









目录
原文大佬的这篇Doris数仓建设案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。如有侵权等告知~
一、背景
特步集团有限公司是中国领先的体育用品企业之一,为了提高特步零售BI主题数据分析的准确性和时效性,2020 年11月特步集团首次引入了Doris进行数据仓库搭建试点。在项目实践过程中,遇到了很多困难,也解决了很多问题,这里总结出来分享给大家。
二、总体架构
在特步零售数据仓库的项目中,抛弃了传统的Hive离线数据处理模式,基于Doris 集群完成接口数据的接入、数仓层的建模和加工、以及BI报表的即时查询。
先展开说明一下这样设计的原因。在前期的项目经历中,既有过基于 Hive+Greenplum 搭建卡宾零售 BI 项目的经验,也有基于Greenplum+MySQL 搭建斐乐 BI 项目的经验,还有基于 Hive+Doris 的安踏户外BI项目经验,得到的结论有:
①MPP架构开发效率高,查询和跑批速度远高于 Hive 数仓;②MPP 架构支持有限的Delete和Update,开发的灵活度更好;③项目交付两套环境,运维难度很大;④ Doris 在架构设计上比 Greenplum 更为领先,对 OLAP 支持更好,查询性能也更高。基于以上原因,加上 Hive 数据处理和查询的时效性无法满足业务需求,所以坚定的选择了Doris 作为特步零售数据仓库的唯一大数据平台。
确定项目选型以后,讨论了数据仓库的分层设计。项目最先启动的是特步儿童 BI 项目,考虑到系统业务数据存在多个来源,复杂的业务指标口径以及来源相同的不同品牌需要进行拆分,我们在数据仓库层采用了 DWD、DWB、DWS 三层加工。

数据仓库分层逻辑如下:
(1)DWD 模型层:关联维度数据的加工和明细数据的简答整理,包括商品拆箱处理、命名统一、数据粒度统一等。DWD层的销售,库存明细数据均按照系统加工,每个系统的加工逻辑创建一张视图,结果对应一张物理表。DWD层大部分采用Duplicate Key模型,部分能明确主键的采用Unique Key模型。
(2)DWB 基础层:保留共性维度,汇总数据到业务日期、店铺、分公司、SKC 粒度。销售模块 DWB 层合并了不同系统来源的电商数据、线下销售数据、库存明细数据,还关联了维度信息,增加数据过滤条件,加工了分公司维度,确保 DWS 层可以直接使用。DWB层较多采用 Duplicate Key 模型,便于按照 Key 删除数据,也有部分采用Aggregate Key 模型。
(3)DWS 汇总层:将DWB加工结果宽表化,并按照业务需求,加工本日、本月、本周、本年、昨日、上月、上周、上年及每个标签对应的同期数据。DWS层较多采用Duplicate Key 模型,也有部分采用Aggregate Key 模型。DWS层完成了指标的汇总和维度的拓展,为报表提供了统一的数据来源。
三、ETL实践
本次项目采用了自研的一站式DataOps大数据管理平台,完成系统数据的抽取、加载和转换,以及定时任务的执行等。在数据分层标准之下,关于ETL实践主要完成了一些内容:
3.1 批量数据的导入
批量数据导入采用的是开源组件 DataX。自研的DataOps大数据管理平台在开源DataX的基础上做了很多封装,只需要创建数据同步任务,选择数据来源和数据目标表,即可自动生成字段映射和 DataX规范的Json配置文件。

图 2 - 启数道平台
在项目初期,Doris 未发布DataX 插件,仅通过原始的 JDBC 插入数据达不到性能要求。产品团队开发了 DataX 加速功能,先将对应数据抽取到本地文件,然后通过Stream Load方式加载入库,可以极大的提升数据抽取速度。数据读取到本地文件取决于网络宽带和本地读写性能,数据加载达到了 2000 千万数据 12.2G 仅需 5分钟的效果。
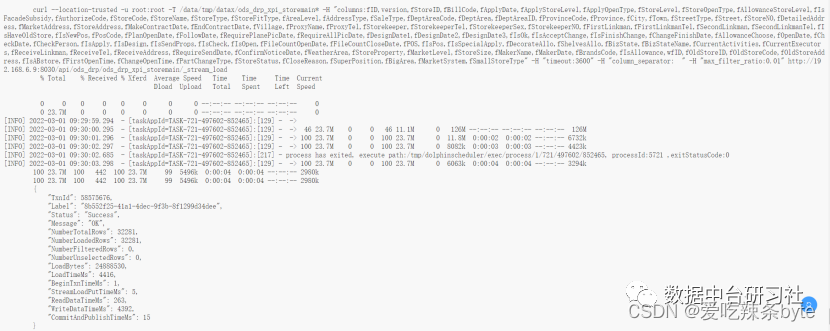
图 3 - DataX 加速
此外,DataX 数据同步还支持读取自定义 SQL 的方式,通过自定义 SQL 可以处理 SQL SERVER 这种数据库比较难解决的字符转换问题和偶尔出现的乱码字符问题。批量数据同步还支持增量模式,通过抽取最近 7 天的数据,配合 Doris 的主键模型,可以轻松解决大部分业务场景下的增量数据抽取。
3.2 实时数据接入
在实时数据接入方面,由于接入的实时数据都来自于阿里云的DRDS,所以采用的是 Canal+Kafka+Routine Load 模式。详细的配置就不展开了,环境搭建完成以后,只需要取Canal里面配置拦截策略,将表对应的流数据映射成Kafka Topic,然后去Doris创建 Routine Load 就 OK 了,这里举一个 Routine Load 的案例。
ALTER TABLE DS_ORDER_INFO ENABLE FEATURE "BATCH_DELETE";
CREATE ROUTINE LOAD t02_e3_zy.ds_order_info ON DS_ORDER_INFO
WITH MERGE
COLUMNS(order_id, order_sn, deal_code, ori_deal_code, ori_order_sn,crt_time = now(), cdc_op),
DELETE ON cdc_op="DELETE"
PROPERTIES
(
"desired_concurrent_number"="1",
"max_batch_interval" = "20",
"max_batch_rows" = "200000",
"max_batch_size" = "104857600",
"strict_mode" = "false",
"strip_outer_array" = "true",
"format" = "json",
"json_root" = "$.data",
"jsonpaths" = "[\"$.order_id\",\"$.order_sn\",\"$.deal_code\",\"$.ori_deal_code\",\"$.ori_order_sn\",\"$.type\" ]"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.87.107:9092,192.168.87.108:9092,192.168.87.109:9092",
"kafka_topic" = "e3_order_info",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING",
"property.group.id" = "ds_order_info",
"property.client.id" = "doris"
);3.3 数据加工
本次项目的数据加工是通过Doris视图来完成的。利用Doris优秀的索引能力,加上完善的SQL语法支持,即使再复杂的逻辑,也可以通过视图来实现。用视图加工数据,减少了代码发布的流程,避免了编译错误的问题,比Hive的脚本开发更加高效。
在完成模型设计以后,会确定模型表的命名、Key 类型等信息。完成表的创建以后,会创建表名 +"_v" 的视图,用于处理该表数据的逻辑加工。在大多数情况下,都是先清空目标表,然后从视图读取数据写入目标表的,所以我们的调度任务都比较简单,例如:
truncate table xtep_dw.dim_shop_info;
insert into xtep_dw.dim_shop_info
select * from xtep_dw.dim_shop_info_v;对于数据量特别大的读写任务,则需要分步写入。例如:
truncate table xtep_dw.dwd_god_allocation_detail_drp;
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2020-01-01' and '2020-06-30';
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2020-07-01' and '2020-12-31';
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2021-01-01' and '2021-06-30';
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2021-07-01' and '2021-12-31';
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2022-01-01' and '2022-06-30';
insert into xtep_dw.dwd_god_allocation_detail_drp
select * from xtep_dw.dwd_god_allocation_detail_drp_v
where UPDATE_DATE BETWEEN '2022-07-01' and '2022-12-31';但是视图开发的模式也是有一定的弊端的,比如不能做版本管理,也不便于备份。为此,我们承受了一次惨痛教训,在项目测试阶段,有同事在 dbwaver 客户端误操作 Drop 掉了 xtep_dw 数据库,导致我们花费了 3-4 天时间才恢复程序。因此我们紧急开发了 Python 备份程序:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import pymysql
import json
import sys
import os
import time
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
BACKUP_DIR='/data/cron_shell/database_backup'
BD_LIST=['ods_add','ods_cdp','ods_drp','ods_e3_fx','ods_e3_jv','ods_e3_pld','ods_e3_rds1','ods_e3_rds2','ods_e3_zy','ods_hana','ods_rpa','ods_temp','ods_xgs','ods_xt1','t01_hana','xtep_cfg','xtep_dm','xtep_dw','xtep_fr','xtep_rpa']
if __name__ == "__main__":
basepath = os.path.join(BACKUP_DIR,time.strftime("%Y%m%d-%H%M%S", time.localtime()))
print basepath
if not os.path.exists(basepath):
# 如果不存在则创建目录
os.makedirs(basepath)
# 连接database
conn = pymysql.connect(
host='192.168.xx.xx',
port=9030,
user='root',
password='****',
database='information_schema',
charset='utf8')
# 得到一个可以执行SQL语句的光标对象
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
for dbname in BD_LIST:
##生成数据库的文件夹
dbpath = os.path.join(basepath ,dbname)
print(dbpath)
if not os.path.exists(dbpath):
# 如果不存在则创建目录
os.makedirs(dbpath)
sql1 = "select TABLE_SCHEMA,TABLE_NAME,TABLE_TYPE from information_schema.tables where TABLE_SCHEMA ='%s';"%(dbname)
print(sql1)
# 执行SQL语句
cursor.execute(sql1)
for row in cursor.fetchall():
tbname = row[1]
filepath = os.path.join(dbpath ,tbname + '.sql')
print(u'%s表结构将备份到路径:%s'%(tbname,filepath))
sql2 = 'show create table %s.%s'%(dbname,tbname)
print(sql2)
cursor.execute(sql2)
for row in cursor.fetchall():
create_sql = row[1].encode('GB18030')
with open(filepath, 'w') as fp:
fp.write(create_sql)
# 关闭光标对象
cursor.close()
# 关闭数据库连接
conn.close()然后配合 Linux 的 Crontab 定时任务,每天三次备份代码。
#备份数据库,每天执行三次,8、12、18点各一次
0 8,12,18 * * * python /data/cron_shell/backup_doris_schema.py >>/data/cron_shell/logs/backup_doris_schema.log3.4 BI 查询
本次项目采用的前端工具是某国产 BI 软件和定制化开发的 E-Charts 大屏。该 BI 软件是基于数据集为中心去构建报表,并且支持灵活的数据权限管理。大多数据情况下基于SQL查询创建数据集,可以有效过滤数据。本次项目基于该BI 平台构建了 PC端报表(通过 App 适配手机也可以直接访问),并且新增了自助分析报表,同步开发了几张 E-Charts 大屏,实现大屏、中屏、小屏的统一。
数据查询对 Doris 来说是很容易,基本上建好表以后设置好索引,利用好 Bitmap ,性能就不会差。这里需要说明的上,在性能压力不大的情况下合理使用视图来关联多个结果集,可以减少跑批的任务和数据处理层级,有利于报表数据的快速刷新。在这方面,尽可能减少DWS和ADS层的聚合模型,减少大数据量的读写,尽可能复用逻辑代码和模型表,减少跑批时间,加强系统稳定性。
四、实时需求响应
在实时的需求方面,分别尝试了 Lambda 架构和 Kappa 架构,最后走出来项目特色的第三条线路——相同的视图逻辑,用不同的调度任务刷新不同范围的数据,实现流批代码复用。
项目早期是按照 Lambda 架构构建的任务,系统数据分为批处理和流处理两条线路,随着批处理的稳定,流处理数据的不准确性就逐步暴露。究其原因,业务系统存在数据物理删除和更新的情况,双流Join之后的数据准确性得不到保障。再有就是同时维护两套代码,实时逻辑的更新滞后,变更逻辑的代价也比较大。
项目后期,基于业务要求,尝试了把所有的零售逻辑搬迁到流处理平台,以实现流批一体,但是发现无法处理报表上常规要求本同期对比、维度数据变更和复杂条件过滤,导致搬迁工作半途而废。最后结合项目的实际情况,采用批处理和微批处理结合的方式,一套代码,两种跑批模式。T+1的链路执行最近6个月或者全量数据的刷新,微批处理流程刷新当日数据或者本周数据,实现数据的快速迭代更新。以 DWB层为例:
--批处理任务(每日夜间执行一次)
truncate table xtep_dw.dwb_ret_sales;
insert into xtep_dw.dwb_ret_sales
select * from xtep_dw.dwb_ret_sales_v;
--微批任务(白天8-24点每20分钟执行一次)
delete from xtep_dw.dwb_ret_sales where report_date='${curdate}';
insert into xtep_dw.dwb_ret_sales
select * from xtep_dw.dwb_ret_sales_v
where report_date='${curdate}';而 DWS 和 ADS 层的情况更为复杂,由于跑批频率太高,为了避免出现用户查看报表时刚好数据被删除的情况,采用分区替换的方式来实现数据的无缝切换。
--批处理任务(每日夜间执行一次)
truncate table xtep_dw.dws_ret_sales_xt_swap;
insert into xtep_dw.dws_ret_sales_xt_swap
select * from xtep_dw.dws_ret_sales_xt_v
where date_tag in ('本日','本周','本月','本年');
insert into xtep_dw.dws_ret_sales_xt_swap
select * from xtep_dw.dws_ret_sales_xt_v
where date_tag in ('昨日','上周','上月','上年');
ALTER TABLE xtep_dw.dws_ret_sales_xt REPLACE WITH TABLE dws_ret_sales_xt_swap;
--微批任务(白天8-24点每20分钟执行一次)
-- 分区替换的方式来实现数据的无缝切换
truncate table xtep_dw.dws_ret_sales_xt_swap;
insert into xtep_dw.dws_ret_sales_xt_swap
select * from xtep_dw.dws_ret_sales_xt_v
where date_tag in ('本日','本周');
ALTER TABLE xtep_dw.dws_ret_sales_xt ADD TEMPORARY PARTITION tp_curr1 VALUES IN ('本日','本周');
insert into xtep_dw.dws_ret_sales_xt TEMPORARY PARTITION (tp_curr1) SELECT * from xtep_dw.dws_ret_sales_xt_swap;
ALTER TABLE xtep_dw.dws_ret_sales_xt REPLACE PARTITION (p_curr1) WITH TEMPORARY PARTITION (tp_curr1);希望Doris 的分区替换还需要再完善一下,未来可以支持类似于 ClickHouse 的语法,即:ALTER TABLE table2 REPLACE PARTITION partition_expr FROM table1;
同时,由于设计了良好的分层架构,对于实时性要求特别高的数据,例如双十一大屏,可以直接从ODS层汇总数据导报表层,可以实现秒级的实时查询,对于实时性较高的业务,例如移动端实时日报,从DWD 或者 DWB 往上汇总数据,可以实现分钟级的实时;对于普通的自助分析或者固定报表,则按照灵活的频率更新数据,兼顾了二者的时效性和准确性。
五、其他经验
针对项目实施过程中出现的问题及相应的解决方案总结如下文。
5.1 Doris BE内存溢出
查询任务耗用的内存过大导致Doris BE挂掉的问题。采取的方法是所有表都创建 3 副本,然后给 Doris 进程配置 Supervisord 自启动进程,失败的任务通过调度平台的重试功能,一般都可以在 3 次重试机会以内跑过。
5.2 SQL任务超时
批处理过程中确实会有一些复杂的任务或者写入数据太多的任务会超时,除了调大 timeout 参数(目前设置为 10 分钟)以外,还把任务做了切分。前面的调度任务案例已经可以看到,有些写入的 SQL是按照分区字段或者日期区间来分批计算和写入的。
5.3 删除语句不支持表达式
删除语句不支持表达式,是Doris 后续需要优化的一个功能点。在Doris 无法实现的情况下,通过改造调度平台的参数功能,先计算好参数值,然后传入变量的方式实现了动态条件删除数据。前文的调度任务代码也有案例。
5.4 Drop 表闪回
误删除重要的表是数据仓库开发过程中比较常见的情况,表结构可以通过 Python 做好备份,但是表数据实在没有更好的办法。这里 Doris 提供了一个很好的功能——Recover 功能,误删除的表在 1 天以内可以支持闪回。
六、未来展望
目前Doris在特步集团的应用已经得到了用户的认可,接下来会基于现有的接口数据拓展到特步品牌 BI 应用,并且迁移更多的 HANA 数仓应用到 Doris 平台。
随着应用的深入,需要加强对 Doris 集群、Routine Load 和 Flink 任务的监控,及时发出异常预警,缩短故障恢复时间。同时,随着向量化引擎的逐步成熟和查询优化器的进一步完善,需要调整一些 SQL 写法,降低批处理对系统资源的占用,让集群更好的同时服务批处理和查询需求。当然,也期待社区在资源隔离方面可以有更进一步的完善。
参考文章:
应用实践 | 特步集团基于 Apache Doris 的零售数据仓库项目实践 - ApacheDoris的个人空间 - OSCHINA - 中文开源技术交流社区















 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









