







一、推导式
1. 列表推导式
生成一个从0到9的列表
这是不使用列表推导式的情况下:
num_list = []
for i in range(1,10):
num_list.append(i)
print(num_list)
使用列表推导式的情况下
num_list = [i for i in range(1,10)]
列表推导式分两种模式:
- 循环模式:[变量(加工的变量) for 变量 in iterable]
# 将10以内所有的整数的平方写入列表
print([i*i for i in range(1,11)])
# 100以内所有的偶数写入列表
print([i for i in range(2,101,2)])
# 从python1期到python100期写入列表lst 格式化输出的变量f'python{i}',就是加工的变量
print([f'python{i}' for i in range(1,101)])
- 筛选模式: [变量(加工的变量) for 变量 in iterable if 条件]
# 将这个列表中大于3的元素留下来
l1 = [4, 3, 2, 6, 5, 5, 7, 8]
print([i for i in l1 if i>3])
# 三十以内可以被三整除的数
print([i for i in range(1,30) if i%3==0])
# 过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母
l = ['xiaobai', 'lidada', 'aa', 'b', 'ggggg']
print([i.upper() for i in l if len(i)>3])
# 找到嵌套列表中名字含有两个‘e’的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
print([name for lst in names for name in lst if name.count('e')>=2])
2. 生成器推导式
# 生成器表达式
# 生成器表达式和列表推导式的语法上一模一样,只是把[]换成()就行了。比如将十以内所有数的平方放到一个生成器表达式中
gen = (i*i for i in range(1,11))
print(gen)
# 生成器表达式也可以进行筛选
# 获取1-100内能被3整除的数
gen = (i for i in range(1,100) if i % 3 == 0)
for num in gen:
print(num)
生成器表达式和列表推导式的区别:
1、列表推导式比较耗内存,所有数据一次性加载到内存。而.生成器表达式遵循迭代器协议,逐个产生元素。
2、得到的值不一样,列表推导式得到的是一个列表.生成器表达式获取的是一个生成器
3、列表推导式一目了然,生成器表达式只是一个内存地址。
无论是生成器表达式,还是列表推导式,他只是Python给你提供了一个相对简单的构造方式,因为使用推导式非常简单,所以大多数都会为之着迷,这个一定要深重,推导式只能构建相对复杂的并且有规律的对象,对于没有什么规律,而且嵌套层数比较多(for循环超过三层)这样就不建议大家用推导式构建。
生成器的惰性机制: 生成器只有在访问的时候才取值,说白了.你找他要才给你值.不找他要.他是不会执行的
3.字典推导式
# 字典推导式
#将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
#{10:'a' , 34:'b'}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
4.集合推导式
# 集合推导式
# 集合推导式可以帮我们直接生成一个集合,集合的特点;无序,不重复 所以集合推导式自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
二、迭代器
1.迭代器的概念
迭代器的概念:可迭代对象
字面意思就是 可以迭代取值的工具,
专业角度就是实现了无参数的__next__方法,返回序列中的下一个元素,如果没有元素了,那么抛出StopIteration异常.python中的迭代器还实现了__iter__方法,因此迭代器也可以迭代
在python中,内部含有'__Iter__'方法并且含有'__next__'方法的对象就是迭代器
o1 = 'hello'
o2 = [1, 2, 3]
o3 = (1, 2, 3)
o4 = {"a": 'b', "c": 'd'}
o5 = {1, 2, 3}
f = open('file', encoding='utf-8', mode='w')
print('__iter__' in dir(o1))
print('__iter__' in dir(o2))
print('__iter__' in dir(o3))
print('__iter__' in dir(o4))
print('__iter__' in dir(o5))
print('__iter__' in dir(f))
print('__next__' in dir(o1))
print('__next__' in dir(o2))
print('__next__' in dir(o3))
print('__next__' in dir(o4))
print('__next__' in dir(o5))
print('__next__' in dir(f))
执行结果:


str,list,tuple,dic,set 这些是可迭代对象
f=open 文件句柄是迭代器
2.可迭代对象转换为迭代器
# 可迭代对象转换为 迭代器
# 1、__iter__()
# 2、iter()
str = [1,2,3]
obj = str.__iter__()
print(obj)
obj1 = iter(str)
print(obj1)
执行结果:

3.迭代器取值
# 迭代器取值
# 可迭代对象是不可以一直迭代取值的(除去用索引,切片以及key),转换成迭代器后就可以了
l1 = [1, 2, 3]
obj = l1.__iter__() # 或者 iter(l1)
print(obj)
ret = obj.__next__()
print(ret)
ret = obj.__next__()
print(ret)
ret = obj.__next__()
print(ret)
ret = obj.__next__() # StopIteration 最后一个取不到了会报错
print(ret)
4.while模拟for的内部循环机制
# while模拟for的内部循环机制
# for循环的循环对象一定要是可迭代对象,但是这不意味着可迭代对象就可以取值,因为for循环的内部机制是:将可迭代对象转换成迭代器,然后利用next进行取值,最后利用异常处理处理StopIteration抛出的异常
l1 = [1, 2, 3]
# 1 将可迭代对象转化成迭代器
obj = iter(l1)
# 2,利用while循环,next进行取值
while 1:
# 3,利用异常处理终止循环
try:
print(next(obj))
except StopIteration:
break
执行结果:

5.迭代器的优缺点
# 迭代器的优点:
1、节省内存:迭代器在内存中相当于占了一个数据的空间,因为每次取值上一条的会在内存释放,加载当前的此条数据
2、惰性机制:next 一次取一个值,绝不夺取
有一个迭代器模式可以很好的解释上面这两条:迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式
# 迭代器的缺点:
# 1、不能直观的查看里面的数据
# 2、取值的时候不走回头路,只能一直向下取值。
可迭代对象:是一个私有的方法比较多,操作灵活(比如列表,字典的增删改查,字符串的常用操作方法等),比较直观,但是占用内存,而且不能直接通过循环迭代取值的这么一个数据集。
应用:当你侧重于对于数据可以灵活处理,并且内存空间足够,将数据集设置为可迭代对象是明确的选择。
迭代器:是一个非常节省内存,可以记录取值位置,可以直接通过循环+next方法取值,但是不直观,操作方法比较单一的数据集。
应用:当你的数据量过大,大到足以撑爆你的内存或者你以节省内存为首选因素时,将数据集设置为迭代器是一个不错的选择。(可参考为什么python把文件句柄设置成迭代器)
三、生成器
1.生成器的概念
# 1、一个包含了yield关键字的函数就是一个生成器,该函数也叫生成器函数
# 2、当生成器函数被调用时,在函数体中的代码不会被执行,而会返回一个迭代器。每次请求一个值,就会执行生成器中代码,直到遇到一个yield表达式或return语句
# 3、yield表达式表示要生成一个值,return语句表示要停止生成器。换句话说,生成器是由两部分组成,生成器的函数和生成器的迭代器。
# 生成器的函数是用def语句定义的,包含yield部分;生成器的迭代器是这个函数返回的部分。二者合起来叫做生成器
2.生成器的创建方式
1、通过生成器函数
2、通过生成器推导式
3、python内置函数或者模块提供(其实1,3两种本质上差不多,都是通过函数的形式生成,只不过1是自己写的生成器函数,3是python提供的生成器函数而已)
# Python中提供的生成器
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
# 本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
#
# 特点:惰性运算,开发者自定义
# 生成器函数
# 一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束
3.普通函数和生成器函数的区别
# 普通函数
def func():
print('普通函数')
return 2
ret = func()
print(ret)
#生成器函数 # 将函数中的return换成yield,这样func就不是函数了,而是一个生成器函数
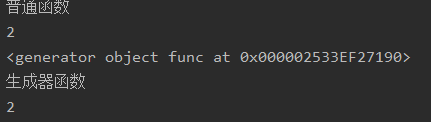
def func():
print('生成器函数')
yield 2
ret = func() # 这个时候函数不会执⾏,⽽是获取到⽣成器
print(ret) # <generator object func at 0x000001F62F9E7190>
print(next(ret)) # 通过next(ret)或ret.__next__()执⾏,并且yield会将func生产出来的数据 2给了ret
执行结果:
4. yield与return的区别
# 1、return一般在函数中只设置一个,他的作用是终止函数,并且给函数的执行者返回值。
#
# 2、yield在生成器函数中可设置多个,他并不会终止函数,next会获取对应yield生成的元素。
5.生成器的 send方法
# next只能获取yield生成的值,但是不能传递值。
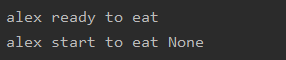
def gend(name):
print(f"{name} ready to eat")
while 1:
food = yield
print(f'{name} start to eat {food}')
dog = gend('alex')
next(dog)
next(dog)
执行结果:
# 使用send这个方法传递值
def gend(name):
print(f"{name} ready to eat")
while 1:
food = yield 222
print(f'{name} start to eat {food}')
dog = gend('alex')
next(dog) # 第一次必须用next让指针停留在第一个yield后面
# 与next一样,可以获取到yield的值
ret = dog.send('骨头')
print(ret)
执行结果:

6.send和next()区别
# 相同点:
# 1、send 和 next()都可以让生成器对应的yield向下执行一次。
# 2、都可以获取到yield生成的值。
# 不同点:
# 1、第一次获取yield值只能用next不能用send(可以用send(None))。
# 2、send可以给上一个yield置传递值
7.yield from
# 在python3中提供一种可以直接把可迭代对象中的每一个数据作为生成器的结果进行返回
# 对比yield 与 yield from
def func():
lst = [1,3,4,5]
yield lst
ret = func()
print(ret)
print(next(ret)) # 只是返回一个列表
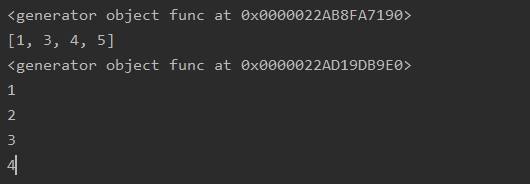
def func():
lst = [1,2,3,4]
yield from lst
g = func()
print(g)
# # 他会将这个可迭代对象(列表)的每个元素当成迭代器的每个结果进行返回。
print(next(g))
print(next(g))
print(next(g))
print(next(g))
执行结果:
# yield from 是将列表中的每一个元素返回, 所以
# 如果写两个yield
# from 并不会产生交替的效果
def func():
lst1 = [1, 2, 3, 4]
lst2 = [5, 6, 7, 8]
yield from lst1
yield from lst2
g = func()
for i in g:
print(i)
执行结果:















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









