







 本文深入浅出地介绍了决策树算法的基本原理,包括信息熵、信息增益、基尼指数等核心概念,阐述了如何利用这些指标进行特征选择,构建高效的决策树模型。
本文深入浅出地介绍了决策树算法的基本原理,包括信息熵、信息增益、基尼指数等核心概念,阐述了如何利用这些指标进行特征选择,构建高效的决策树模型。
先举一个简单的例子理解一下决策树算法:父母为孩子选择学校,会了解多个学校的教学水平、学校设施等“条件”,假设有一家有足够选择能力的父母认为教学水平是第一位的,而设备等次之,且将教学水平分为了一般、较好、优良三个档次,对于教学水平一般者不予考虑,优良者趋之若鹜,而较好者则根据其学校设施好坏决定去留。这个例子可以表示为如下的树形结构,这一思路也就称为“决策树”。
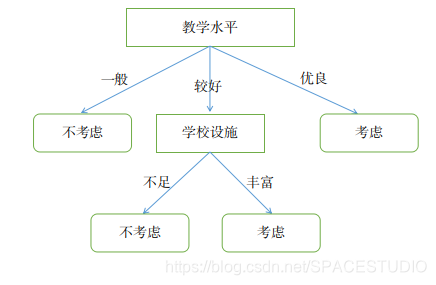
图1 “择校”决策树
除掉不需学习的KNN算法之外,决策树算法应该算是机器学习十大算法中最容易理解的。宏观地看来,决策树算法与二分查找颇有相似之处,二分查找在一维的特征集上根据结果(值)查找特征(索引),而决策树则在多维特征空间上根据特征查找结果,通过对多个特征的值逐层进行划分将待测数据化分到一个唯一确定的结果(类别)中;二分查找根据寻找中位的值划分两个大小相等的子集,而决策树算法根据特征的每个取值划分不等的子集;二分法选择与结果距离较小的子集继续“二分”,而决策树算法则选择与原数据集信息增益较大的子集继续“决策”。二分查找算法也可用于上面的例子中,该父母已将几个备选的学校按照教学水平排好位次,对于新了解到的学校,如果其教学水平好于已有的多数学校则继续考虑,否则放弃,这个过程就需要进行中位查找与划分,可以看作二分法的应用。
对于二分法来说,只需找到子集的中位数便可以作比较、继续划分,而决策树中,具有多个特征,每个特征又都有不同的取值,如何依次选择特征来缩小考虑范围从而更快速、准确地得到结果就成为了决策树算法中最关键的问题。所以提到决策树,就不得不先理解信息熵、信息增益这些概念。
正文开始,目录如下:
一、特征选择
1.1 熵(Entropy)
熵这一概念在物理学中表示体系的混乱程度,克劳德香农将其引入信息论中表示“信息”的混乱程度,定义为信息的期望值,记作H。可以从下面几个概念加以理解:
1)信息量
可以从信号的角度理解信息的“混乱”。如果一个信源只发出一种信号,那么认为其不能传递信息,即信息量=0;而如果信号变化丰富,则认为信息量较大。若某一消息出现的概率较低,则该消息出现时获得的信息量较大。从而,信息量与消息出现概率负相关,且具有可加性。
2)自信息
自信息是对事件不确定性的度量,即单一事件发生时包含的信息量的多少。根据信息量的概念,定义表示消息x的自信息。
3)信息熵
自信息衡量单个的信号输出,而信息熵用来定量描述信息的大小,定义为自信息的期望值。所以,接近确定的分布具有较低的信息熵,而接近平均分布的样本的信息熵则较高。对一个有限个取值的随机变量X,若其概率分布为,则该随机变量的熵为:
。
如下面两个随机变量中,B的随机程度远远大于A,所以其熵也远大于A。计算验证:A中有两个取值1和2,其概率分别为0.4和0.1,所以其熵;B中有9个取值,其概率分别为0.2,0.1...0.1,所以
。可以发现,熵与随机变量的取值无关,只与每个取值的概率有关。
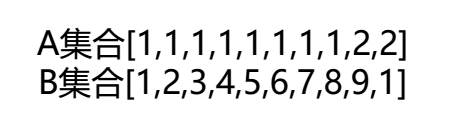
在上面的计算中,取自然对数e作为底。通常定义是以2为底的,计算出来的信息熵单位为比特(bit)。
1.2 信息增益(Information Gain)
在决策树算法中,根据给定的训练集,按照其标签的取值可以计算其熵。如果选择某一特征,按照这一特征的n个取值将数据集分为n部分,求得每部分的熵并加权求和,则得到划分之后整个数据集的熵,此时的熵仍通过原来的标签取值计算,但却受到该特征取值及分布的影响,称为条件熵。这两个熵之间的差值,代表着使用该特征划分数据集对数据集(标签)的熵带来的变化,称为信息增益。
1)条件熵
在概率论中,条件概率表示某事件在另一事件已经发生的条件下发生的概率。在信息论中,条件熵则用来表示某一随机变量在另一随机变量的分布已知的条件下的不确定度(熵),即X给定条件下,Y的条件概率分布的熵对X的数学期望。其定义如下:,表示已知随机变量X的条件下随机变量Y的熵。
在决策树中,代表着已知某一特征取值的分布情况,按此划分数据集所得到的熵。
2)信息增益(互信息)
衡量某一特征对分类结果影响的大小,定义为数据集D的熵H(D)与特征A给定的条件下D的条件熵之差,也成为互信息。记作g(A),有。
对于待划分数据集D,其熵固定,但根据不同特征进行划分后所得的条件熵不同。条件熵与原熵的差即为信息增益。信息增益越大,代表该特征划分后的子集不确定性越小、纯度越高,对分类影响大。如开头的例子中,若教学水平一般,则直接不考虑。
3)信息增益比
由于采用信息增益作为特征选择标准容易使得算法选择那些拥有较多取值的特征,所以定义信息增益比为特征A带给数据集D的信息增益与特征(随机变量)A本身的熵之比,即,其中
,n为特征A的取值个数,
表示数据集中A特征取值为i的数据个数。
可以将信息增益比看做为了避免首先选择取值较多而无意义的特征(如日期、ID等)而给信息增益乘上一个惩罚项,惩罚参数为,从而特征取值较多(特征的熵相对大)时,惩罚参数较小,信息增益比较小;特征取值较少时,信息增益比较大。
1.3 基尼指数(Gini)
基尼指数源自经济学概念,亦称基尼不纯度,表示在数据集中随机选择一个样本,该样本被分类错误的概率。即基尼指数=选中该样本的概率该样本被分类错误的概率。假设数据集有K个类别,则某样本点属于第k类的概率为
,其该数据集的基尼指数定义为:
。
同样的,需要使用特征来划分数据集。对于特征A的某个取值a,我们仅判断样本的该特征取值是否为a,所以基尼指数的计算实际为一个二分类问题,也导致根据基尼指数生成的树模型都为二叉树。给定特征A的条件下,集合D的基尼指数定义为,
为按某个取值将数据集划分为两个子集,
表示经过A=a分割后数据集D的不确定性。
使用基尼指数构建决策树时,同样选择为数据集带来最大的基尼指数“增益”的特征和取值来逐层划分数据集。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









