但应注意不同进程使用的子向量可能不同*/
//p是这个进程子向量在列向量上的开始位置
int p=my_rank/blks;
//子矩阵一共有t列
for(i=0;i<t;i++)
{
//对于每一列上的每个元素
for(j=0;j<t;j++)
{
//vec[p]:子向量在向量中的起始位置
//把每一列的向量和子向量内积放入myRst的对应位置
myRst[i]+=vec[p*t+j]*subMat[i*t+j];/*p+j*/
}
}
/*
printf("My id:%d,my result:\n",my_rank);
for(i=0;i<t;i++)
printf("%d ",myRst[i]);
printf("\n");
*/
/*⑤聚集到0号进程上
实际上是开了comm_sz个t长度组成的总向量作聚集*/
if(my_rank==0)
{
//结果向量一共是comm_sz个长度为t的子向量
allResult=malloc(t*comm_sz*sizeof(int));
//聚集
MPI_Gather(myRst,
t,
MPI_INT,
allResult,
t,
MPI_INT,
0,
MPI_COMM_WORLD
);
}
else
//聚集
MPI_Gather(myRst,
t,
MPI_INT,
allResult,
t,
MPI_INT,
0,
MPI_COMM_WORLD
);
/*⑥从结果长向量中计算结果
把后面的分量加到0~t-1分量上去*/
if(my_rank==0)
{
//后面的分量加上来
for(i=N;i<t*comm_sz;i++)
//printf("%d,",allResult[i]);
allResult[i%N]+=allResult[i];
//输出看一下
printf("Finally Result:[");
for(i=0;i<N-1;i++)
printf("%d,",allResult[i]);
printf("%d]\n",allResult[i]);
}
MPI_Finalize();//使用完释放为MPI分配的资源
/******************************************************/
//因为它们都初始设置成NULL
//所以完全可以安全的对所有进程free掉
free(big_mat);
free(new_mat);
free(vec);
free(myRst);
free(subMat);
free(allResult);
return 0;
}
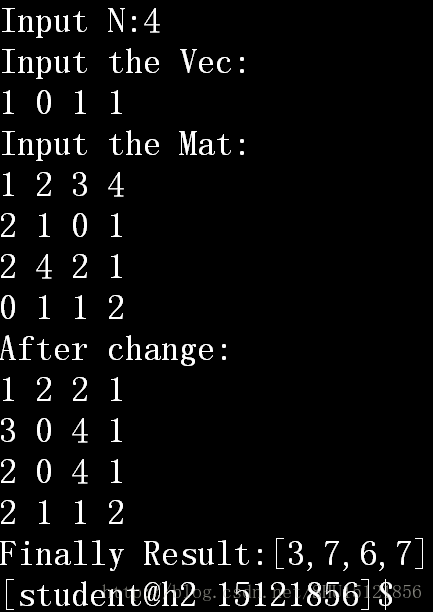















 2365
2365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









