







 本文深入解析了Doris数据仓库的存储结构,包括FE和BE节点的角色、Tablet和Rowset的概念,以及写入流程中的数据分发、DeltaWriter和Memtable机制。同时详述了删除流程和Compaction机制,展示了Doris如何优化数据导入和查询性能。
本文深入解析了Doris数据仓库的存储结构,包括FE和BE节点的角色、Tablet和Rowset的概念,以及写入流程中的数据分发、DeltaWriter和Memtable机制。同时详述了删除流程和Compaction机制,展示了Doris如何优化数据导入和查询性能。
目录
一、概述
1.1 存储结构的整体介绍
Doris是基于MPP架构的交互式SQL数据仓库,主要用于解决近实时的报表统计和多维分析。Doris高效导入、查询离不开其存储结构的设计。通过阅读Doris BE模块代码,分析Doris BE模块存储层的实现原理,主要包括Doris列存的设计、索引设计、数据读写流程、Compaction流程、Tablet数据分片和Rowset版本管理等功能。通过三篇文章来逐步进行阐述,分别为:
Doris存储层设计介绍1——存储结构设计解析(索引底层结构)-CSDN博客文章浏览阅读1.1k次,点赞33次,收藏19次。Doris存储层设计介绍1——存储结构设计解析(索引底层结构) https://blog.csdn.net/SHWAITME/article/details/136155008?spm=1001.2014.3001.5502
https://blog.csdn.net/SHWAITME/article/details/136155008?spm=1001.2014.3001.5502
本文章介绍了Doris数据写入及数据删除的实现流程。
1.2 名词解释
1.2.1 FE
StarRocks的前端节点。
存储方面:
(1)FE(Frontend)负责存储、维护集群的元数据信息。
FE的主要职责是存储和管理四类数据
用户数据信息:包括数据库、表的Schema和分片信息等。
各类作业信息:例如导入作业、克隆作业和SchemaChange作业等。
用户和权限信息。
集群和节点信息。
查询方面:
(1)FE负责接收、解析查询请求,规划查询计划,调度查询执行,并返回查询结果。
FE接收用户的查询请求,进行词法解析、语法解析和语义解析。
根据解析结果,生成逻辑执行计划和物理执行计划。
FE根据物理执行计划将查询任务分发给对应的BE节点上执行,并协调各个BE节点之间数据交换和计算。
FE收集BE节点返回的查询结果,并返回给用户。
1.2.2 BE
StarRocks的后端节点。
存储方面:
(1)BE(Backend)负责存储物理数据。
StarRocks使用最小的逻辑单元为tablet,最小的物理单元为rowset。
BE负责将数据存储在内存中,并按照预定义的格式刷写到物理磁盘上。
每次提交导入任务后,会在物理磁盘上形成一个小的rowset,而StarRocks会使用异步的compaction任务来合并这些rowset,形成较大的rowset,并使用base compaction任务将它们合并为段(segment)。
在读取数据时,最终会扫描这些segment对象来获取数据。
查询方面:
(1)BE负责依据FE生成的物理查询计划,分布式地执行查询计划。
BE根据FE生成的物理查询计划,在各自的节点上进行数据存储和计算。
BE节点根据查询计划并行地执行具体的查询操作,包括数据扫描、过滤、聚合排序等。
BE节点之间可能需要进行数据交换和合并,以完成复杂的查询操作。
BE节点将局部的查询结果返回给FE节点,供FE节点汇总并返回给用户。
1.2.3 Tablet
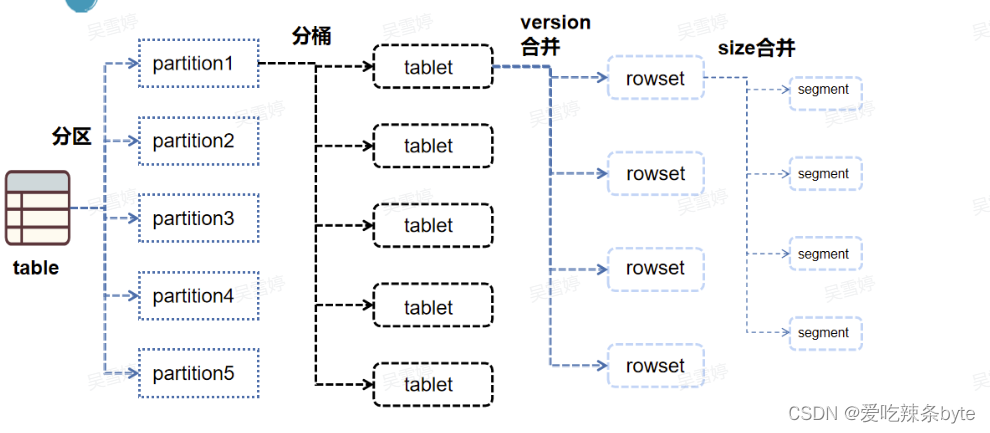
每个分区partition内部(逻辑概念)会按照分桶键,采用哈希分桶算法将数据划分为多个桶bucket,每个桶的数据称之为一个数据分片tablet(实际的物理存储单元)。每个tablet包括若干个连续的Rowset。
1.2.4 Rowset
一个tablet中包含若干连续的rowset(rowset是逻辑概念),rowset代表tablet中一次数据变更的数据集合(数据变更包括了数据新增,更新或删除等)。rowset按版本信息进行记录,版本信息中包含了两个字段first和second,first表示当前rowset的起始版本(start version),end表示当前rowset的结束版本(endversion)。
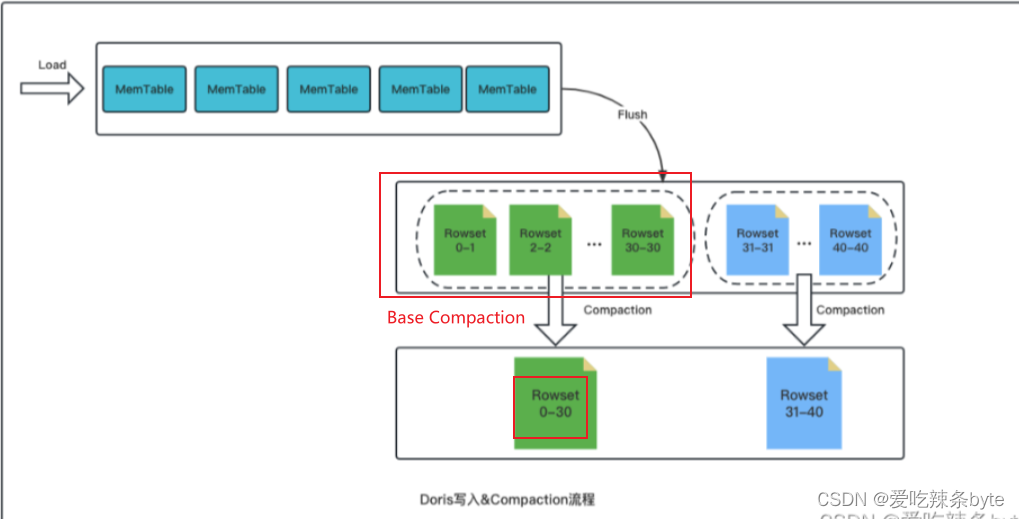
Doris的数据写入是以微批的方式进行的,每一个批次的数据针对每个tablet都会形成一个rowset(一个tablet是由多个rowset组成的)。每个rowset都有一个相应的起始版本(start version)和终止版本(end version)。对于新增的rowset,起始版本和终止版本是一样的,表示为[ 6-6]、[ 7-7]等。多个 rowset经过compaction会形成一个大的rowset。合并后的起始版本和终止版本是多个版本的并集,如[ 6-6]、[ 7-7]、[8-8]合并后变成 [6-8],如下图:
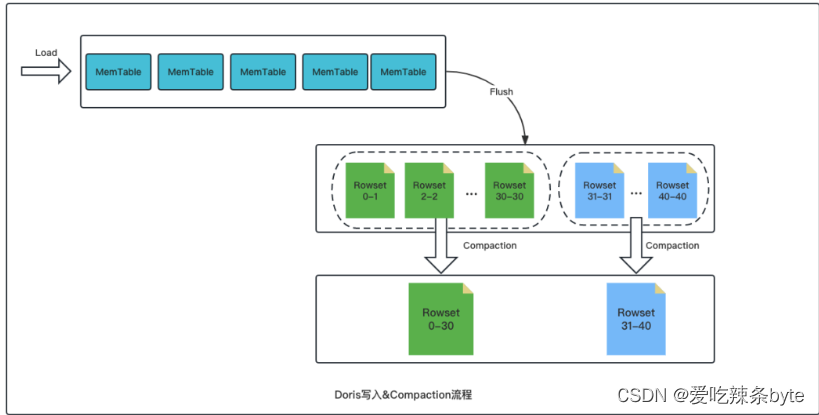
1.2.5 Version
有Start、End两个属性构成,用来维护数据变更的记录信息。通常用来表示rowset的版本范围,在一次新数据导入后生成一个Start、End相等的rowset,多个 rowset经过compaction会形成一个大的rowset。合并后的起始版本和终止版本是多个版本的并集,如[ 6-6]、[ 7-7]、[8-8]合并后变成 [6-8]。
1.2.6 Segment
Segment表示rowset中的数据分段,多个Segment会构成一个rowset。 segment文件既是存储文件的最小单元,也是索引文件生成的文件存储区域。segment文件的目录结构和segment文件本身的构成:

对存储数据的路径管理是通过be.conf中的参数storage_root_path配置的。在storage目录下的data目录中,存放着以分桶 id为命名的目录,下一层级是tablet id命名的tablet目录,在tablet目录下面就是Segment文件。Segment文件可以有多个,一般按照大小进行分割,默认为256MB。该文件命名是以{rowset_id}_{segment_id}.dat结构的dat文件。

1.2.7 Compaction
连续版本的rowset合并的过程称为compaction,合并过程中也会对数据进行压缩操作。
Doris 通过类似 LSM-Tree 的结构写入数据,后台通过 Compaction机制不断将小文件合并成有序的大文件。对于单一的数据分片(tablet),数据会按照顺序写入内存(写缓存memstore),达到阈值后刷写到磁盘,这些文件保存在一个rowset中。在Doris中,Compaction机制根据一定的策略对这些rowset合并成有序的大文件,极大地提升查询性能。compaction如下图:
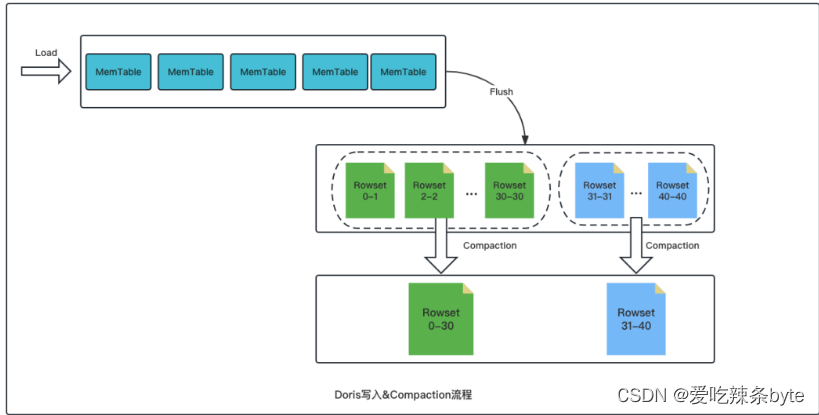
ps:表,分区,分桶,tablet,rowset,segment文件的关系图:
二、写入流程
Doris针对不同场景支持了多种形式的数据写入方式,其中包括了从其他存储源导入的Broker Load,HTTP同步数据导入Stream Load、例行导入的Rountine Load导入和Insert into写入等。导入流程会涉及FE模块(主要负责导入计划生成和导入任务的调度工作)、BE模块(主要负责数据的ETL和存储)、Broker模块(提供Doris读取远端存储系统中的文件的能力)。其中Broker模块仅在Broker Load导入类型中应用。
下面是以Doris中最常见的Stream Load(本质上是一个HTTP的PUT请求)导入方式为例,阐述Doris的数据写入流程:
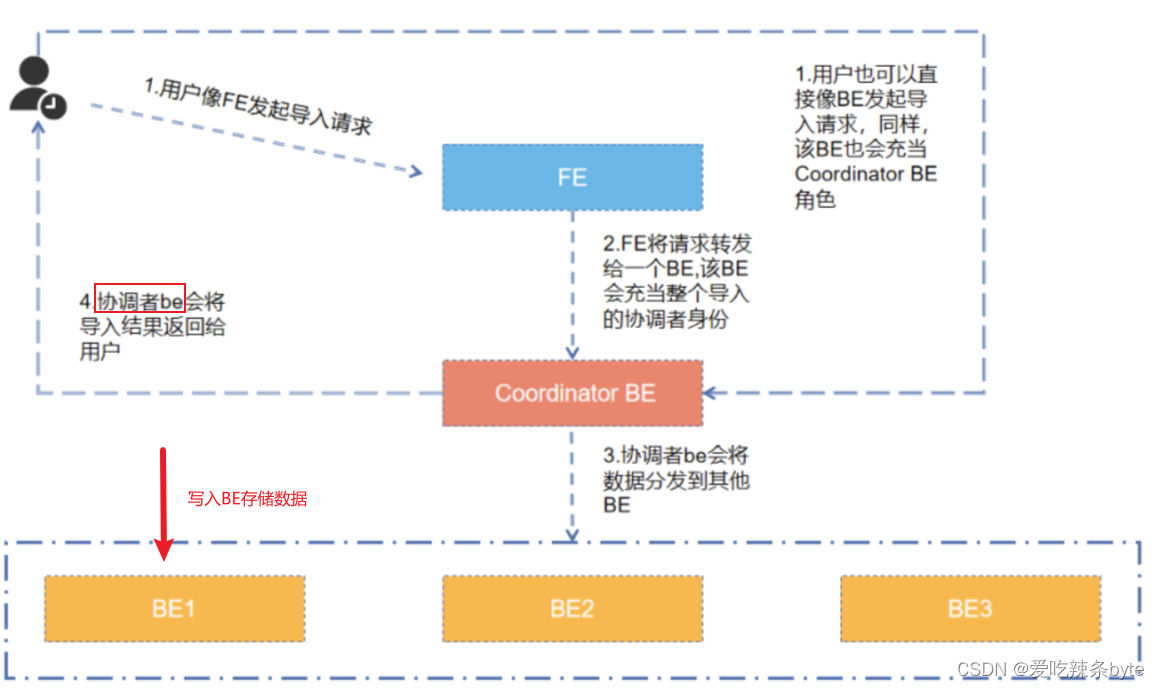
流程描述如下:
(1)用户发起导入请求,该请求可以直接发往FE,FE会通过轮询机制选定Coordinator BE来接收请求(集群内的负载均衡),也可以由用户自己在导入请求时指定某个BE为协调者角色,发起导入请求。
(2)Coordinator BE收到导入请求后,会把数据分发到其他BE数据节点,当集群内一份数据有两个数据节点完成数据写入后,就标志着这次导入事务成功,剩余的一份数据会由剩下的节点从这两个副本中去同步数据。
ps:Coordinator BE基于FE生成的执行计划,管理导入任务LoadJob
(3)导入数据成功后,协调者会将导入任务的状态返回给用户。
ps:数据写入到BE的存储层的过程中,会先写入到内存中,达到阈值后按照存储层的数据格式写入到物理磁盘上。
接下来主要阐述数据写入到BE存储层的详细流程
2.1 数据分发流程
数据在经过清洗过滤后,会通过Open/AddBatch请求分批量的将数据发送给存储层的BE节点上。在一个BE上支持多个LoadJob任务同时并发写入执行。LoadChannelMgr负责管理了这些任务,并对数据进行分发。
数据分发和数据写入过程如下图:
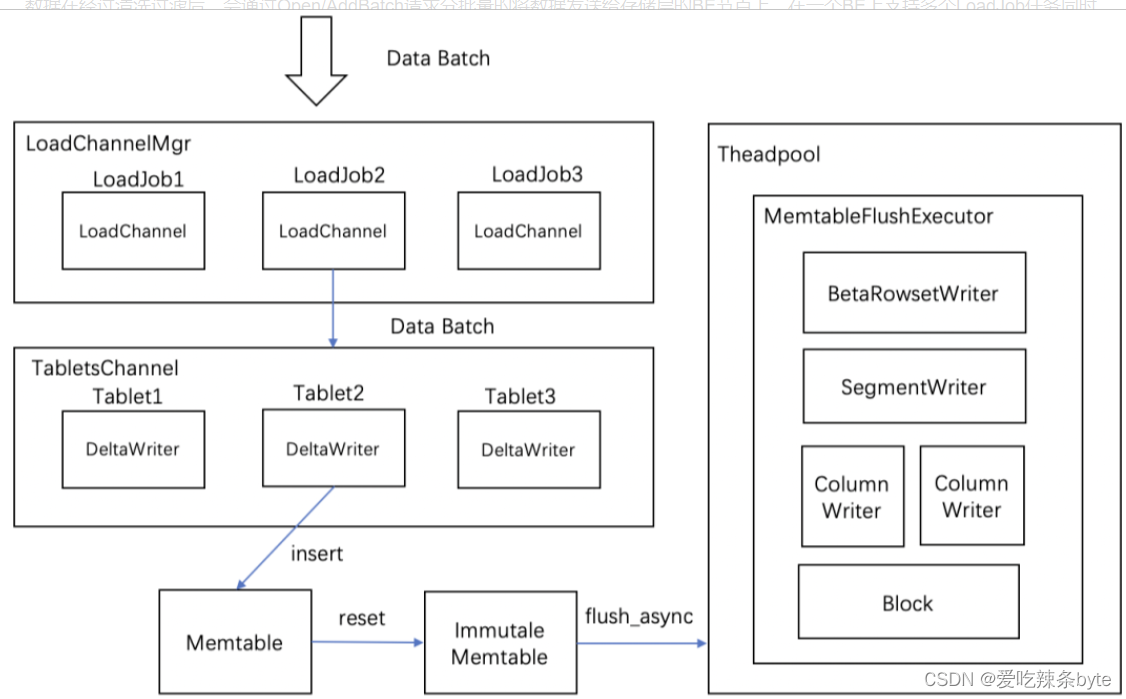
- 每次导入任务LoadJob会建立一个LoadChannel来执行,LoadChannel维护了一次导入的通道,LoadChannel可以将数据分批量的写入操作直到导入完成。
- LoadChannel会创建一个TabletsChannel执行具体的导入操作。一个TabletsChannel对应多个Tablet,一次数据批量写入操作中,TabletsChannel将数据分发给对应的Tablet数据分片,接下来开始真正的写入操作。
2.2 DeltaWriter 与 Memtable
DeltaWriter主要负责不断接受新写入的批量数据,完成单个Tablet的数据写入。DeltaWriter类似 LSM Tree 结构。在进行数据导入时,数据会先写入 Tablet 对应的 MemTable 中,MemTable 采用 SkipList 的数据结构。当 MemTable 写满之后,再异步flush到磁盘。数据从 MemTable 刷写到磁盘的过程分为两个阶段,第一阶段是将 MemTable 中的行存结构在内存中转换为列存结构,并为每一列生成对应的索引结构;第二阶段是将转换后的列存结构写入磁盘,生成 Segment 文件。与此同时会生成一个新的Memtable来继续接受新增数据导入,flush操作是MemtableFlushExecutor执行器完成。
其中Memtable中采用了跳表SkipList 的结构对数据进行排序,排序规则使用了按照schema的key的顺序依次对字段进行比较。这样保证了每个数据分段Segment中的数据是有序的。如果当前模型是agg模型时,还会对相同Key的数据进行预聚合。
具体而言,Apache Doris 在导入流程中会把 BE 模块分为上游和下游,其中上游 BE 对数据的处理分为 Scan 和 Sink 两个步骤:首先 Scan 过程对原始数据进行解析,然后 Sink 过程将数据组织并通过 RPC 分发给下游 BE。当下游 BE 接收数据后,首先在内存结构 MemTable 中进行数据攒批,对数据排序、聚合(建表指定的数据模型是agg模型时,可以对相同key的数据进行预聚合),并最终下刷成数据文件(也称 Segment 文件)到磁盘上来进行持久化存储。
2.3 物理写入
2.3.1 RowsetWriter 各个模块设计
在物理存储层面的写入,由RowsetWrter完成。RowsetWriter中又分为SegmentWiter、ColumnWriter、PageBuilder、IndexBuilder等了模块。
- 一次导入LoadJob任务会生成一个Rowset,一个Rowset表示一次导入成功生效的数据集合,由RowsetWriter负责完成Rowset的写入。
- SegmentWriter负责Segment的写入,一个Rowset可以由多个Segment文件(数据分段)组成
- ColumnWriter被包含在SegmentWriter中,Segment文件底层是列式存储结构,Segment中包含了各个列和相关的索引数据(数据和索引都是按照page进行组织),其中每个列的写入由ColumnWriter负责写入。
- 最后由FileWritableBlock来负责具体的文件读写。
Segment文件的存储格式可以参见:
2.3.2 RowsetWriter写入流程
整体的物理写入的如下图所示:
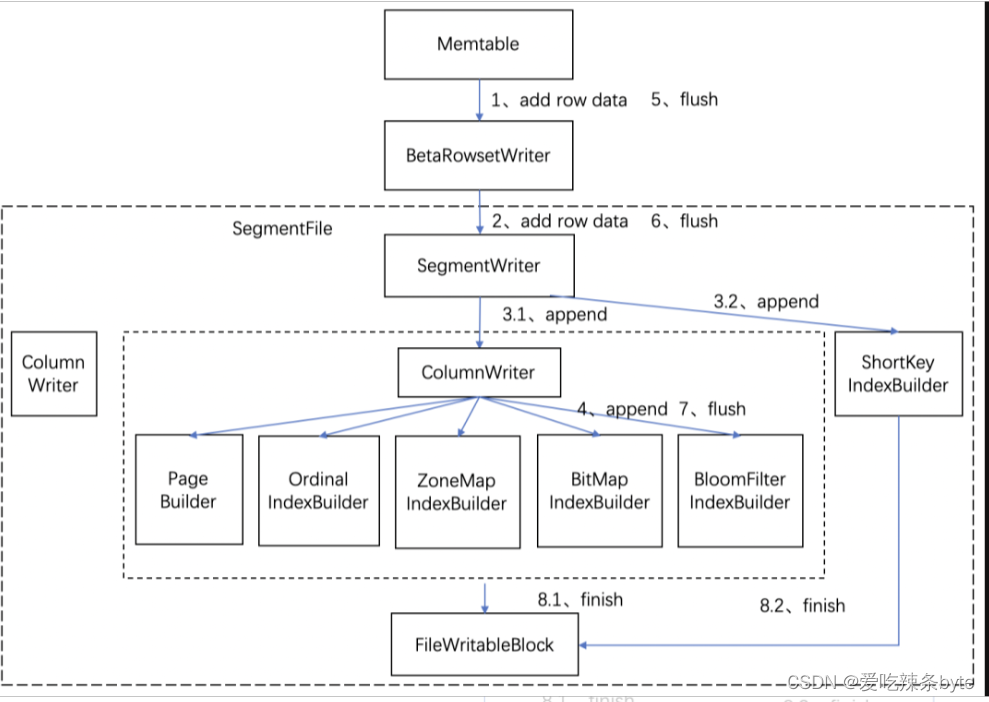
物理写入流程的详细描述: 物理写入流程的详细描述:
- 当一个MemTable写满时(默认为100M),会异步flush到磁盘上,Memtable内的数据是按key有排序的,会逐行写到RowsetWriter中。
- RowsetWriter将数据逐行写入到SegmentWriter中,每写入完毕一个Segment就会增加一个文件块对应。
- SegmentWriter将数据按行写入到各个ColumnWriter的中,同时写入ShortKeyIndexBuilder(前缀索引Builder)。
- ColumnWriter将数据分别写入PageBuilder和各个IndexBuilder。
- 添加完数据后,RowsetWriter执行flush操作。
- SegmentWriter的flush操作,将数据和索引写入到磁盘。
- ColumnWriter将各自数据写入到文件中。
- SegmentWriter生成SegmentFooter信息,SegmentFooter记录了Segment文件的原数据信息。完成写入操作后,RowsetWriter会再开启新的SegmentWriter,将下一个Memtable写入新的Segment,直到导入完成。
2.4 Rowset 发布
数据导入完成后,DeltaWriter会将新生成的Rowset进行发布,并将该Rowset设置为可见状态,表示导入数据已经生效能够被查询。一次导入会生成一个Rowset,每次导入成功会按序增加版本。整个发布过程如下:
- DeltaWriter统计当前RowsetMeta元数据信息,包括行数、字节数、时间、Segment数量。
- 保存到RowsetMeta中,向FE提交导入事务。
- 由FE统一下发Rowset发布任务,使得导入的Rowset版本生效。任务中指定了发布的生效version版本信息,之后BE存储层才会将这个版本的Rowset设置为可见。
- Rowset加入到BE存储层的Tablet进行管理。
三、删除流程
Delete操作在底层会对数据标记成Delete版本,存储在Meta信息中。当执行Compaction合并时,该Delete版本会合并到Base Compaction(基线版本),具体操作流程如下:
- 删除时,由FE直接下发删除命令和删除条件。
- BE在本地启动一个EngineBatchLoadTask任务,生成新版本的Rowset,并记录删除条件信息。这个删除记录的Rowset与其他导入过程(数据变更操作:insert 或 update)略有不同,该Rowset仅记录了删除条件信息,并没有实际的数据。
- FE发布Rowset生效版本,并将Rowset加入到Tablet中。
注:参考文章:

















 3139
3139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









