









目录
3.4 预处理语句优化(Prepared Statement)
一、背景说明
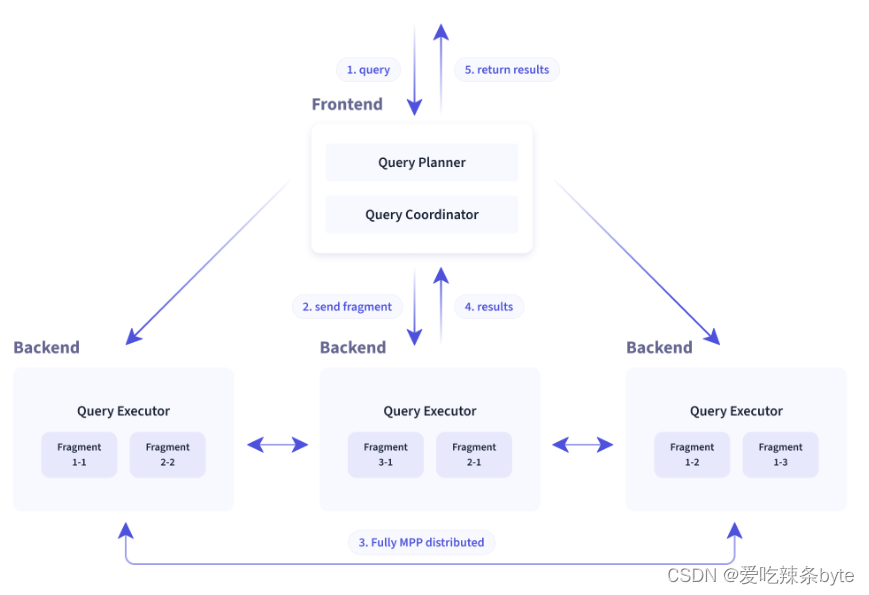
越来越多用户将Doris 用于构建企业内部的统一分析平台,这一方面需要 Doris去承担更大业务规模的处理和分析——既包含了更大规模的数据量、也包含了更高的并发承载,而另一方面,也意味着需要应对企业更加多样化的数据分析诉求,从过去的统计报表、即席查询、交互式分析等典型 OLAP 场景,拓展到推荐、风控、标签画像以及 IoT 等更多业务场景中,而数据服务(Data Serving)就是其中具有代表性的一类需求。
Data Serving 通常指的是向用户或企业客户提供数据访问服务,用户使用较为频繁的查询模式一般是按照Key查询一行或多行数据,例如:
-
订单详情查询
-
商品详情查询
-
物流状态查询
-
交易详情查询
-
用户信息查询
-
用户画像属性查询
Data Serving在实际业务中通常呈现为高并发的点查询——查询返回的数据量较少、通常只需返回一行或者少量行数据,但对于查询耗时极为敏感、期望在毫秒内返回查询结果,并且面临着超高并发的挑战。
OLAP数据库一般是基于列式存储引擎构建,且是针对大数据场景设计的查询框架,通常以数据吞吐量来衡量系统能力,因此在Data Serving高并发点查场景的表现往往不及用户预期。基于此,用户一般引入 HBase等 KV系统来应对点查询、Redis 作为缓存层来分担高并发带来的系统压力。而这样的架构往往比较复杂,存在冗余存储、维护成本高的问题。
Doris是一款基于MPP架构的高性能,实时的分析型数据库,可以在多个节点上并行处理查询,显著提高查询效率,且默认以列存格式引擎构建。列存格式非常适合进行数据分析,可以有效地压缩数据,并且在执行查询时只需要读取相关的列。但是有些高并发服务场景中 ,用户需要频繁获取整行数据,如果表较宽时,列存的IO也会被放大。
Doris中的FE是sql查询的访问层服务,使用 java编写,分析和解析sql也会导致高并发查询的高cpu开销,且其查询引擎和执行计划对于一些简单的查询(例如:点查询)而言太重了。
Doris 2.0 版本中,在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS的超高并发,极大拓宽了适用场景的能力边界。
Doris是如何实现高并发查询、如何实现高并发点查的呢?
二、高并发查询
对于高并发查询,其核心在于如何平衡有限的系统资源消耗与并发执行带来的高负载。换而言之,需要最大化降低单个 SQL 执行时的 CPU、内存和 IO 开销,其关键在于减少底层数据的 Scan 以及随后的数据计算。Doris能够实现高并发查询的能力主要是通过以下几个方面:
2.1 MPP架构
基于大规模并行处理(Massively Parallel Processing, MPP)架构设计,它可以将查询分解为多个任务,在多个节点上并行执行这些任务,使得系统可以通过增加更多的计算资源来线性扩展其查询处理能力。
2.2 列式存储
使用列式存储格式,对于任何给定的查询,它只需要读取涉及到的列而不是整行数据。这减少了磁盘I/O压力,因为只有必需的数据被加载到内存中。
2.3 分区分桶裁剪
Doris 采用两级分区,第一级是 Partition,通常可以将时间作为分区键。第二级为 Bucket,通过 Hash将数据打散至各个节点中,以此提升读取并行度并进一步提高读取吞吐。通过合理地划分区分桶,可以提高查询性。
2.4 索引和物化视图
Doris 支持创建索引和物化视图来加速查询,减少扫描行数和避免了大量的现场计算,例如前缀索引、Ordinal、ZoneMap、Bitmap和Bloom filter等索引和预计算物化。
2.4.1 索引
Doris 提供了丰富的索引结构来加速数据的读取和过滤。包括内置的前缀索引(Short Key Index)、Ordinal 索引、ZoneMap索引以及用户手动创建的Bitmap索引和 Bloom filter索引。其中内置索引是在 Doris 数据写入时自动生成的,无需用户干预。
-
前缀稀疏索引(Short Key Index)
前缀稀疏索引是建立在排序结构上的一种索引。Doris 存储在文件中的数据,是按照排序列有序存储的,Doris 会在排序数据上每隔1024 行创建一个稀疏索引项。索引的Key即当前这 1024 行中第一行的前缀排序列的值,当用户的查询条件包含这些排序列时,可以通过前缀稀疏索引快速定位到起始行。
- Ordinal Index
Ordinal lndex索引提供了通过行号来查找Column Data Page数据页的物理地址,Ordinal lndex索引能够将按照列存储的数据按行对齐,可以理解为一级索引。因此,其他类型的索引在查找数据的时候,都要借助Ordinal lndex(一级索引)查找 Data Page数据页的物理地址。
在一个segment文件中,数据始终按照key排序存储,数据写入的过程中,每一列的data page会由Ordinal Index管理,他会记录每一列对应的data page的offset,size大小,和该data page的第一个数据的行号信息。这样在查询的时候,就能通过 Ordinal lndex索引够快速定位到对应的data page的物理地址。
-
ZoneMap 索引
Doris会为Segment文件中的一列数据(key 列)自动添加ZoneMap索引,注意:当表的模型为dupulcate时,会所有字段开启zonemap索引。
ZoneMap索引存储了Segment和每个列对应每个Page的统计信息。Doris可以根据这些统计信息,快速判断这些数据块是否可以过滤掉,从而减少扫描数据量,提升查询速度。统计信息包括了Min最大值、Max最小值、HashNull空值、HasNotNull不全为空的信息。
- BitMap索引
Doris支持对低基数列创建Bitmap位图索引来加速数据查询。高基数列:例如UserID,低基数列:例如性别,婚姻状态等。
Bitmap位图索引创建时需要通过 create index 进行创建。Bitmap的索引是整个Segment中的Column字段的索引,而不是为每个Page单独生成一份。在写入数据时,会维护一个map结构,去记录下每个key值对应的行号,并采用Roaring位图对rowid进行编码。生成索引数据时,首先写入字典数据,即将map结构的key值写入到DictColumn中。然后,key对应Roaring编码的rowid(value值)以字节方式将数据写入到BitMapColumn。
- BloomFilter 索引
Doris支持用户对适用于高基数列(取值区分度比较大的字段)添加Bloom Filter(布隆过滤器)索引,Bloom filter索引主要用于快速判断某列中是否存在某个值。BloomFilter判定该列中不存在指定的值,如果确定不存在,就不会读取这个数据文件;如果索引判定该列中存在指定的值,也有可能这个值实际上不会存在,这时,会读取数据文件来进一步确认。
ps:高基数列:例如UserID,低基数列:例如性别,婚姻状态等。
以查询语句为例:select * from user_table where id > 10 and id < 1024;
假设按照 ID 作为建表时指定的 Key, 那么在 Memtable 以及磁盘上按照 ID 有序的方式进行组织,查询时如果过滤条件包含前缀字段时,则可以使用前缀索引快速过滤。Key 查询条件在存储层会被划分为多个 Range,按照前缀索引做二分查找获取到对应的行号范围,由于前缀索引是稀疏的,所以只能大致定位出行的范围。随后过一遍 ZoneMap、Bloom Filter、Bitmap 等索引,进一步缩小需要 Scan 的行数。通过索引,大大减少了需要扫描的行数,减少 CPU 和 IO 的压力,整体大幅提升了系统的并发能力。
2.4.2 物化视图
物化视图是一种典型的空间换时间的思路,其本质是根据预定义的SQL 分析语句执⾏预计算,并将计算结果持久化到另一张对用户透明但有实际存储的表中。在需要同时查询聚合数据和明细数据以及匹配不同前缀索引的场景,命中物化视图时可以获得更快的查询相应,同时也避免了大量的现场计算,因此可以提高性能表现并降低资源消耗。
2.5 向量化查询执行
Doris 实现了向量化查询处理,在执行操作时它可以一次处理数据列的一整块,而不是逐行处理。这样可以大大提高CPU的利用率,降低每个数据点的处理开销。
2.6 Runtime Filter
除了前文提到的用索引来加速过滤查询的数据, Doris 中还额外加入了动态过滤机制,即 Runtime Filter。在多表关联查询时,我们通常将右表称为 BuildTable、左表称为 ProbeTable,左表的数据量会大于右表的数据。在实现上,会首先读取右表的数据,在内存中构建一个 HashTable(Build)。之后开始读取左表的每一行数据,并在 HashTable 中进行连接匹配,来返回符合连接条件的数据(Probe)。而 Runtime Filter 是在右表构建 HashTable 的同时,为连接列生成一个过滤结构,可以是 Min/Max、IN 等过滤条件。之后把这个过滤列结构下推给左表。这样一来,左表就可以利用这个过滤结构,对数据进行过滤,从而减少 Probe 节点(左表)需要传输和比对的数据量。在大多数 Join 场景中,Runtime Filter 可以实现节点的自动穿透,将 Filter 穿透下推到最底层的扫描节点或者分布式 Shuffle Join 中。大多数的关联查询 Runtime Filter 都可以起到大幅减少数据读取的效果,从而加速整个查询的速度。
总结,通过以上一系列优化手段,可以将不必要的数据剪枝掉,减少读取、排序的数据量,显著降低系统 IO、CPU 以及内存资源消耗,从而提升并发。
上文提到的几点优化技术,Doris 实现了单节点上千QPS 的并发支持。但在一些超高并发要求(例如数万 QPS)的 Data Serving 场景中,仍然存在瓶颈:
-
列式存储引擎对于行级数据的读取不友好,宽表模型上列存格式将放大随机读取 IO;
-
OLAP 数据库的执行引擎和查询优化器对于某些简单的查询(如点查询)来说太重,需要在查询规划中规划短路径来处理此类查询;
-
SQL 请求的接入以及查询 计划的解析与生成由 FE 模块负责,使用的是 Java 语言,在高并发场景下解析和生成大量的查询执行计划会导致高 CPU 开销;
三、高并发点查询
3.1 行式存储格式(Row Store Format)
支持用户在建表语句的property中指定属性"store_row_column" = "true",即另存一份行数据(列存+行存),这样在单次检索整行数据时效率更高,减少磁盘访问次数。
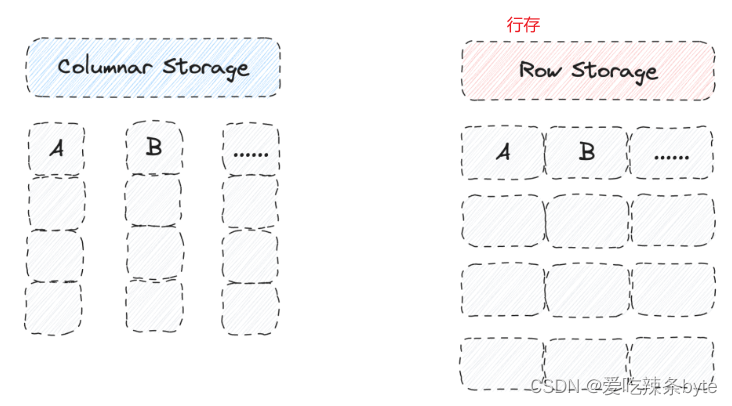
详细介绍见官网:高并发点查 - Apache Doris
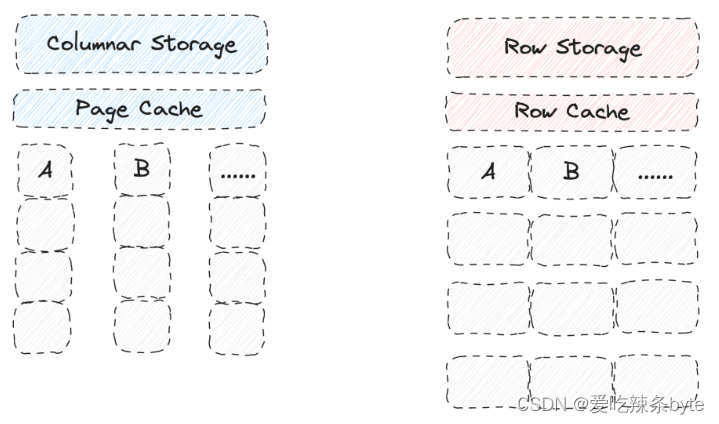
3.2 行存缓存(Row Cache)
Doris中已经有针对 Page级别(数据页)的 Cache,每个 Page中存的是某一列的数据, 所以 Page cache 是针对列的缓存,对于行存,如果一行里包括了多列数据,缓存可能被大查询给刷掉,为了增加行缓存命中率,单独引入了行存缓存,行缓存复用了 Doris 中的 LRU Cache 机制来保障内存的使用,通过指定下面的的BE配置来开启:
disable_storage_row_cache是否开启行缓存, 默认不开启row_cache_mem_limit指定 Row cache 占用内存的百分比, 默认 20% 内存
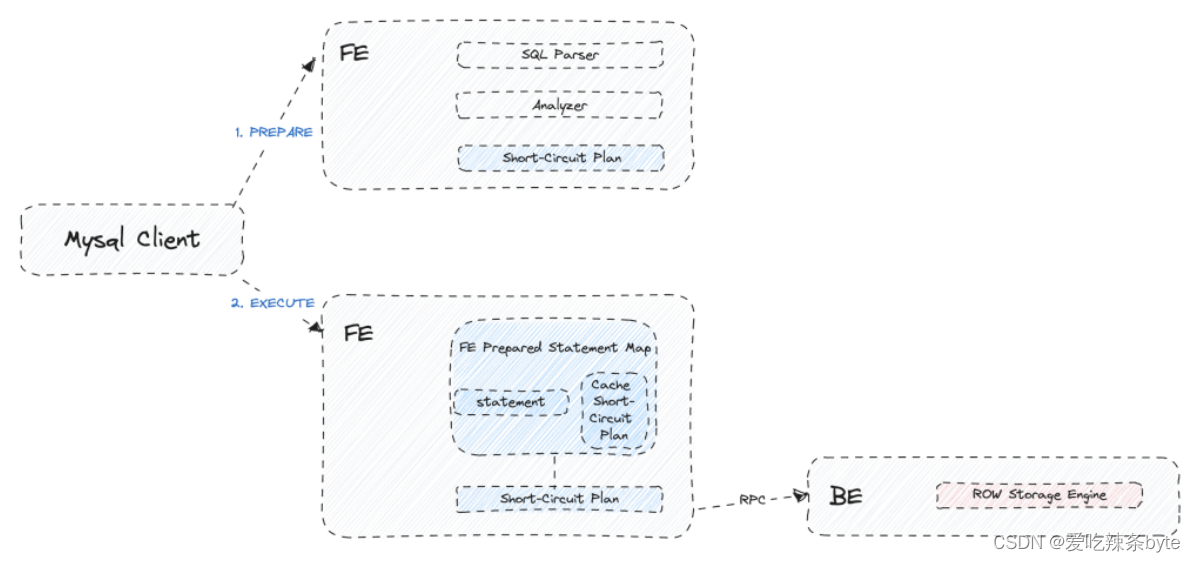
3.3 点查询短路径优化(Short-Circuit)
通常情况下,一条 SQL 语句的执行需要经过三个步骤:首先通过 SQL Parser 解析语句,生成抽象语法树(AST),随后通过 Query Optimizer 生成可执行计划(Plan),最终通过执行该计划得到计算结果。对于大数据量下的复杂查询,经由查询优化器生成的执行计划无疑具有更高效的执行效果,但对于低延时和高并发要求的点查询,则不适宜走整个查询优化器的优化流程,链路太长,会带来不必要的额外开销。
解决这个问题,Doris实现了点查询的短路径优化,绕过查询优化器以及 PlanFragment 来简化 SQL 执行流程,直接使用快速高效的读路径来检索所需的数据。
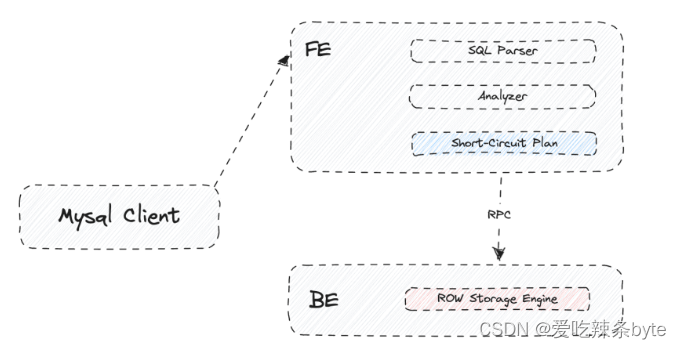
当查询被 FE 接收后,它将由规划器生成适当的 Short-Circuit Plan 作为点查询的物理计划。该 Plan 非常轻量级,不需要任何等效变换、逻辑优化或物理优化,仅对 AST 树进行一些基本分析、构建相应的固定计划并减少优化器的开销
3.4 预处理语句优化(Prepared Statement)
高并发查询中的 CPU 开销可以部分归因于FE 层分析和解析SQL 的CPU 计算,为了解决这个问题,Doris 在 FE 端提供了与 MySQL 协议完全兼容的Prepared Statement特性(目前只支持主键点查)。Prepared Statement 的工作原理是通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象即可。详细内容见官网:高并发点查 - Apache Doris
三、实测单节点上万QPS
实测过程见:
【Apache Doris】如何实现高并发点查?(原理+实践全析)
四、总结
Doris 基于MPP架构、列存、分区分桶、向量化引擎、索引视图等方面实现了高性能并发查询。在此基础上行式存储格式、点查询短路径优化、预处理语句以及行存缓存等特性实现了实现了单节点上万 QPS 的超高并发。
参考文章:
并发提升 20+ 倍、单节点数万 QPS,Apache Doris 高并发特性解读|新版本揭秘















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









