






我们就以最经典的HelloWorld程序为例开始吧。我们先使用vim等文本编辑器写好代码,接着在终端执行命令
gcc HelloWorld.c -o HelloWorld
输出了可执行文件HelloWorld,最后我们在终端执行 ./HelloWorld,顺利地显示了输出结果。

可是,简单的命令背后经过了什么样的处理过程呢?gcc真的就“直接”生成了最后的可执行文件了吗?
当然不是,我们在gcc编译命令行加上参数 –verbose要求gcc输出完整的处理过程(命令行加上 -v 也行),我们看到了一段较长的过程输出。
输出结果我们就不完整截图了,大家有兴趣可以自己试验然后试着分析整个流程。
一图胜千言,我们先上一张图吧。这是gcc编译过程的分解图,我在网上找不到满意的,就自己画了一张简单的,大家将就着看吧。
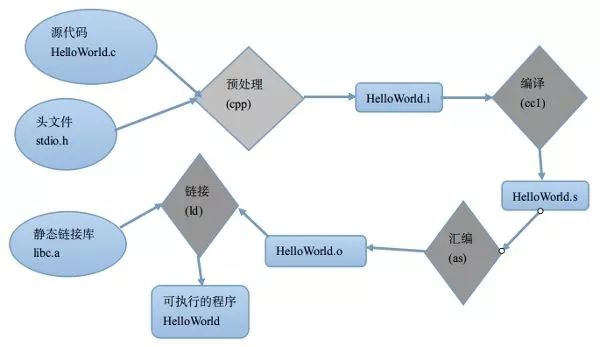
从图中我们大致可以看出gcc处理HelloWorld.c的大致过程:
预处理(Prepressing)—>编译(Compilation)—>汇编(Assembly)—>链接(Linking)
括号中我注明了各个过程中实际执行任务的程序名称:预处理器cpp、编译器cc1、汇编器as以及最后的链接器ld。
预处理
我们一步一步来看,首先是预处理,我们看看预处理阶段对代码进行了哪些处理。
我们在终端输入指令 gcc -E HelloWorld.c -o HelloWorld.i,然后我们打开输出文件。
首先是大段大段的变量和函数的声明,汗..我们的代码哪里去了?我们在vim的普通模式中按下shift+g(大写G)来到最后,终于在几千行以后看到了我们可怜兮兮的几行代码。
前面几千行是什么呢?
其实它就是 /usr/include/stdio.h 文件的所有内容,预处理器把所有的#include替换为实际文件的内容了。这个过程是递归进行的,所以stdio.h里面的#include也被实际内容所替换了。
而且我在HelloWorld.c里面的所有注释被预处理器全部删除了。就连printf语句前的Tab缩进也被替换为一个空格了,显得代码都不美观了。
时间关系,我们就不一一试验处理的内容了,我直接给出预处理器处理的大致范围吧。
展开所有的宏定义并删除 #define
处理所有的条件编译指令,例如 #if #else #endif #ifndef …
把所有的 #include 替换为头文件实际内容,递归进行
把所有的注释 // 和 / / 替换为空格
添加行号和文件名标识以供编译器使用
保留所有的 #pragma 指令,因为编译器要使用
……
基本上就是这些了。在这里我顺便插播一个小技巧,在代码中有时候宏定义比较复杂的时候我们很难判断其处理后的结构是否正确。这个时候我们呢就可以使用gcc的-E参数输出处理结果来判断了。
前文中我们提到了头文件中放置的是变量定义和函数声明等等内容,这些到底是什么东西呢?其实在比较早的时候调用函数并不需要声明,后来因为“笔误”之类的错误实在太多,造成了链接期间的错误过多,所有编译器开始要求对所有使用的变量或者函数给出声明,以支持编译器进行参数检查和类型匹配。
头文件包含的基本上就是这些东西和一些预先的宏定义来方便程序员编程。
其实对于我们的HelloWorld.c程序来说不需要这个庞大的头文件,只需要在main函数前声明printf函数,不需要#include即可通过编译。
声明如下:
1int printf(const char *format, ...);
这个大家就自行测试吧。另外再补充一点,gcc其实并不要求函数一定要在被调用之前定义或者声明(MSVC不允许),因为gcc在处理到某个未知类型的函数时,会为其创建一个隐式声明,并假设该函数返回值类型为int。
但gcc此时无法检查传递给该函数的实参类型和个数是否正确,不利于编译器为我们排除错误(而且如果该函数的返回值不是int的话也会出错),所以还是建议大家在函数调用前,先对其定义或声明。
编译
预处理部分说完了,我们接着看编译。
那么什么是编译?一句话描述:编译就是把预处理之后的文件进行一系列词法分析、语法分析、语义分析以及优化后生成的相应汇编代码文件。
这一部分我们不能展开说了,一来我没有系统学习过编译原理的内容不敢信口开河,二来这部分要是展开去说需要很厚很厚的一本书了,细节大家就自己学习《编译原理》吧,相关的资料自然就是经典的龙书、虎书和鲸书了。
gcc怎么查看编译后的汇编代码呢?
命令是 gcc -S HelloWorld.c -o HelloWorld.s,这样输出了汇编代码文件HelloWorld.s,其实输出的文件名可以随意,我是习惯使然。
顺便说一句,这里生成的汇编是AT&T风格的汇编代码,如果大家更熟悉Intel风格,可以在命令行加上参数 -masm=intel ,这样gcc就会生成Intel风格的汇编代码了(如图,这个好多人不知道哦)。不过gcc的内联汇编只支持AT&T风格,大家还是找找资料学学AT&T风格吧。
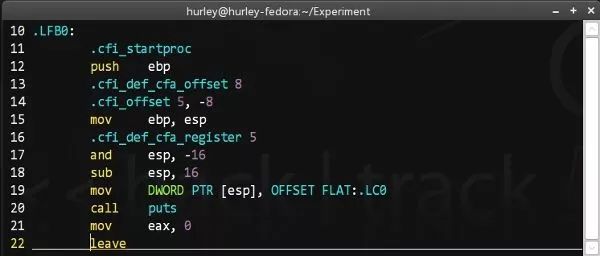
汇编
再下来是汇编步骤,我们继续用一句话来描述:汇编就是将编译后的汇编代码翻译为机器码,几乎每一条汇编指令对应一句机器码。
这里其实也没有什么好说的了,命令行 gcc -c HelloWorld.c 可以让编译器只进行到生成目标文件这一步,这样我们就能在目录下看到HelloWorld.o文件了。
Linux下的可执行文件以及目标文件的格式叫作ELF(Executable Linkable Format)。
其实Windows下的PE(Portable Executable)也好,ELF也罢,都是COFF(Common file format)格式的一种变种,甚至Windows下的目标文件就是以COFF格式去存储的。
不同的操作系统之间的可执行文件的格式通常是不一样的,所以造成了编译好的HelloWorld没有办法直接复制执行,而需要在相关平台上重新编译。当然了,不能运行的原因自然不是这一点点,不同的操作系统接口(windows API和Linux的System Call)以及相关的类库不同也是原因之一。














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









