







一、引言
论文:SRGAN:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network

github超火源码推荐:tensorlayer/SRGAN: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (github.com)
个人实站源码:fangshuiyun/SRGAN-Pytorch: SRGAN图像超分的Pytorch代码实现 (github.com)
也可以直接去看github上我写的README.md文件即可。
论文介绍:
"Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"(使用生成对抗网络进行照片级单图像超分辨率重建)是一篇在超分辨率领域里具有里程碑意义的研究,首次将生成对抗网络(GAN)应用于图像超分辨率问题。这篇论文由Christian Ledig等人撰写,发表在CVPR 2017上。主要的贡献点和工作包括:
原理:
1.SRGAN架构:论文中提出了超分辨率生成对抗网络(SRGAN),它被设计为由两部分组成:一个生成器(Generator)和一个判别器(Discriminator)。生成器负责将低分辨率的图像提升到高分辨率,而判别器则负责区分高分辨率图像是通过生成器生成的还是真实高分辨率图像。
2.感知损失函数:为了达到照片级的真实感,SRGAN不仅使用了传统的像素级损失函数(如MSE),更重要的是引入了感知损失(Perceptual Loss)。感知损失是基于预训练的VGG网络,通过比较特定层的特征图之间的差异,更侧重于图像的纹理和视觉内容。
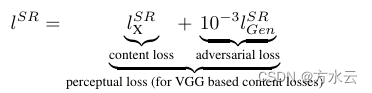
工作:
1.生成器:生成器网络使用了深度残差网络(Residual Network)框架,通过堆叠的残差块来学习低分辨率到高分辨率的映射。这有助于网络学习更复杂的图像特征,并且有利于梯度的传播,使网络训练更加稳定。
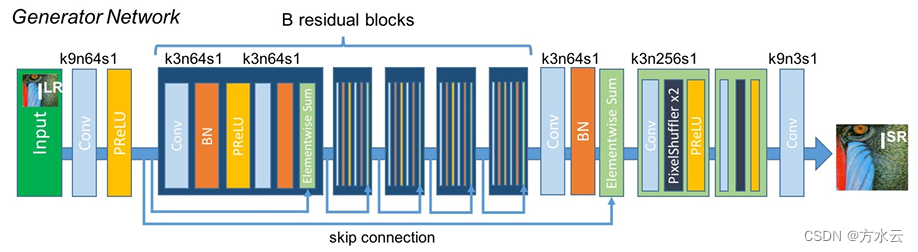
2.判别器:判别器网络的任务是对输入的高分辨率图像进行真伪分类。通过对抗性训练,判别器不断提高鉴别能力,推动生成器生成更加真实的高分辨率图像。
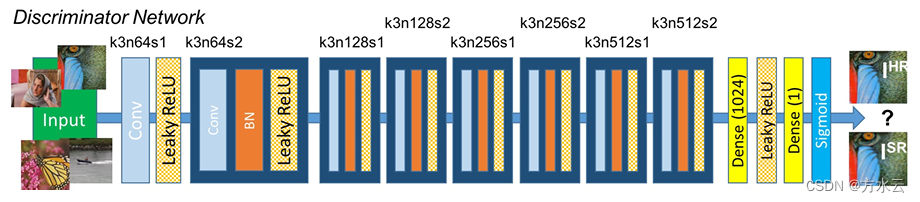
3.训练方法:训练过程中,首先固定判别器,更新生成器以最小化感知损失和对抗损失;然后固定生成器,更新判别器使其能够更精确地区分真实图像和生成图像。通过这种交替训练方式,生成器最终能够产生高质量、接近真实感的高分辨率图像。
二、代码实现
环境配置:
pytorch==1.10.0+cu102
torchaudio==0.10.0+cu102
torchvision==0.11.0+cu102
numpy==1.24.4
pandas==2.0.3
tqdm==4.66.1
Pillow==10.1.0
这是我的环境配置,其中关于PyTorch和Anaconda的安装,就不一一详述了,网上教程一大堆,我之前也发过应该如何安装的文章。
数据集:
我只下载了DIV2K_train_HR和DIV2K_valid_HR两个高分辨率图像文件,没有下载低分辨率图像的,至于低分辨率图像,我是直接通过高分辨率图像下采样得到的--不是很专业!玩一下嘛!
目录结构:
├─datasets
│ ├─DIV2K_train_HR
│ │ 0001.png
│ │ 0002.png
│ │ 0003.png
│ │ 0004.png
│ │ ......
│ └─DIV2K_valid_HR
│ 0801.png
│ 0802.png
│ 0803.png
│ 0804.png
│ │ ......整体的目录结构可以去github上细看!
代码:
main.py
代码里都有详细的注释标注,主要用于跑训练和验证,可以根据需求更改参数:train_dataset、valid_dataset、upscale_factor、epochs、batch_size。因为有两个网络:生成器和鉴别器,所以所需的显存较大,如果显存和其他资源不足,请参考github上README.md文件中我写的丐版训练计划的相关设置。
import argparse
import math
import time
import torch
import os
import pandas as pd
from tqdm import tqdm
from math import log10
from ssim import SSIM
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader
from loss import GeneratorLoss
from model import Discriminator, Generator
from process_dataset import PreprocessDataset
parser = argparse.ArgumentParser(description='Train Super Resolution Models')
parser.add_argument('--train_dataset', default="./datasets/DIV2K_train_HR", type=str,
help='训练集的图片路径')
parser.add_argument('--valid_dataset', default="./datasets/DIV2K_valid_HR", type=str,
help='测试集的图片路径')
parser.add_argument('--upscale_factor', default=4, type=int, choices=[2, 4, 8],
help='用于指定超分辨率的放大因子,默认为4')
parser.add_argument('--epochs', default=100, type=int, help='总训练轮数')
parser.add_argument('--batch_size', default=16, type=int, help='批次大小,显存不足可以调小一点')
if __name__ == '__main__':
print("-----------------------图像超分SRGAN!!!-----------------------")
# 解析命令行参数并将结果存储在变量agrs中
args = parser.parse_args()
#gpu还是cpu
if torch.cuda.is_available():
device = "cuda:0"
else:
device = "cpu"
#构建数据集
train_dataset = PreprocessDataset(args.train_dataset, args.upscale_factor)
#加快训练设置了<num_workers,pin_memory,drop_last>资源不足可以都删除掉
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=16, pin_memory=True, drop_last=True)
valid_dataset = PreprocessDataset(args.valid_dataset, args.upscale_factor)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=16, pin_memory=True)
# 创建生成器模型对象Generator,指定放大因子
netG = Generator(args.upscale_factor).to(device)
print(f'Generator Parameters Size:{sum(p.numel() for p in netG.parameters() if p.requires_grad) / 1000000.0 :.2f} MB')
#创建判别器
netD = Discriminator().to(device)
print(f'Discriminator Parameters Size:{sum(p.numel() for p in netD.parameters() if p.requires_grad) / 1000000.0 :.2f} MB')
# 创建生成器损失函数对象GeneratorLoss
generator_criterion = GeneratorLoss().to(device)
#ssim计算-pytorch.ssim亲测不好用
ssim = SSIM()
#构造迭代器
optimizerG = optim.Adam(netG.parameters(), lr=0.001)
optimizerD = optim.Adam(netD.parameters(), lr=0.001)
#学习率衰减策略
lf = lambda x:((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - 0.00001) + 0.00001
schedulerG = lr_scheduler.LambdaLR(optimizerG, lr_lambda=lf)
schedulerD = lr_scheduler.LambdaLR(optimizerD, lr_lambda=lf)
# 创建一个字典用于存储训练过程中的判别器和生成器的损失、分数和评估指标结果(信噪比和相似性)
results = {'d_loss': [], 'g_loss': [], 'd_score': [], 'g_score': [], 'psnr': [], 'ssim': []}
print("-----------------------初始化完成!!!开始训练!!!-----------------------")
for epoch in range(1, args.epochs + 1):
# 创建训练数据的进度条
start = time.perf_counter()
train_bar = tqdm(train_loader)
running_results = {'batch_sizes': 0, 'd_loss': 0, 'g_loss': 0, 'd_score': 0, 'g_score': 0}
netG.train() # 将生成器设置为训练模式
netD.train() # 将判别器设置为训练模式
for LR_img, HR_img in train_bar:
LR_img, HR_img = LR_img.to(device), HR_img.to(device)
batch_size = LR_img.size(0)
running_results['batch_sizes'] += batch_size
fake_img = netG(LR_img)
# 清除判别器的梯度
netD.zero_grad()
# 通过判别器对真实图像进行前向传播,并计算其输出的平均值
real_out = netD(HR_img).mean()
# 通过判别器对伪图像进行前向传播,并计算其输出的平均值
fake_out = netD(fake_img).mean()
# 计算判别器的损失
d_loss = 1 - real_out + fake_out
# 在判别器网络中进行反向传播,并保留计算图以进行后续优化步骤
d_loss.backward(retain_graph=True)
# 利用优化器对判别器网络的参数进行更新
optimizerD.step()
netG.zero_grad()
# The two lines below are added to prevent runtime error in Google Colab
# 通过生成器对输入图像(z)进行生成,生成伪图像(fake_img)
fake_img = netG(LR_img)
# 通过判别器对伪图像进行前向传播,并计算其输出的平均值
fake_out = netD(fake_img).mean()
# 计算生成器的损失,包括对抗损失、感知损失、图像损失和TV损失
g_loss = generator_criterion(fake_out, fake_img, HR_img)
# 在生成器网络中进行反向传播,计算生成器的梯度
g_loss.backward()
# 再次通过生成器对输入图像(z)进行生成,得到新的伪图像(fake_img)
fake_img = netG(LR_img)
# 通过判别器对新的伪图像进行前向传播,并计算其输出的平均值
fake_out = netD(fake_img).mean()
# 利用优化器对生成器网络的参数进行更新
optimizerG.step()
# 累加当前批次生成器的损失值乘以批次大小,用于计算平均损失
running_results['g_loss'] += g_loss.item() * batch_size
# 累加当前批次判别器的损失值乘以批次大小,用于计算平均损失
running_results['d_loss'] += d_loss.item() * batch_size
# 累加当前批次真实图像在判别器的输出得分乘以批次大小,用于计算平均得分
running_results['d_score'] += real_out.item() * batch_size
# 累加当前批次伪图像在判别器的输出得分乘以批次大小,用于计算平均得分
running_results['g_score'] += fake_out.item() * batch_size
# 更新训练进度条的描述信息
train_bar.set_description(desc='[train epoch-%d/%d] Loss_D: %.4f Loss_G: %.4f Score_D: %.4f Score_G: %.4f' % (
epoch, args.epochs, running_results['d_loss'] / running_results['batch_sizes'],
running_results['g_loss'] / running_results['batch_sizes'],
running_results['d_score'] / running_results['batch_sizes'],
running_results['g_score'] / running_results['batch_sizes']))
#一轮训练结束
end = time.perf_counter()
print(f"-----------------------第{epoch}轮训练的时长为:{(end - start):.2f}s,开始验证!-----------------------")
#开始验证本轮
netG.eval()
with torch.no_grad():
val_bar = tqdm(valid_loader)
valing_results = {'mse': 0, 'ssims': 0, 'psnr': 0, 'ssim': 0, 'batch_sizes': 0}
val_images = []
for val_lr, val_hr in val_bar:
val_lr, val_hr = val_lr.to(device), val_hr.to(device)
batch_size = val_lr.size(0)
valing_results['batch_sizes'] += batch_size
val_fake = netG(val_lr)
# 计算批量图像的均方误差
batch_mse = ((val_fake - val_hr) ** 2).data.mean()
# 累加均方误差
valing_results['mse'] += batch_mse * batch_size
# 计算批量图像的结构相似度指数
batch_ssim = ssim(val_fake, val_hr).item()
# 累加结构相似度指数
valing_results['ssims'] += batch_ssim * batch_size
# 计算平均峰值信噪比
valing_results['psnr'] = 10 * log10(
(val_hr.max() ** 2) / (valing_results['mse'] / valing_results['batch_sizes']))
# 计算平均结构相似度指数
valing_results['ssim'] = valing_results['ssims'] / valing_results['batch_sizes']
# 更新训练进度条的描述信息
val_bar.set_description(
desc='[valid epoch-%d] PSNR: %.4f dB, SSIM: %.4f, lr: %f' % (
epoch, valing_results['psnr'], valing_results['ssim'], optimizerG.state_dict()['param_groups'][0]['lr']))
#学习率更新
schedulerG.step()
schedulerD.step()
# 创建用于保存训练结果的目录
save_path = "./save_checkpoint"
if not os.path.exists(save_path):
os.makedirs(save_path)
# 将判别器和生成器的参数保存到指定文件
torch.save(netG.state_dict(), save_path+f'/netG_epoch_{args.upscale_factor}_{epoch}.pth')
torch.save(netD.state_dict(), save_path+f'/netD_epoch_{args.upscale_factor}_{epoch}.pth')
results['d_loss'].append(running_results['d_loss'] / running_results['batch_sizes'])
results['g_loss'].append(running_results['g_loss'] / running_results['batch_sizes'])
results['d_score'].append(running_results['d_score'] / running_results['batch_sizes'])
results['g_score'].append(running_results['g_score'] / running_results['batch_sizes'])
results['psnr'].append(valing_results['psnr'])
results['ssim'].append(valing_results['ssim'])
out_path = './statistics'
if not os.path.exists(out_path):
os.makedirs(out_path)
# 创建一个DataFrame对象,用于存储训练结果数据
data_frame = pd.DataFrame(
data={'Loss_D': results['d_loss'], 'Loss_G': results['g_loss'], 'Score_D': results['d_score'],
'Score_G': results['g_score'], 'PSNR': results['psnr'], 'SSIM': results['ssim']},
index=range(1, epoch + 1))
# 将DataFrame对象保存为CSV文件
data_frame.to_csv(out_path + '/train_results.csv', index_label='Epoch')
model.py
主要存放的是生成器和鉴别器模型,至于用于特征细节比对的VGG模型放在loss.py直接计算损失了。
import math
import torch
from torch import nn
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
# 二维卷积层,输入通道数为channels,输出通道数为channels,卷积核大小为3,填充为1
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels) # 二维批归一化层
self.prelu = nn.PReLU() # Parametric ReLU激活函数
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels) # 二维批归一化层
def forward(self, x):
# 应用对应的layer得到前向传播的输出(残差项)
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
return x + residual # 将输入x与残差项相加,得到最终输出
# 上采样块
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
# 卷积层,输入通道数为in_channels,输出通道数为in_channels * 2 ** 2,卷积核大小为3,填充为1
self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)
# 像素重排操作,上采样因子为up_scale
self.pixel_shuffle = nn.PixelShuffle(up_scale)
self.prelu = nn.PReLU()
def forward(self, x):
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
# 生成器模型
class Generator(nn.Module):
def __init__(self, scale_factor):
# 计算需要进行上采样的块的数量
upsample_block_num = int(math.log(scale_factor, 2))
super(Generator, self).__init__()
# 二维卷积层,输入通道数为3,输出通道数为64,卷积核大小为9,填充为4
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=9, padding=4),
nn.PReLU() # Parametric ReLU激活函数
)
self.block2 = ResidualBlock(64) # 定义(残差)ResidualBlock模块
self.block3 = ResidualBlock(64)
self.block4 = ResidualBlock(64)
self.block5 = ResidualBlock(64)
self.block6 = ResidualBlock(64)
self.block7 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64)
)
# 由多个UpsampleBlock模块组成的列表
block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)]
block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))
self.block8 = nn.Sequential(*block8) # 由block8列表中的模块组成的序列模块
def forward(self, x):
block1 = self.block1(x)
block2 = self.block2(block1)
block3 = self.block3(block2)
block4 = self.block4(block3)
block5 = self.block5(block4)
block6 = self.block6(block5)
block7 = self.block7(block6)
block8 = self.block8(block1 + block7)
# 将输出限制在0到1之间,通过tanh激活函数和缩放操作得到最终生成的图像
return (torch.tanh(block8) + 1) / 2
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
# 二维卷积层,输入通道数为3,输出通道数为64,卷积核大小为3,填充为1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2), # LeakyReLU激活函数
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
# 自适应平均池化层,将输入特征图转换为大小为1x1的特征图
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, kernel_size=1),
nn.LeakyReLU(0.2),
nn.Conv2d(1024, 1, kernel_size=1)
)
def forward(self, x):
# 输入批次的大小
batch_size = x.size(0)
# 使用torch.sigmoid函数将特征图映射到0到1之间,表示输入图像为真实图像的概率。
return torch.sigmoid(self.net(x).view(batch_size))
if __name__ == '__main__':
input = torch.rand([2, 3, 200, 200])
model = Generator(4)
out = model(input)
print(out.shape)process_dataset.py
主要是数据集的处理,对训练集和验证集Resize成400(不然显存不足),再进行训练。但对测试集来说,并不进行Resize处理,直接对原图进行测试,观察其性能指标。
import torch
import torchvision.transforms as transforms
from torch.utils.data import Dataset
import os
from PIL import Image
transform = transforms.Compose([
transforms.Resize(400),
transforms.CenterCrop(400), #显存不足就缩小图像尺寸
transforms.ToTensor() #显存不足就缩小图像尺寸
])
class PreprocessDataset(Dataset):
"""预处理数据集类"""
def __init__(self, HRPath, scale_factor):
"""初始化预处理数据集类"""
self.scale_factor = scale_factor
img_names = os.listdir(HRPath)
self.HR_imgs = [HRPath + "/" + img_name for img_name in img_names]
def __len__(self):
"""获取数据长度"""
return len(self.HR_imgs)
def __getitem__(self, index):
"""获取数据"""
HR_img = self.HR_imgs[index]
HR_img = Image.open(HR_img)
HR_img = transform(HR_img)
LR_img = torch.nn.MaxPool2d(self.scale_factor, stride=self.scale_factor)(HR_img) #将高分辨率下采样4倍,形成低分辨率
return LR_img, HR_img #返回低和高分辨率图片
class testPreprocessDataset(Dataset):
"""预处理数测试据集类,不进行Resize操作,进行原图的指标验证"""
def __init__(self, HRPath, scale_factor):
"""初始化预处理数据集类"""
self.scale_factor = scale_factor
img_names = os.listdir(HRPath)
self.HR_imgs = [HRPath + "/" + img_name for img_name in img_names]
def __len__(self):
"""获取数据长度"""
return len(self.HR_imgs)
def __getitem__(self, index):
"""获取数据"""
HR_img = self.HR_imgs[index]
HR_img = Image.open(HR_img)
HR_img = transforms.ToTensor()(HR_img)
LR_img = torch.nn.MaxPool2d(self.scale_factor, stride=self.scale_factor)(HR_img) #将高分辨率下采样4倍,形成低分辨率
return LR_img, HR_img #返回低和高分辨率图片
loss.py
计算各种损失:Adversarial Loss(对抗损失)、Perception Loss(感知损失)、Image Loss(图像损失)、TV Loss(总变差损失)。
import torch
from torch import nn
from torchvision.models.vgg import vgg16
class GeneratorLoss(nn.Module):
def __init__(self):
super(GeneratorLoss, self).__init__()
# 使用预训练的 VGG16 模型来构建特征提取网络
vgg = vgg16(pretrained=True)
# 选择 VGG16 模型的前 31 层作为损失网络,并将其设置为评估模式(不进行梯度更新)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
# 冻结其参数,不进行梯度更新
for param in loss_network.parameters():
param.requires_grad = False
self.loss_network = loss_network
# 定义均方误差损失函数: 计算生成器生成图像与目标图像之间的均方误差损失
self.mse_loss = nn.MSELoss()
# 定义总变差损失函数: 计算生成器生成图像的总变差损失,用于平滑生成的图像
self.tv_loss = TVLoss()
def forward(self, out_labels, out_images, target_images):
# Adversarial Loss(对抗损失):使生成的图像更接近真实图像,目标是最小化生成器对图像的判别结果的平均值与 1 的差距
adversarial_loss = torch.mean(1 - out_labels)
# Perception Loss(感知损失):计算生成图像和目标图像在特征提取网络中提取的特征之间的均方误差损失
perception_loss = self.mse_loss(self.loss_network(out_images), self.loss_network(target_images))
# Image Loss(图像损失):计算生成图像和目标图像之间的均方误差损失
image_loss = self.mse_loss(out_images, target_images)
# TV Loss(总变差损失):计算生成图像的总变差损失,用于平滑生成的图像
tv_loss = self.tv_loss(out_images)
# 返回生成器的总损失,四个损失项加权求和
return image_loss + 0.001 * adversarial_loss + 0.006 * perception_loss + 2e-8 * tv_loss
class TVLoss(nn.Module):
def __init__(self, tv_loss_weight=1):
super(TVLoss, self).__init__()
self.tv_loss_weight = tv_loss_weight
def forward(self, x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = self.tensor_size(x[:, :, 1:, :])
count_w = self.tensor_size(x[:, :, :, 1:])
# 计算水平方向上的总变差损失
h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
# 计算垂直方向上的总变差损失
w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
# 返回总变差损失
return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size
@staticmethod
def tensor_size(t):
# 返回张量的尺寸大小,即通道数乘以高度乘以宽度
return t.size()[1] * t.size()[2] * t.size()[3]
ssim.py
计算SSIM指标,输出在[0,1],越接近1代表两张图像越相似。因为试了一下pytorch_ssim,太老了不好用,所以自己弄了一个。
import torch.nn.functional as F
from math import exp
import torch
# 计算一维的高斯分布向量
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
return gauss / gauss.sum()
# 创建高斯核,通过两个一维高斯分布向量进行矩阵乘法得到
# 可以设定channel参数拓展为3通道
def create_window(window_size, channel=1):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
return window
# 计算SSIM
# 直接使用SSIM的公式,但是在计算均值时,不是直接求像素平均值,而是采用归一化的高斯核卷积来代替。
# 在计算方差和协方差时用到了公式Var(X)=E[X^2]-E[X]^2, cov(X,Y)=E[XY]-E[X]E[Y].
# 正如前面提到的,上面求期望的操作采用高斯核卷积代替。
def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
# Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
if val_range is None:
if torch.max(img1) > 128:
max_val = 255
else:
max_val = 1
if torch.min(img1) < -0.5:
min_val = -1
else:
min_val = 0
L = max_val - min_val
else:
L = val_range
padd = 0
(_, channel, height, width) = img1.size()
if window is None:
real_size = min(window_size, height, width)
window = create_window(real_size, channel=channel).to(img1.device)
mu1 = F.conv2d(img1, window, padding=padd, groups=channel)
mu2 = F.conv2d(img2, window, padding=padd, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2
C1 = (0.01 * L) ** 2
C2 = (0.03 * L) ** 2
v1 = 2.0 * sigma12 + C2
v2 = sigma1_sq + sigma2_sq + C2
cs = torch.mean(v1 / v2) # contrast sensitivity
ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
if size_average:
ret = ssim_map.mean()
else:
ret = ssim_map.mean(1).mean(1).mean(1)
if full:
return ret, cs
return ret
# Classes to re-use window
class SSIM(torch.nn.Module):
def __init__(self, window_size=11, size_average=True, val_range=None):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.val_range = val_range
# Assume 1 channel for SSIM
self.channel = 1
self.window = create_window(window_size)
def forward(self, img1, img2):
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.dtype == img1.dtype:
window = self.window
else:
window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
self.window = window
self.channel = channel
return ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)draw.py
根据训练结束生成的train_results.csv(包含每一轮的平均损失,平均分数,每一轮验证的PSNR,SSIM指标的数值)和测试结束生成的test_results.csv(包含每一张图像的的PSNR,SSIM指标的数值),生成曲线图。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def draw_train(path):
"""
:param path: train-csv路径
:return: null
"""
# 读取CSV文件
data = pd.read_csv(path)
# 设置图像大小
fig, axs = plt.subplots(2, 2, figsize=(12, 8))
# 绘制Loss_D和Loss_G
axs[0, 0].plot(data['Epoch'], data['Loss_D'], label='Loss_D')
axs[0, 0].plot(data['Epoch'], data['Loss_G'], label='Loss_G')
axs[0, 0].set_xlabel('Epoch')
axs[0, 0].set_ylabel('Loss')
axs[0, 0].set_title('Loss_D and Loss_G')
axs[0, 0].legend()
# 绘制Score_D和Score_G
axs[0, 1].plot(data['Epoch'], data['Score_D'], label='Score_D')
axs[0, 1].plot(data['Epoch'], data['Score_G'], label='Score_G')
axs[0, 1].set_xlabel('Epoch')
axs[0, 1].set_ylabel('Score')
axs[0, 1].set_title('Score_D and Score_G')
axs[0, 1].legend()
# 绘制PSNR
axs[1, 0].plot(data['Epoch'], data['PSNR'], label='PSNR')
axs[1, 0].set_xlabel('Epoch')
axs[1, 0].set_ylabel('PSNR')
axs[1, 0].set_title('PSNR')
axs[1, 0].legend()
# 绘制SSIM
axs[1, 1].plot(data['Epoch'], data['SSIM'], label='SSIM')
axs[1, 1].set_xlabel('Epoch')
axs[1, 1].set_ylabel('SSIM')
axs[1, 1].set_title('SSIM')
axs[1, 1].legend()
# 调整子图之间的间距
plt.subplots_adjust(hspace=0.5)
# 保存图像
plt.savefig('./image/train_results.png', dpi=300, bbox_inches='tight')
# 显示图像
plt.show()
def draw_test(path):
"""
:param path: test-csv路径
:return: null
"""
# 读取CSV文件
data = pd.read_csv(path)
# 剔除Average行
data = data[data['Image'] != 'Average']
# 重置索引
data = data.reset_index(drop=True)
# 创建一个新的图像
fig, axs = plt.subplots(1, 2, figsize=(16, 6))
# 绘制PSNR
axs[0].plot(data['Image'], data['PSNR'], color='y', label='PSNR')
axs[0].set_xlabel('Image')
axs[0].set_ylabel('PSNR')
axs[0].set_title('PSNR')
axs[0].set_xticks(np.arange(len(data))[::5]) # 每隔一个标记显示一次
axs[0].legend()
# 绘制SSIM
axs[1].plot(data['Image'], data['SSIM'], color='b', label='SSIM')
axs[1].set_xlabel('Image')
axs[1].set_ylabel('SSIM')
axs[1].set_title('SSIM')
axs[1].set_xticks(np.arange(len(data))[::5]) # 每隔一个标记显示一次
axs[1].legend()
# 保存图像
plt.savefig('./image/test_results.png', dpi=300, bbox_inches='tight')
plt.show()
draw_train("./statistics/train_results.csv")
draw_test("./statistics/test_results.csv")test.py
对数据集进行测试,我的测试集就是验证集(不专业玩一下),唯一不同的就是在测试阶段不对数据集进行Resize处理,进行原图的指标验证。
import argparse
from model import Generator
import torch
from tqdm import tqdm
from process_dataset import testPreprocessDataset
from torch.utils.data import DataLoader
from math import log10
from ssim import SSIM
import pandas as pd
import os
parser = argparse.ArgumentParser(description='Test Benchmark Datasets')
parser.add_argument('--test_dataset', default="./datasets/DIV2K_valid_HR", type=str,
help='测试集的图片路径')
parser.add_argument('--upscale_factor', default=4, type=int, choices=[2, 4, 8],
help='用于指定超分辨率的放大因子,默认为4')
parser.add_argument('--model_checkpoint', default='./save_checkpoint/netG_epoch_4_100.pth', type=str,
help='模型参数')
if __name__ == '__main__':
args = parser.parse_args()
if torch.cuda.is_available():
device = "cuda:0"
else:
device = "cpu"
# 加载训练好的模型参数
model = Generator(args.upscale_factor).eval().to(device)
model.load_state_dict(torch.load(args.model_checkpoint, map_location=device))
Ssim = SSIM()
# 加载测试数据集
test_dataset = testPreprocessDataset(args.test_dataset, args.upscale_factor)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=16, pin_memory=True)
# 创建一个用于 test_loader 的 tqdm 进度条
test_bar = tqdm(test_loader, desc='[testing benchmark datasets]')
# 保存每个测试数据集的结果
results = {'psnr': [], 'ssim': []}
num_img = len(test_dataset)
total_psnr = 0
total_ssim = 0
for test_lr, test_hr in test_bar:
test_lr, test_hr = test_lr.to(device), test_hr.to(device)
# 生成超分变率图像
test_fake = model(test_lr)
mse = ((test_hr - test_fake) ** 2).data.mean()
# 计算峰值信噪比(Peak Signal-to-Noise Ratio)
psnr = 10 * log10(255 ** 2 / mse)
# 计算结构相似性指数(Structural Similarity Index)
ssim = Ssim(test_fake, test_hr).item()
#
results['psnr'].append(psnr)
results['ssim'].append(ssim)
#
total_psnr += psnr
total_ssim += ssim
#每张图片的平均性能指标
avg_psnr = total_psnr/num_img
avg_ssim = total_ssim/num_img
data_frame = pd.DataFrame(data={'PSNR': results['psnr'], 'SSIM': results['ssim']},
index=range(1, num_img + 1))
# 在DataFrame的底部添加一行,仅包含平均的PSNR和SSIM值
avg_data_frame = pd.DataFrame(data={'PSNR': [avg_psnr], 'SSIM': [avg_ssim]},
index=["Average"])
# 将平均值的DataFrame追加至原来的DataFrame
final_data_frame = pd.concat([data_frame, avg_data_frame])
# 将DataFrame对象保存为CSV文件
out_path = './statistics'
if not os.path.exists(out_path):
os.makedirs(out_path)
final_data_frame.to_csv(out_path + '/test_results.csv', index_label='Image')
demo.py
直接去github上把我的模型参数下载下来就可以用自己的图片进行demo测试了。
import argparse
from model import Generator
import torch
from PIL import Image
import os
from torchvision.transforms import ToTensor, ToPILImage
parser = argparse.ArgumentParser(description='Test Single Image')
parser.add_argument('--upscale_factor', default=4, type=int, choices=[2, 4, 8],
help='用于指定超分辨率的放大因子,默认为4')
parser.add_argument('--image_path', default='./image/2.jpg', type=str,
help='图片路径')
parser.add_argument('--model_checkpoint', default='./save_checkpoint/netG_epoch_4_100.pth', type=str,
help='模型参数')
args = parser.parse_args()
device = "cpu"
# 加载训练好的模型参数
model = Generator(args.upscale_factor).eval().to(device)
model.load_state_dict(torch.load(args.model_checkpoint, map_location=device))
image = Image.open(args.image_path)
with torch.no_grad():
image = ToTensor()(image).unsqueeze(0).to(device)
print(image.shape)
out = model(image)
print(out.shape)
out_img = ToPILImage()(out[0].data.cpu())
out_img.show()
save_path = "./demo_result/"
file_name = os.path.basename(args.image_path)
if not os.path.exists(save_path):
os.makedirs(save_path)
img_save_path = save_path+file_name
out_img.save(img_save_path)
print("图像已保存到文件夹中。")三、结果
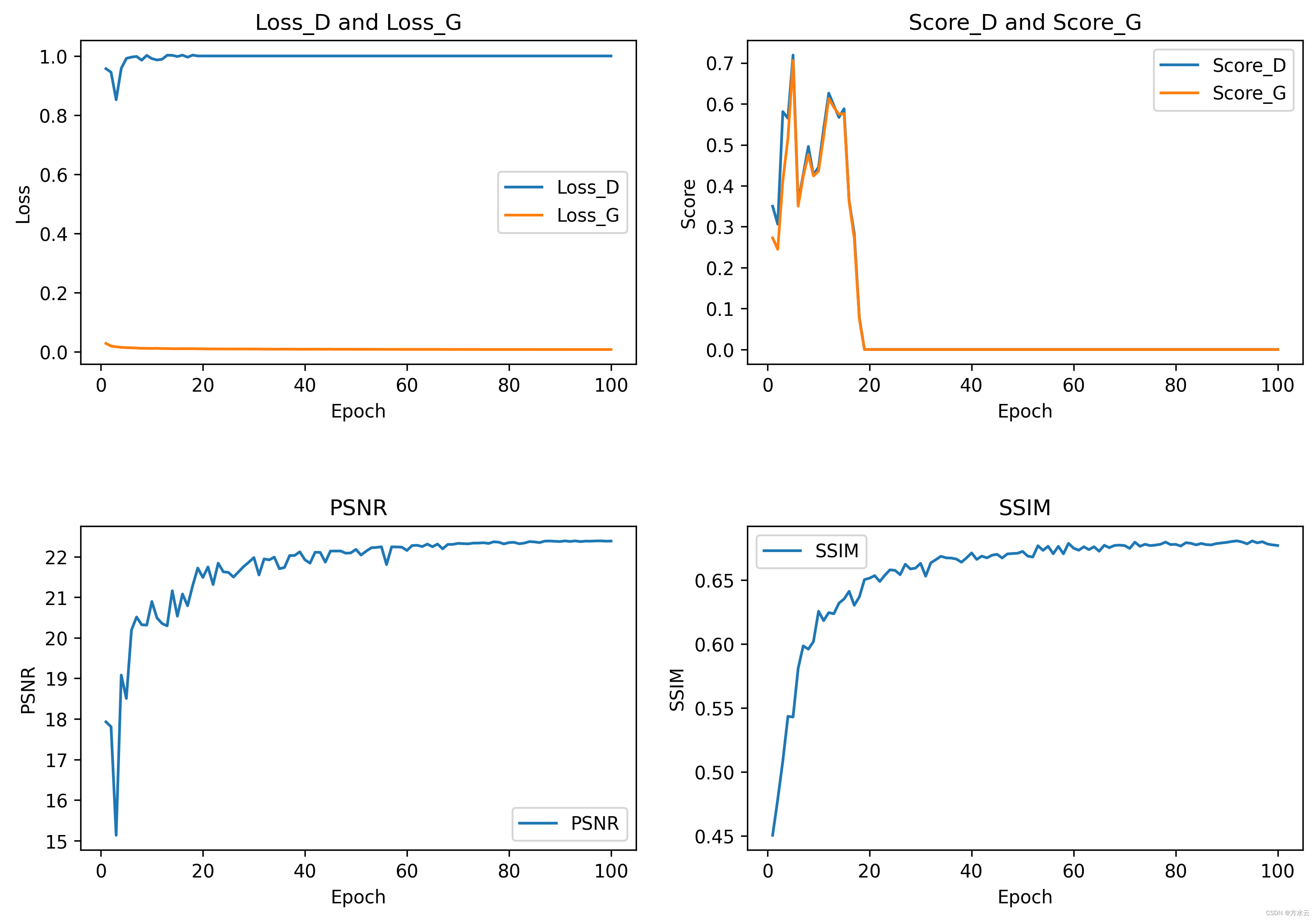
训练和验证的各项指标变化
PSNR:平均峰值信噪比(MSE越小,则PSNR越大;所以PSNR越大,代表着图像质量越好。);SSIM:平均结构相似度指数(0-1之间,1说明两张图一模一样)。
测试指标变化
一共99张图片,每张图片的PSNR和SSIM。
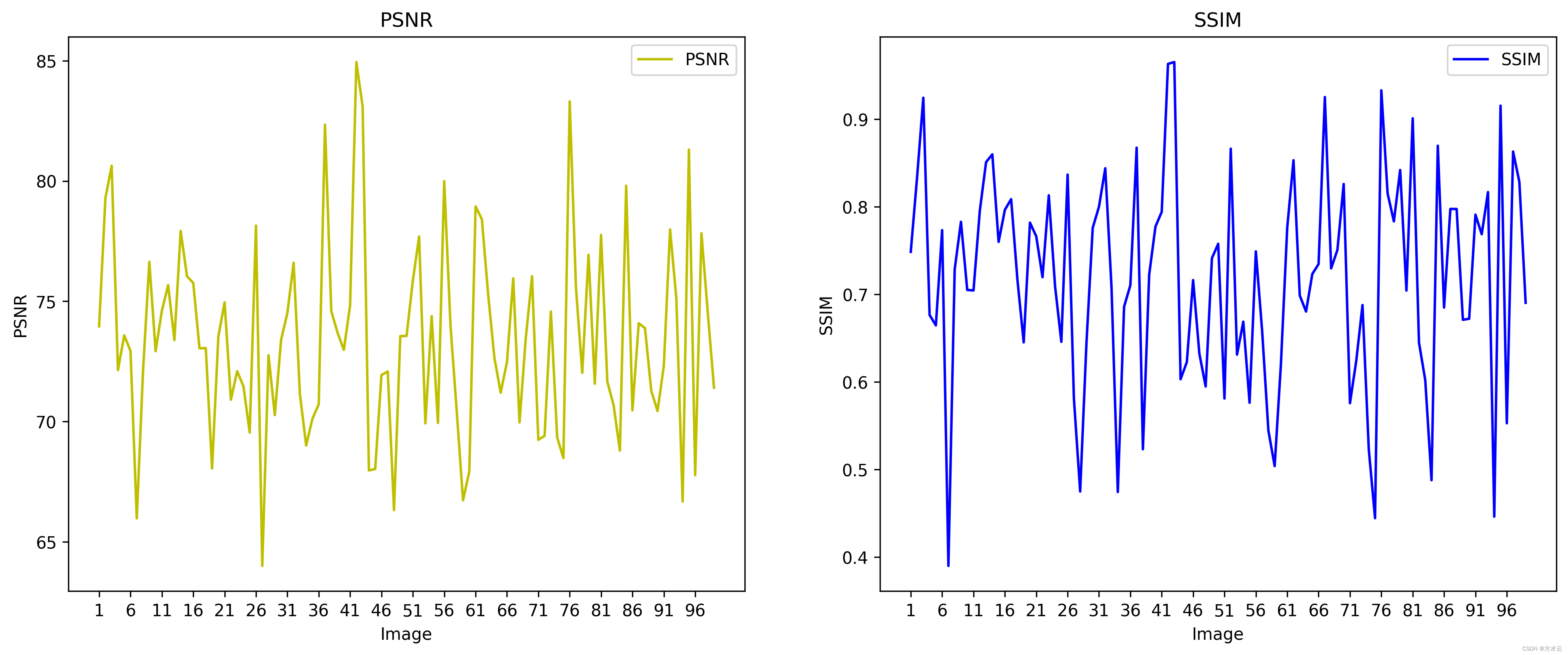
| 平均指标 | PSNR | SSIM |
| Average | 73.40 | 0.72 |
运行结果
再次说明运行demo.py即可进行图像超分的尝试!


左分辨率: 400×512 -> 右分辨率: 1600×2048


左分辨率: 300×629 -> 右分辨率: 1200×2516


左分辨率: 510×333 -> 右分辨率: 2040×1332


左分辨率: 510×288 -> 右分辨率: 2040×1152


左分辨率: 510×339 -> 右分辨率: 2040×1356
结果分析
优点:图像SR最广泛使用的优化目标是MSE,许多最先进的方法依赖于此。 然而,在实现特别高的PSNR的同时,MSE优化问题的解决方案通常缺乏高频内容, 这导致具有过度平滑纹理的感知上不满意的解决方案。论文提出了SRGAN,这是一个基于GAN的网络,针对新的感知损失进行了优化。 作者用基于VGG网络深度提取的特征图(激活层之后的)计算的损耗替换基于MSE的内容丢失,这对于像素空间的变化更加不变。此外,为了区分真实的HR图像和生成的SR样本, 作者还训练了一个鉴别器。
缺点:
1,作者在SRGAN网络中添加了许多BN层,BN层在训练期间使用batch中的均值和方差对特征进行规范化,在测试期间使用整个训练集的均值和方差。 在训练数据和测试数据差异很大时,BN层会引入伪影(从图像结果上看,确实图像的黑色阴影部分明显加深了),限制模型的泛化能力。
2,激活特征稀少,激活前的特征包含的信息更多,如下图所示。激活后使用特征会导致重建亮度与地面真实图像不一致。 该图出自《ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks》

完结撒花
点个赞呗!
















 4374
4374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









