




本课目录(== ==号围绕的为重要小节)
1.DQL(Data Query Language):
- 几个数据库语言中的最核心的语言。
- 数据库中所有简单的查询、复杂的查询都是用DQL。
- 使用频率极高。
2.实现过程:
2.1简单select查询及定义别名的语法
查询表的全部内容:
- SELECT * FROM
表名;
查询表中指定字段内容(未设置别称):
- SELECT
字段1名称,...,字段n名称FROM表名;
查询表中指定字段内容(设置别称):
- 有时候我们字段名称起的不是那么容易看懂,那么我们查询出来可能会造成阅读困难,所以此时我们可以使用 AS 关键字来给字段名起一个别称,方便阅读结果。
- SELECT
字段1名称AS别称,...,字段n名称AS别称FROM表名AS别称;
运用concat(a,b)数据库字符串拼接函数来融合查询指定字段(设置别称)。
- SELECT CONCAT(‘拼接内容’,
字段1名称) AS别称,..., CONCAT(‘拼接内容’,字段n名称) AS别称FROM表名AS别称;
CREATE DATABASE IF NOT EXISTS `school`;
USE `school`;
-- 年级表创建以及数据插入
DROP TABLE IF EXISTS `grade`;
CREATE TABLE `grade`(
`grade_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号',
`grade_name` VARCHAR(20) NOT NULL COMMENT '年级名称',
PRIMARY KEY (`grade_id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO `grade` (`grade_id`,`grade_name`)
VALUES (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'研究生');
-- 学生表创建以及数据插入
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student`(
`student_no` INT(4) NOT NULL COMMENT '学生学号',
`login_pwd` VARCHAR(20) DEFAULT NULL COMMENT '登陆密码',
`student_name` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',
`sex` TINYINT(1) DEFAULT NULL COMMENT '性别,0或1',
`grade_id` INT(11) DEFAULT NULL COMMENT '年级编号',
`tel` VARCHAR(50) DEFAULT NULL COMMENT '联系电话',
`address` VARCHAR(255) DEFAULT NULL COMMENT '地址',
`birthday` DATETIME DEFAULT NULL COMMENT '生日',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱账号',
`ID_number` VARCHAR(18) DEFAULT NULL COMMENT '身份证号码',
PRIMARY KEY (`student_no`),
UNIQUE KEY `ID_number`(`ID_number`),
KEY `email`(`email`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
INSERT INTO `student` (`student_no`,`login_pwd`,`student_name`,`sex`,
`grade_id`,`tel`,`address`,`birthday`,`email`,`ID_number`)
VALUES(1000,'123456','张三',0,2,'18888888888','火星','1900-1-1','text1@qq.com','123456789012345678'),
(1001,'123456','李四',1,3,'19999999999','水星','1901-1-1','text2@qq.com','098765432109876543');
-- 科目表创建以及数据插入
DROP TABLE IF EXISTS `subject`;
CREATE TABLE `subject`(
`subject_no` INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号',
`subject_name` VARCHAR(50) DEFAULT NULL COMMENT '课程名称',
`period` INT(4) DEFAULT NULL COMMENT '学时',
`grade_id` INT(4) DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (`subject_no`)
)ENGINE=INNODB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
INSERT INTO `subject`(`subject_no`,`subject_name`,`period`,`grade_id`)
VALUES(1,'高等数学',64,1),
(2,'C语言基础',64,1),
(3,'C++程序设计',64,1),
(4,'Java程序设计',64,1),
(5,'数据结构',64,1);
-- 成绩表创建以及数据插入
DROP TABLE IF EXISTS `result`;
CREATE TABLE `result`(
`student_no` INT(4) NOT NULL COMMENT '学生学号',
`subject_no` INT(11) NOT NULL COMMENT '课程编号',
`exam_date` DATETIME NOT NULL COMMENT '考试时间',
`student_result` INT(4) NOT NULL COMMENT '考试成绩',
KEY `subject_no`(`subject_no`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO `result`(`student_no`,`subject_no`,`exam_date`,`student_result`)
VALUES(1000,1,'2021-01-01 00:00:00',85),
(1000,2,'2021-01-01 00:00:00',86),
(1000,3,'2021-01-01 00:00:00',87),
(1000,4,'2021-01-01 00:00:00',88),
(1000,5,'2021-01-01 00:00:00',89);
-- 简单查询过程:
-- 查寻表全部内容。
SELECT * FROM `student`;
-- 查询指定字段(没有设置别称)。
SELECT `student_no`,`student_name` FROM `student`;
-- 查询指定字段(设置别称)。
SELECT `student_no` AS 学号,`student_name` AS 学生姓名 FROM `student`;
-- 运用concat(a,b)数据库字符串拼接函数来融合查询指定字段(设置别称)。
SELECT CONCAT('学号:',`student_no`) AS `学号`,CONCAT('姓名:',`student_name`) AS 学生姓名 FROM `student`;
2.2 去重以及据库的表达式语法
去重(distinct)
作用:去除SELECT查询结果中重复的数据,保留重复数据中的一条。
语法:SELECT DISTINCT
字段名1,字段nFROM表名;
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 统计此次参加考试了的人的学号。
SELECT `student_no` AS 学号 FROM `result`;
/*
执行下面这条查询语句会发现将1000学号的学生的考试结果都
查出来了,信息重复了,于是我们执行去重。
*/
SELECT DISTINCT `student_no` AS 学号 FROM `result`;
/*
执行去重过后的查询语句发现只显示一条1000,说明去重成功了。
*/
2.3 继续深入
我们在之前简单查询和去重之后我们可以知道:
- 在 SELECT
...FROM表名; 之间的...中的内容可以拓展。 - 于是SELECT语句的使用方法也就逐渐加深。
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 查询语句用来计算(表达式):
SELECT 1*2*3*4*5 AS 计算5的阶乘结果;
-- 查询语句用来查询自增步长(变量):
SELECT @@AUTO_INCREMENT_INCREMENT AS 自增步长;
-- 查询语句用来查询当前MySQL版本(函数):
SELECT VERSION() AS 当前MySQL版本;
综上可知:
-
算数表达式、系统变量、函数、NULL、列等等都是属于数据库中的表达式。
-
所以在 SELECT
...FROM表名; 之间的...中的内容可以拓展的内容非常多。 -
...中就可以是数据库的表达式。
所以SELECT
...FROM表名可以概括为:
- SELECT
数据库中的表达式[FROM表名];([]中内容可以省略)。
2.4 where 条件语句
-
通常情况下大家要做条件查询都是SELECT … WHERE …
-
那么我们来学习一下WHERE条件语句。
where条件语句之逻辑运算符:
| 运算符 | 描述 | 示例 |
|---|---|---|
| AND(&&) | 逻辑与 | 条件1 AND(&&) 条件2 |
| OR(||) | 逻辑或 | 条件1 OR(||) 条件2 |
| NOT(!) | 逻辑非 | NOT 条件 |
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 查询课程号码在2~4号的课程名称。
SELECT `subject_no` AS 课程编号,`subject_name` AS 课程名称 FROM `subject`
WHERE `subject_no`>=2 AND `subject_no`<=4;
-- 查询课程号码在2~4号的课程名称(模糊查询)。
SELECT `subject_no` AS 课程编号,`subject_name` AS 课程名称 FROM `subject`
WHERE `subject_no` BETWEEN 2 AND 4;
-- 查询除了课程编号为1的课程外的其他课程。
SELECT `subject_no` AS 课程编号,`subject_name` AS 课程名称 FROM `subject`
WHERE NOT `subject_no`=1;
模糊查询
| 运算符 | 描述 | 示例 |
|---|---|---|
| IS NULL | 操作符为空那么结果为真 | 条件1 IS NULL |
| IS NOT NULL | 操作符不为空那么结果为真 | 条件1 IS NOT NULL |
| LIKE | 两者匹配之后相等的话结果为真 | 条件1 LIKE 条件2 |
| BETWEEN | 若在区间内的话结果为真 | 条件1 BETWEEN 条件2 |
| IN | 若是区间内的某个值的话结果为真 | 条件1 IN (具体条件1,…,具体条件n) |
注:LIKE 经常与 % 和 _ 结合使用。
- %代表任意数量字符。
- _代表一个字符。
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 插入实验所需数据。
INSERT INTO `subject`(`subject_no`,`subject_name`,`period`,`grade_id`)
VALUES(6,'高等数学下册',62,2),
(7,'高等代数基础',60,3),
(8,'C++课程设计',32,4),
(9,'Java课程设计',30,5),
(10,'数据结构课程设计',60,6),
(11,'C++基础',64,6),
(12,'面向对象c++实现',60,6);
INSERT INTO `student` (`student_no`,`login_pwd`,`student_name`,`sex`,
`grade_id`,`tel`,`address`,`birthday`,`email`,`ID_number`)
VALUES(1003,'123456','王五',0,2,'18888888888','火星','1900-1-1','','234218273674826475'),
(1004,'123456','小六',1,3,'19999999999','水星','1901-1-1','','098765234509876543');
-- 插入邮箱为null的学生数据。
INSERT INTO `student` (`student_no`,`login_pwd`,`student_name`,`sex`,
`grade_id`,`tel`,`address`,`birthday`,`ID_number`)
VALUES(1005,'123456','七贤',0,2,'18888888888','火星','1900-1-1','231238273674826475');
-- 查询没有填邮箱的同学(邮箱为NULL默认值或者为''空字符串)。
SELECT `student_name` AS 没填邮箱的同学 FROM `student`
WHERE `email` IS NULL OR `email`='';
-- 查询邮箱信息不为空的同学。
SELECT `student_name` AS 有邮箱信息的同学 FROM `student`
WHERE `email` IS NOT NULL AND `email`!='';
-- 查询c++为开头的所有课程。
SELECT `subject_name` AS 课程名称,`period` AS 课程周期 FROM `subject`
WHERE `subject_name` LIKE 'c++%';
-- 查询c++基础这门课程,以及c++课程设计、c++程序设计这两门课程。
SELECT `subject_name` AS 课程名称,`period` AS 课程周期 FROM `subject`
WHERE `subject_name` LIKE 'c++__';
SELECT `subject_name` AS 课程名称,`period` AS 课程周期 FROM `subject`
WHERE `subject_name` LIKE 'c++____';
-- 查询课程名称中带 c 字段的所有课程。
SELECT `subject_name` AS 课程名称,`period` AS 课程周期 FROM `subject`
WHERE `subject_name` LIKE '%c%';
-- 查询课时周期为32,60,64的课程。
SELECT `subject_name` AS 课程名称,`period` AS 课程周期 FROM `subject`
WHERE `period` IN (32,60,64);
2.5 联表查询
join关键字
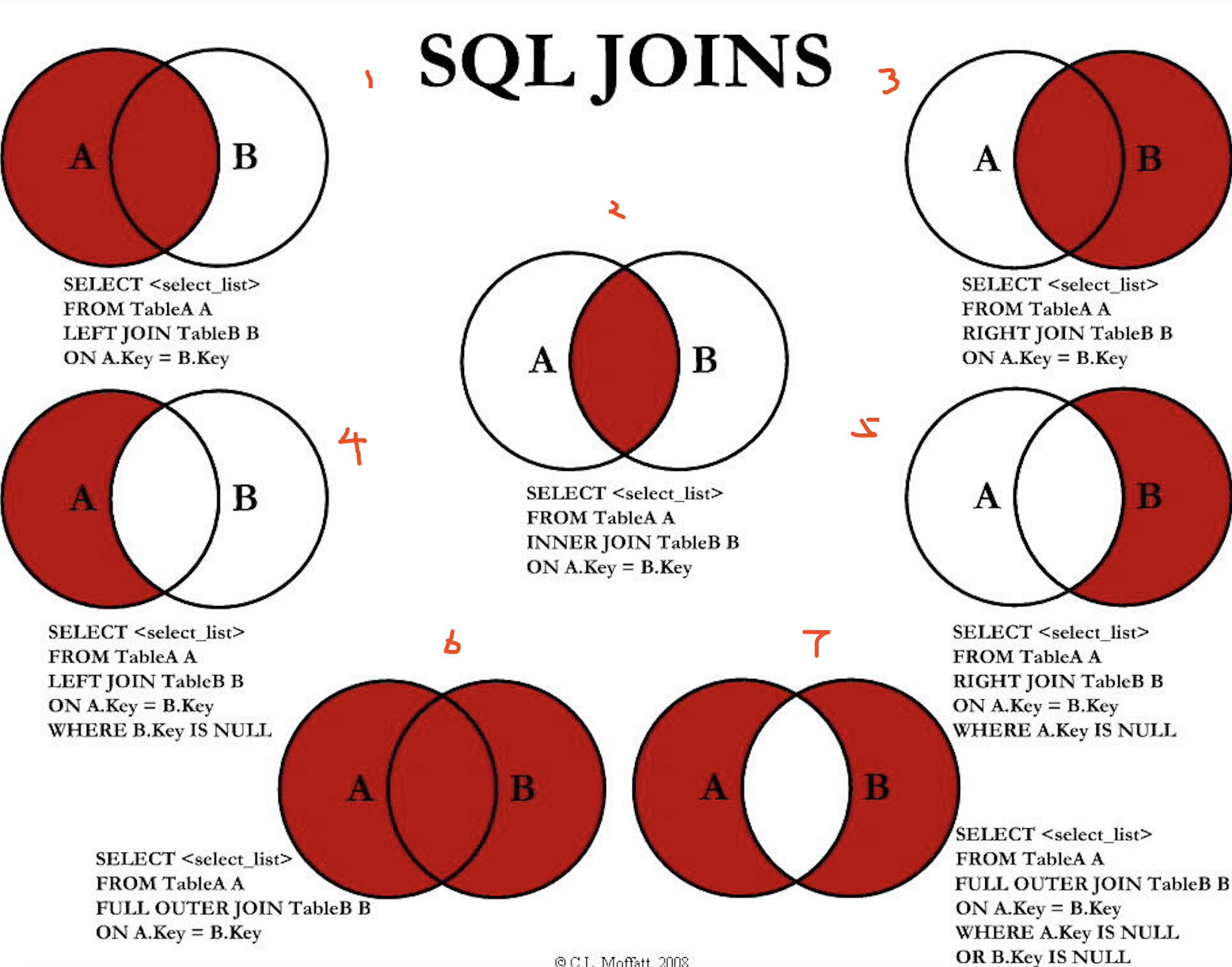
图片来源:
[]: https://www.cnblogs.com/huanchupkblog/p/7269246.html “七种join理论”
/*
联表查询的一般思路:
1.分析要查找的字段,确定提供字段的表,可能是多张。
2.确定join的连接方式(7种join理论)。
3.确定表与表的交叉点(一般用on)。
*/
-- 查询来自大二的学生,并且显示它们的年级编号,年级,学号,姓名。
-- 选择inner join
SELECT g.`grade_id`,`grade_name`,`student_no`,`student_no`,`student_name`
FROM student AS s INNER JOIN grade AS g
WHERE s.`grade_id` = g.`grade_id`;
SELECT g.`grade_id`,`grade_name`,`student_no`,`student_no`,`student_name`
FROM student s INNER JOIN grade g -- 这里可以忽略AS关键字
ON s.`grade_id` = g.`grade_id`;
-- 选择left join
SELECT g.`grade_id`,`grade_name`,`student_no`,`student_no`,`student_name`
FROM student s LEFT JOIN grade g
ON s.`grade_id` = g.`grade_id`;
-- 选择right join
SELECT g.`grade_id`,`grade_name`,`student_no`,`student_no`,`student_name`
FROM student s RIGHT JOIN grade g
ON s.`grade_id` = g.`grade_id`;
-- 查询还没有添加自己所在年级的同学的信息。
SELECT g.`grade_id`,`grade_name`,`student_no`,`student_no`,`student_name`
FROM student s LEFT JOIN grade g ON s.`grade_id` = g.`grade_id`
WHERE s.`grade_id` IS NULL;
-- 查询还没有学生的年级。
SELECT g.`grade_id`,`grade_name`
FROM student s RIGHT JOIN grade g ON s.`grade_id` = g.`grade_id`
WHERE s.`grade_id` IS NULL;
这就可以总结三个不同连接方式查找的区别:
这里我们要提一嘴ON和WHERE的区别了(没涉及原理啥和关键字作用的最直观的区别)。
- WHERE能用在INNER JOIN里但是别的方式不可以。
| 方式 | 描述 |
|---|---|
| LEFT JOIN | 会返回左表中所有满足要查询字段的数据,右表中没有匹配也返回。 |
| RIGHT JOIN | 会返回右表中所有满足要查询字段的数据,左表中没有匹配也返回。 |
| INNER JOIN | 查询字段都满足就返回一条记录,如果两表出现重复字段,就选择任意一张表的返回就可以。 |
加强!运用联表查询实现四张表的字段数据查询:
/*
查询学生姓名,年级名称,考试科目名称,考试分数(来自四张表,只查看完成考试的人)。
*/
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu LEFT JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
RIGHT JOIN `result` res ON stu.`student_no` = res.`student_no`
LEFT JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`;
-- 个人认为满足这个题目要求的sql语句连表都用inner join是最优解。
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu INNER JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`;
/*
查询学生姓名,年级名称,考试科目名称,考试分数(来自四张表,未完成考试的人也要显示)。
*/
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu LEFT JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
LEFT JOIN `result` res ON stu.`student_no` = res.`student_no`
LEFT JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`;
/*
查询学生所在年级以及学生信息(年级,学号,姓名)
*/
SELECT `grade_name` AS 年级名称,`student_no` AS 学生学号,`student_name` AS 学生姓名
FROM `student` AS s INNER JOIN `grade` g ON s.`grade_id`=g.`grade_id`;
/*
查询每个年级的所属科目(年级名称,科目名称)
*/
SELECT `grade_name` AS 年级,`subject_name` AS 科目名称
FROM `subject` s RIGHT JOIN `grade` g ON s.`grade_id`=g.`grade_id`;
/*
结合上述sql语句可以看出,联表查询会变得十分复杂,但是唯一不变的就是
一步一步走的操作:
1.分析要查找的字段,确定提供字段的表,可能是多张。
2.确定join的连接方式(7种join理论)。
3.确定表与表的交叉点。
/*
注意:
- 联表查询这一块十分复杂,需要慢慢的去多敲多练。
2.5.1 自连接
自连接
-
同一张表自己和自己连接。
-
最重要的是找到字段之间的对应关系。
示例运用的表及数据:
DROP TABLE IF EXISTS `school`.`sort`;
CREATE TABLE `school`.`sort`(
`sort_id` INT(4) NOT NULL COMMENT '主类型编号',
`sort_extend_id` INT(4) NOT NULL COMMENT '该类型的父类型编号',
`sort_name` VARCHAR(10) NOT NULL COMMENT '类型名称',
PRIMARY KEY (`sort_id`)
)ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;
INSERT INTO `school`.`sort`(`sort_id`,`sort_extend_id`,`sort_name`)
VALUES('1','0','xxxx大学'),
('2','1','计算机科学与工程学院'),
('5','2','软件工程'),
('6','2','网络工程'),
('3','1','外国语学院'),
('7','3','日语'),
('4','1','经济管理学院'),
('8','4','经济学');
我们可以将上表信息划分成以下三张表,他们通过编号来完成层级对应。
- 学校表:
| 类型编号(sort_id) | 该类型的父类型编号(sort_extend_id) | 名称(sort_name) |
|---|---|---|
| 1 | 0(可看作无更高分类) | xxxx大学 |
- 学校层级下的学院表:
| 类型编号(sort_id) | 该类型的父类型编号(sort_extend_id) | 名称(sort_name) |
|---|---|---|
| 2 | 1 | 计算机科学与工程学院 |
| 3 | 1 | 外国语学院 |
| 4 | 1 | 经济管理学院 |
- 学院层级下的专业表:
| 类型编号(sort_id) | 该类型的父类型编号(sort_extend_id) | 名称(sort_name) |
|---|---|---|
| 5 | 2 | 软件工程 |
| 6 | 2 | 网络工程 |
| 7 | 3 | 日语 |
| 8 | 4 | 经济学 |
接下来我们的任务就是:查询学院对应的专业。
- 总结上面三张表我们可得抽象到查询成功之后显示的表的格式:
| 大学/学院 | 学院/专业 |
|---|---|
| xxxx大学 | 计算机科学与工程学院 |
| xxxx大学 | 外国语学院 |
| xxxx大学 | 经济管理学院 |
| 计算机科学与工程学院 | 软件工程 |
| 计算机科学与工程学院 | 网络工程 |
| 外国语学院 | 日语 |
| 经济管理学院 | 经济学 |
正式开始!!!:
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
思路:将一张表看成多张一样的表。
*/
SELECT a.`sort_name` AS 大学或学院,b.`sort_name` AS 学院或专业
FROM `sort` AS a,`sort` AS b
WHERE a.`sort_id`=b.`sort_extend_id`;
/*
翻译这段SQL:
选择查询的两个字段同为sort_name,给这两个相同的字段起不同的别名,
他们两个sort_name都来自同一张sort表,此时我们把sort表分开分别
起别名a和b(类似于一个类创建两个对象),然后找到a,b引用中的符合
我们查询结果需要的条件,运行即可。
*/
到目前为止,select语句的语法可以总结为:
-- [ ]中的内容代表可选,不是必要。
SELECT [DISTINCT] `字段名1` as 别名1, `...`, `字段名n` as 别名n
FROM `表1` [LEFT|RIGHT|INNER JOIN] `表n` ON 表与表交叉点 -- 联合查询(可选)。
[WHERE ...] -- 查询结果需要满足的条件。
2.6 分页和排序
排序关键字:order by
-
升序(ASC)
-
语法:
SELECT[DISTINCT]...
FROM...[LEFT|RIGTH|INNER JOIN]...[ON] [
WHERE...] [
ORDERBY排序字段名称ASC]
-
-
降序(DESC)
-
语法:
SELECT[DISTINCT]...
FROM...[LEFT|RIGTH|INNER JOIN]...[ON] [
WHERE...] [
ORDERBY排序字段名称DESC]
-
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 查询学生姓名,年级名称,考试科目名称,考试分数并且要求按分数降序排列(来自四张表,只查看完成考试的人)。
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu INNER JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`
ORDER BY res.`student_result` DESC;
-- 查询学生姓名,年级名称,考试科目名称,考试分数并且要求按分数升序排列(来自四张表,只查看完成考试的人)。
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu INNER JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`
ORDER BY res.`student_result` ASC;
分页关键字:limit
-
分页可以有效的缓解数据库压力。
-
语法:
-
SELECT[DISTINCT]...FROM...[LEFT|RIGTH|INNER JOIN]...[ON][
WHERE...][
ORDERBY排序字段名称ASC|DESC][
LIMIT索引起始下标,页面尺寸]
-
根据语法我们尝试SQL:
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 查询学生姓名,年级名称,考试科目名称,考试分数并且要求按分数升序排列(来自四张表,只查看完成考试的人)。
-- 新增条件:五条数据,分页,每页显示两条数据。
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu INNER JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`
ORDER BY res.`student_result` ASC
LIMIT 0,2;
/*
此时查询结果为升序排列后的前两条数据。
若要查询后三条数据,分别将LIMIT 之后的数据改为:
LIMIT 2,2;
LIMIT 4,2;
这样我们就可以总结出来一个规律:
n:当前页;
(n-1) * pagesize:索引起始下标;
pagesize:页面尺寸(一页显示多少条数据);
总页数 = 总的数据条数/页面大小 = (总的数据条数+(pagesize-1))/pagesize;
*/
接下来思考一下这个SQL的实现语句:
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
-- 向result表中多插入几个数据:
INSERT INTO `result`(`student_no`,`subject_no`,`exam_date`,`student_result`)
VALUES(1000,1,'2021-01-01 00:00:00',85),
(1000,2,'2021-01-01 00:00:00',86),
(1000,3,'2021-01-01 00:00:00',87),
(1000,4,'2021-01-01 00:00:00',88),
(1000,5,'2021-01-01 00:00:00',89),
(1001,1,'2021-01-01 00:00:00',78),
(1001,2,'2021-01-01 00:00:00',45),
(1001,3,'2021-01-01 00:00:00',87),
(1001,4,'2021-01-01 00:00:00',90),
(1001,5,'2021-01-01 00:00:00',94),
(1003,1,'2021-01-01 00:00:00',67),
(1003,2,'2021-01-01 00:00:00',74),
(1003,3,'2021-01-01 00:00:00',98),
(1003,4,'2021-01-01 00:00:00',37),
(1003,5,'2021-01-01 00:00:00',77);
-- 查询学生姓名,年级名称,考试科目名称,考试分数,分数在80分以上的人总共9人,5人一页。
SELECT `student_name`,`grade_name`,`subject_name`,`student_result`
FROM `student` stu INNER JOIN `grade` gra ON stu.`grade_id` = gra.`grade_id`
INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON sub.`subject_no`=res.`subject_no`
WHERE res.`student_result` BETWEEN 80 AND 100
ORDER BY res.`student_result` DESC
LIMIT 0,5;
2.7 嵌套查询和子查询
子查询
- 相当于在
WHERE...条件语句的...条件中再添加一条SELECT...查询语句。 - 类似于:
WHERE(SELECT...) ;这样。
接下来进行实际操作:
/*
紧接着上面实验简单查询所需创建的表以及数据继续往下写SQL
*/
/*
查询c语言基础的所有结果,包括:考生学号,科目编号,科目分数(降序)
*/
-- 使用联表查询的方法实现:
SELECT res.`student_no` AS 学号, res.`subject_no` AS 科目编号, `student_result` AS 分数
FROM `result` res INNER JOIN `subject` sub ON sub.`subject_no` = res.`subject_no`
WHERE sub.`subject_name` = 'c语言基础'
ORDER BY res.`student_result` DESC;
-- 使用子查询的方法实现:
SELECT res.`student_no` AS 学号, res.`subject_no` AS 科目编号, `student_result` AS 分数
FROM `result` res
WHERE res.`subject_no` = (
SELECT `subject_no`
FROM `subject` sub
WHERE sub.`subject_name` = 'c语言基础'
)
ORDER BY res.`student_result` DESC;
/*
这里查询的过程我们从最内层()开始分析,
先确定题目要我们查询的字段来源的表,总共找到两张,result表和subject表。
紧接着我们将要查的字段全部列出来,发现学号和分数是在result表中,科目编号是在subject表中,
这样下去我们就可以开始子查询了,
先查询到c语言基础对应的学科编号,然后运用这个学科编号去对应result表中的学科编号,即可完成查询。
注意:这里子查询的最外层查询字段必须要在一张表中,否则会查询失败。
*/
/*
查询学生学号,学生姓名(高等数学考试成绩在70分以上的)
*/
-- 使用联表查询的方法实现:
SELECT DISTINCT stu.`student_no` AS 学号, `student_name` AS 姓名
FROM `student` stu INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
INNER JOIN `subject` sub ON res.`subject_no` = sub.`subject_no`
WHERE res.`student_result` >= 70 AND sub.`subject_name` = '高等数学';
-- 使用子查询的方法实现:
-- 方式一(单层嵌套子查询):
SELECT DISTINCT stu.`student_no` AS 学号, `student_name` AS 姓名
FROM `student` stu INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
WHERE res.`student_result` >= 70 AND `subject_no` = (
SELECT `subject_no`
FROM `subject` sub
WHERE sub.`subject_name` = '高等数学'
);
-- 方式二(多层嵌套子查询):
SELECT DISTINCT stu.`student_no` AS 学号, `student_name` AS 姓名
FROM `student` stu
WHERE stu.`student_no` IN (
SELECT `student_no`
FROM `result` res
WHERE res.`student_result` >= 70 AND `subject_no` = (
SELECT `subject_no`
FROM `subject` sub
WHERE sub.`subject_name` = '高等数学'
)
)
/*
这里选用in关键字是因为,只要student表中student_no在result表嵌套查询返回的结果中存在
就打印数据。
*/
具体 IN 关键字的用法请查看本课 2.4 WHERE条件语句那一小节
2.8 常用函数:
2.8.1 数学运算类函数:
SELECT ABS(-1) AS 绝对值;
SELECT CEILING(0.5) AS 向上取整;
SELECT FLOOR(0.5) AS 向下取整;
SELECT SIGN(-2) AS 该数符号; -- 判断一个数的符号,正返回1,负返回-1,0返回0
SELECT RAND() AS 随机数; -- 范围:0~1
2.8.2 字符串类函数:
SELECT LOWER('HELLO,WORLD!') AS 大写转小写;
SELECT UPPER('hello,world!') AS 小写转大写;
SELECT CONCAT('Hello','world!') AS 字符串拼接;
SELECT REVERSE('HelloWorld!') AS 反转字符串;
SELECT CHAR_LENGTH('HelloWorld!') AS 字符数组长度; -- 返回字符数组(字符串)长度。
SELECT INSTR('HelloWorld!','W') AS w在字符串中的位置 -- 返回指定字符串开头第一个字符在原字符串中的索引。
/*
参数一:待操作字符串。
参数二:插入位置。
参数三:插入后替换的长度(长度为0就是纯纯的在插入位置插入不替换)。
参数四:待插入字符串。
*/
SELECT INSERT('HelloWorld!',6,5,'Dear');
SELECT INSERT('HelloWorld!',6,0,'Dear');
/*
参数一:待操作字符串。
参数二:待操作字符串中的要替换的部分。
参数三:替换后的字符串。
*/
SELECT REPLACE('HelloWorld!','World','Dear');
/*
参数一:待操作字符串。
参数二:截取位置索引。
参数三:截取长度。
*/
SELECT SUBSTR('HelloWorld!',6,6);
2.8.3 时间与日期函数:
SELECT CURRENT_DATE() AS 当前日期;
SELECT CURDATE() AS 当前日期;
SELECT LOCALTIME() AS 当前本地日期时间;
SELECT NOW() AS 当前日期时间;
SELECT YEAR(NOW()) AS 当前年份;
SELECT MONTH(NOW()) AS 当前月份;
SELECT DAY(NOW()) AS 当前日;
SELECT HOUR(NOW()) AS 当前小时;
SELECT MINUTE(NOW()) AS 当前分钟;
SELECT SECOND(NOW()) AS 当前秒;
-- 综合上面六个语句:
SELECT YEAR(NOW()) AS 当前年份, MONTH(NOW()) AS 当前月份, DAY(NOW()) AS 当前日,
HOUR(NOW()) AS 当前小时, MINUTE(NOW()) AS 当前分钟, SECOND(NOW()) AS 当前秒;
SELECT SYSDATE() AS 返回函数执行日期时间;
2.8.4 系统函数:
SELECT VERSION() AS 当前数据库版本;
SELECT USER() AS 当前系统用户;
SELECT SYSTEM_USER() AS 当前系统用户;
2.9 聚合函数(常用)
2.9.1 count函数:
-- count 函数主要用来查询记录条数。
/*
填入具体字段名称,他会计数拥有该字段的记录条数(该字段数据不为null)。
*/
SELECT COUNT(stu.`email`) FROM `student` stu;
/*
填入 * 号,他会计数该张表中所有记录条数(包括一些数据不完整的条目)。
*/
SELECT COUNT(*) FROM `student` stu;
/*
填入 1,他也会计数该张表中所有记录条数(包括一些数据不完整的条目)。
*/
SELECT COUNT(1) FROM `student` stu;
执行效率:
- 如果计数的列名(字段名)为主键,则count(字段名)比count(1)快。
- 如果计数的列名(字段名)不是主键,则count(1)比count(字段名)快。
- 如果表中拥有多个列并且没有主键的情况下,则count(1)比count(*)效率高。
- 如果表只一列(一个字段),则count(*)最快。
2.9.2 其他聚合函数:
-- 一些常用聚合函数
SELECT SUM(res.`student_result`) AS 总分
FROM `result` res;
SELECT AVG(res.`student_result`) AS 平均分
FROM `result` res;
SELECT MAX(res.`student_result`) AS 最高分
FROM `result` res;
SELECT MIN(res.`student_result`) AS 最低分
FROM `result` res;
知道该聚合函数之后我们来做一点题:
/*
查询一个学生的学号,姓名,所有该学生考试成绩之和。
*/
-- 在我们执行以下sql他会只显示一条语句,会把所有的考试成绩都加起来然后给一个学生。
SELECT stu.`student_no` AS 学号, stu.`student_name` AS 姓名, SUM(res.`student_result`) AS 总成绩
FROM `student` stu INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
-- 此时我们就加上group by 关键字通过学号字段来分组,这样结果就是根据学号来分组了。
SELECT stu.`student_no` AS 学号, stu.`student_name` AS 姓名, SUM(res.`student_result`) AS 总成绩
FROM `student` stu INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
GROUP BY stu.`student_no`
-- 此时我们再增加一个条件,那就是只显示总分大于390分以上的人的信息。
SELECT stu.`student_no` AS 学号, stu.`student_name` AS 姓名, SUM(res.`student_result`) AS 总成绩
FROM `student` stu INNER JOIN `result` res ON stu.`student_no` = res.`student_no`
GROUP BY stu.`student_no`
HAVING SUM(res.`student_result`) >= 390;
在以上这题不断深入的过程中我们可以得到SELEC语句的最终形态。
3.0 总结:
通过以上所有知识点,我们可以将SELECT查询语句结构完善为:
-- 其中[ ]内的内容是可选的。
SELECT `字段名1` [AS 别称1], ... ,`字段名n` [AS 别称n]
FROM `表名`
[LEFT|RIGHT|INNER JOIN `另一张表` ON `交叉点`]
[WHERE `结果满足条件`]
[GROUP BY `要分组查询的字段`]
[HAVING `分组后需要满足的条件`]
[ORDER BY `要排序字段名` ASC|DESC]
[LIMIT `索引起始下标`,`页面尺寸`]
2021.1.22
本文章是本人学习笔记,不进行任何商用所以不支持转载请理解,也请别拿去商用!
如果觉得对你有帮助那么欢迎你随时来回顾!
只为记录本人学习历程。
毕

















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









