







论文标题
CRAG – Comprehensive RAG Benchmark CRAG – 综合 RAG 基准
论文链接
CRAG – Comprehensive RAG Benchmark论文下载
论文作者
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yan, Chenyu Yang, Eting Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wang, Anuj Kumar, Wen-tau Yih, Xin Luna Dong
内容简介
本文介绍了综合 RAG 基准(CRAG),这是一个包含 4,409 个问答对和模拟 API 的事实性问答基准,旨在弥补现有 RAG 数据集在多样性和动态性方面的不足。CRAG 涵盖五个领域和八种问题类别,反映了从热门到长尾的实体流行度以及从数年到秒的时态动态。评估结果显示,尽管大多数先进的 LLM 在 CRAG 上的准确率仅为 34%,通过简单地添加 RAG,准确率仅提高至 44%。最先进的工业 RAG 解决方案在没有幻觉的情况下仅能回答 63% 的问题。CRAG 还揭示了在回答动态性高、流行度低或复杂性高的事实问题时,准确率显著降低,指明了未来的研究方向。该基准为 KDD Cup 2024 挑战奠定了基础,吸引了成千上万的参与者和提交。
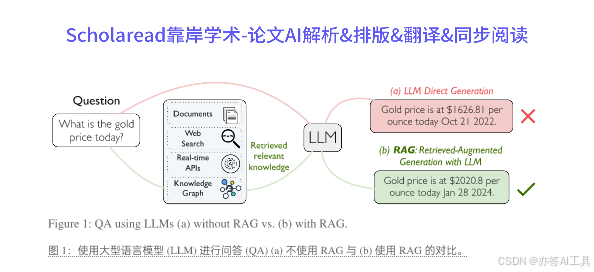
分点关键点
-
CRAG 数据集
- CRAG 包含 4,409 个问答对,涵盖金融、体育、音乐、电影和开放领域。数据集设计考虑了多种问题类型,包括简单问题、条件问题、比较问题等,确保了问题的多样性和现实性。
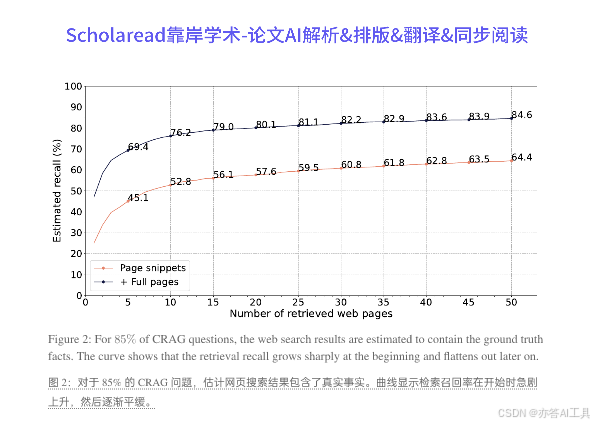
- CRAG 包含 4,409 个问答对,涵盖金融、体育、音乐、电影和开放领域。数据集设计考虑了多种问题类型,包括简单问题、条件问题、比较问题等,确保了问题的多样性和现实性。
-
RAG 解决方案的评估
- 评估机制设计了三项任务,分别测试 RAG 系统在检索摘要、知识图谱和网络检索、端到端检索增强生成方面的能力。通过区分幻觉答案和缺失答案,评估系统能够更准确地反映模型的性能。
-
现有基准的比较
- CRAG 与现有的问答基准相比,提供了更全面的覆盖和真实的测试环境,能够处理动态问题和多样化的事实流行度,强调了在真实世界场景中评估 RAG 系统的重要性。
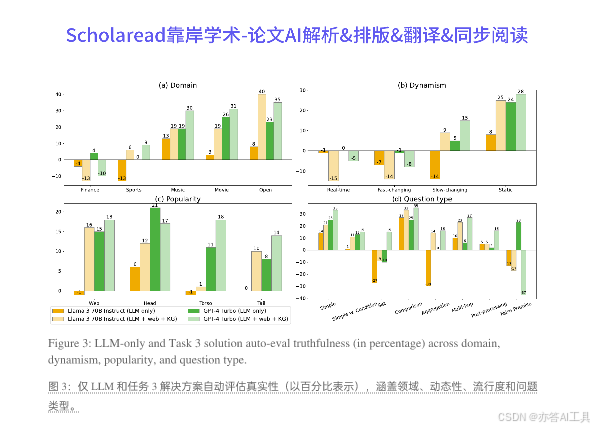
- CRAG 与现有的问答基准相比,提供了更全面的覆盖和真实的测试环境,能够处理动态问题和多样化的事实流行度,强调了在真实世界场景中评估 RAG 系统的重要性。
-
未来研究方向
- CRAG 的评估结果显示,当前 RAG 解决方案在处理动态性高、流行度低或复杂性高的问题时存在显著不足,指明了未来研究的方向,尤其是在提高模型的可靠性和准确性方面。
论文代码
代码链接:https://github.com/facebookresearch/CRAG/
中文关键词
- 综合 RAG 基准
- 问答系统
- 数据集
- 评估机制
- 动态性
- 实体流行度
- 未来研究方向
Neurlps2024论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









