







暑期实习在公司太无聊刷知乎,刷到一篇Java学到什么程度才能叫精通?
看了看感觉大部分都答不上来,发现自己基础太薄弱,决定依照上面的内容作为指导路线补一补Java。


利用了一天的摸鱼时间,完成了基础模块的一半的内容。主要是通过浏览前辈们的博客来学习,以下是整理出来的知识点。

1、JDK 和 JRE 有什么区别?
- JRE: Java Runtime Environment
JRE顾名思义是java运行时环境,包含了java虚拟机,java基础类库。是使用java语言编写的程序运行所需要的软件环境,是提供给想运行java程序的用户使用的。
- JDK:Java Development Kit (开发) (工具箱)
JDK顾名思义是java开发工具包,是一种SDK,Software Development Kit,**是提供给程序员使用的。**JDK包含了JRE,同时还包含了编译java源码的编译器javac,还包含了很多java程序调试和分析的工具,提供了Java的开发环境和运行环境。
运行java程序 =>JRE。
编写java程序 =>JDK。
JDK包含了JRE
2、== 和 equals 的区别是什么?
- "=="是判断两个变量或实例是不是指向同一个内存空间。(直接比较地址)
给Integer类型赋值的时候,如果没有调用new关键字,并且值在-128与+127之间,包括-128和+127,那么指向的都是同一个内存位置。
但赋值方式中如果调用了new关键字,一定会在内存中给你分配一个新的地址
-
"=="在JAVA中只是一个运算符合。
-
“equals”,在Object类中定义了一个equals(),该方法初始化是比较对象的内存地址。

重写后是判断两个变量或实例所指向的内存空间的值是不是相同。(先通过地址找到值,再比较值),会被不同类重写。
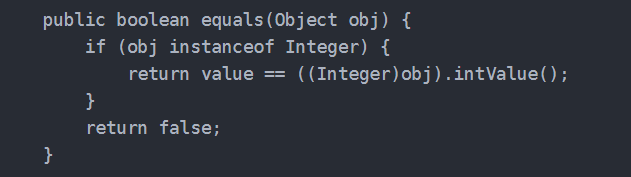
所以equals()方法的默认实现就是返回两个对象==的比较结果.但是equals()可以被重写,所以我们在具体使用的时候需要关注equals()方法有没有被重写。
- “equals"比”=="运行速度要慢。
例题:
public static void main(String[] args) {
//-128 ~ +127 之间
Integer a = 5;
int b = 5;
Integer c = new Integer(5);
Integer d = 5;
System.out.println(a.equals(b));
System.out.println(a == b);
System.out.println(a.equals(c));
System.out.println(a == c);
System.out.println(a == d);
//-128 ~ +127 之外
a = 128;
b = 128;
c = new Integer(128);
d = 128;
System.out.println(a.equals(b));
System.out.println(a == b);
System.out.println(a.equals(c));
System.out.println(a == c);
System.out.println(a == d);
}
运行结果:

3、两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
首先得知道,什么是hash?
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
Hash算法可以将一个数据转换为一个标志,这个标志和源数据的每一个字节都有十分紧密的关系。Hash算法还具有一个特点,就是很难找到逆向规律。
Hash算法是一个广义的算法,也可以认为是一种思想,使用Hash算法可以提高存储空间的利用率,可以提高数据的查询效率,也可以做数字签名来保障数据传递的安全性。所以Hash算法被广泛地应用在互联网应用中。 Hash算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是Hash算法。
多对一关系:不同的输入可能会散列成相同的输出。
hash函数简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
hash函数——直接取余法:
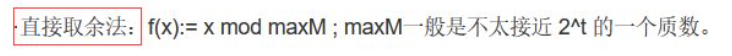
HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的(后半句说的用hashcode来代表对象就是在hash表中的位置)
所以,hashcode就是在hash表中有对应的位置。
用最简单的方法来说,hashcode就是一个签名。当两个对象的hashcode一样时,两个对象就有可能一样。如果不一样的话两个对象就肯定不一样。
一般用hashcode来进行比较两个东西是不是一样的,可以很容易的排除许多不一样的东西。
最常用的地方就是在一堆东西里找一个东西。先用你要找的东西的hashcode和所有东西的hashcode比较,如果不一样的话就肯定不是你要找的东西。如果一样的话就很可能是你要找的东西。然后再进行仔细的比较两个东西是不是真的一模一样。
如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
instanceof 是 Java 的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。
额外知识:
HashSet
参考资料:
4、final 在 java 中有什么作用?
final作为Java中的关键字可以用于三个地方。用于修饰类、类属性和类方法。
特征:凡是引用final关键字的地方皆不可修改!
(1)修饰类:表示该类不能被继承;
(2)修饰方法:表示方法不能被重写;
(3)修饰变量:表示变量只能一次赋值以后值不能被修改(常量)。
5、java 中的 Math.round(-1.5) 等于多少?
四舍五入的原理是在参数上加0.5然后进行下取整。
6、String 属于基础的数据类型吗?
不是
Java的基本数据类型:
Java有八种基本数据类型。(四大整,两小浮。一布尔,一字符)
六种数字类型(四个整数型,两个浮点型), 一种字符类型,还有一种布尔型。
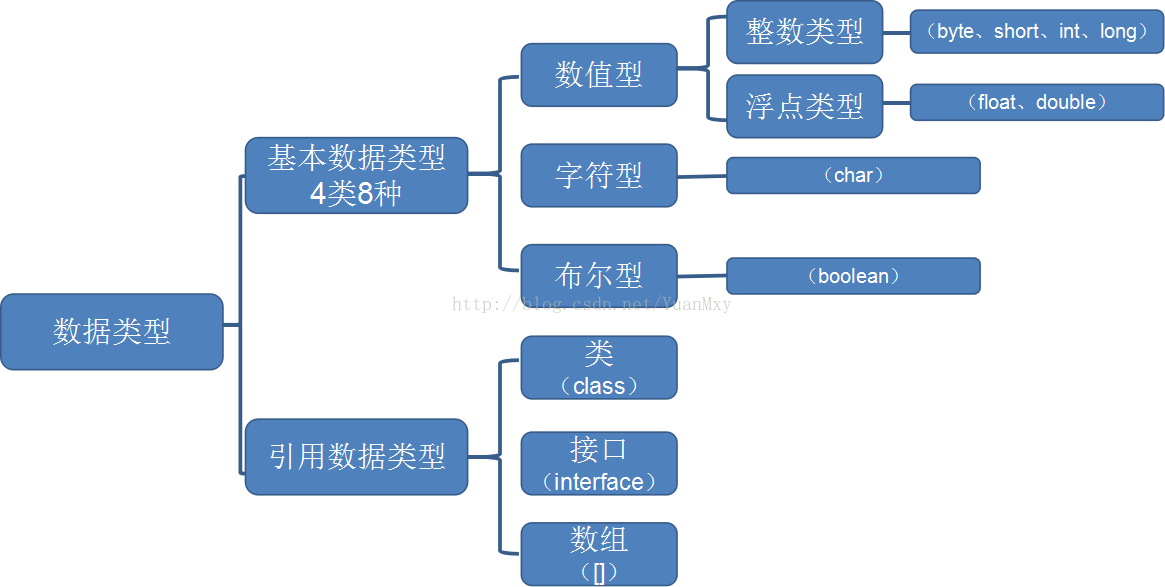
(2)Java数据类型在内存中的存储:
1)基本数据类型的存储原理:所有的简单数据类型不存在“引用”的概念,基本数据类型都是直接存储在内存中的内存栈上的,数据本身的值就是存储在栈空间里面,而Java语言里面八种数据类型是这种存储模型;
2)引用类型的存储原理:引用类型继承于Object类(也是引用类型)都是按照Java里面存储对象的内存模型来进行数据存储的,使用Java内存堆和内存栈来进行这种类型的数据存储,简单地讲,“引用”是存储在有序的内存栈上的,而对象本身的值存储在内存堆上的;
区别:基本数据类型和引用类型的区别主要在于基本数据类型是分配在栈上的,而引用类型是分配在堆上的(需要java中的栈、堆概念),
(3)那Java中字符串string属于什么数据类型?
Java中的字符串String属于引用数据类型。因为String是一个类,
转自[Java基础]Java中字符串string属于什么数据类型
a)基本数据类型
java的基本数据类型共有8种,即int,short,long,byte,float,double,boolean,char(注意,并没有String的基本类型 )。这种类型的定义是通过诸如int a = 3;long b = 255L;的形式来定义的。如int a = 3;这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。比如:
我们同时定义:
int a=3;
int b=3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b这个引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
定义完a与b的值后,再令a = 4;那么,b不会等于4,还是等于3。在编译器内部,遇到时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
java把内存分为两种,一种是堆内存,一种是栈内存。
基本类型类型以及对象的引用变量是存储在栈内存中, 当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
而对象本身的值或者说new创建的对象和数组是存储在堆内存中。 在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量(对象的引用变量),这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
找了一个图,可以更形象的描述它们之间的关系。
原文链接:https://blog.csdn.net/awq520tt1314/article/details/77113618
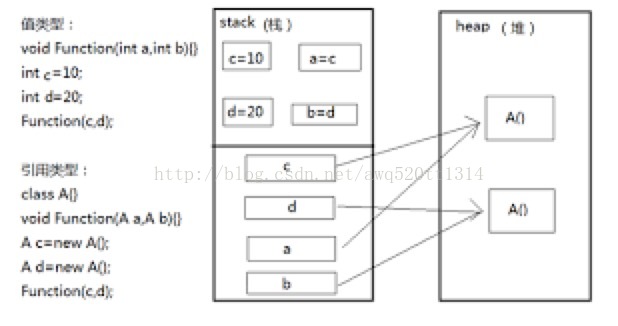
java中内存分配策略
按照编译原理的观点,程序运行时的内存分配有三种策略:静态的,栈式的,堆式的。
-
静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编译时就可以给他们分配特定的存储空间。静态存储分配要求程序中不允许有可变数据结构的存在(比如数组,链表),也不允许有嵌套或者递归的结构出现,因为它们会导致编译程序无法计算准确的存储空间需求。
-
栈式分配(动态存储分配)是由一个类似于堆栈的运行栈来实现的。在栈式存储方案中, 程序对数据区的需求在编译时是完全未知的,只有到运行的时候才能够知道,但是规定在运行中进入一个程序模块时,必须知道该程序模块所需的数据区大小才能够为其分配内存.和我们在数据结构所熟知的栈一样,栈式存储分配按照先进后出的原则进行分配。
-
静态存储分配要求在编译时能知道所有变量的存储要求,栈式存储分配要求在过程的入口处必须知道所有的存储要求,而堆式存储分配则专门负责在编译时或运行时模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例.堆由大片的可利用块或空闲块组成,堆中的内存可以按照任意顺序分配和释放.
栈与堆都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄。
7、java 中操作字符串都有哪些类?它们之间有什么区别?
主要是一下三种:String、StringBuffer、StringBuilder
这个知识点我个人认为还是比较重要的。特别是在项目中。先来看一下这三种操作方式的区别:
-
String是不可变的对象,对每次对String类型的改变时都会生成一个新的对象,
-
StringBuffer和StringBuilder是可以改变对象的。
-
对于操作效率:StringBuilder > StringBuffer > String
-
对于线程安全:StringBuffer 是线程安全,可用于多线程;
-
StringBuilder 是非线程安全,用于单线程
-
不频繁的字符串操作使用 String。反之,StringBuffer 和 StringBuilder 都优于String,所以,如果在项目中需要拼接字符串最好是采用StringBuffer 而非String.
原文链接
8、String str="i"与 String str=new String(“i”)一样吗?
不一样
不一样的原因很简单,因为他们不是同一个对象。
String str=“i”;
这句话的意思是把“i”这个值在内存中的地址赋给str,如果再有String str3=“i”;那么这句话的操作也是把“i”这个值在内存中的地址赋给str3,这两个引用的是同一个地址值,他们两个共享同一个内存。
而String str2 = new String(“i”);
则是将new String(“i”);的对象地址赋给str2,需要注意的是这句话是新创建了一个对象。如果再有String str4= new String(“i”);那么相当于又创建了一个新的对象,然后将对象的地址值赋给str4,虽然str2的值和str4的值是相同的,但是他们依然不是同一个对象了。
需要注意的是:String str=“i”; 因为String 是final类型的,所以“i”应该是在常量池。
而new String(“i”);则是新建对象放到堆内存中。
String,StringBuffer与StringBuilder的区别??
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
-
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
-
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的:
String S1 = “This is only a” + “ simple” + “ test”;
StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候 StringBuffer 居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个
String S1 = “This is only a” + “ simple” + “test”; 其实就是:
String S1 = “This is only a simple test”; 所以当然不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
String S2 = “This is only a”;
String S3 = “ simple”;
String S4 = “ test”;
String S1 = S2 +S3 + S4;
这时候 JVM 会规规矩矩的按照原来的方式去做。
OK结束,下班了
















 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









