






Tornado梗概
Tornado是一个用Python编写的可扩展的、无阻塞的Web应用程序框架和Web服务器。它是由FriendFeed开发使用的;该公司于2009年被Facebook收购,而Tornado很快就开源了
龙卷风以其高性能着称。它的设计允许处理大量并发连接,Tornado在设计之初就考虑到了性能因素,旨在解决C10K(同时处理一万个连接的缩写)问题,这样的设计使得其成为一个拥有非常高性能的框架。此外,它还拥有处理安全性、用户验证、社交网络以及与外部服务(如数据库和网站API)进行异步交互的工具
延伸阅读:C10K问题
基于线程的服务器,如Apache,为了传入的连接,维护了一个操作系统的线程池。Apache会为每个HTTP连接分配线程池中的一个线程,如果所有的线程都处于被占用的状态并且尚有内存可用时,则生成一个新的线程。尽管不同的操作系统会有不同的设置,大多数Linux发布版中都是默认线程堆大小为8MB。Apache的架构在大负载下变得不可预测,为每个打开的连接维护一个大的线程池等待数据极易迅速耗光服务器的内存资源。
为什么会有这么大的负载呢?服务器同时要对许多客户端提供服务,而服务器端的处理流程,只要遇到了I/O操作,往往需要长时间的等待。
整个流程52ms,中间50ms是在等待耗时操作结束,这段时间服务进程的CPU是空闲的,浪费掉了。
换个角度看,是CPU在各个流程间跳来跳去,专门处理那些红色的片段。这种模式下,服务进程有效利用了等待时间,实际花费的只是一头一尾两段真正占用CPU的时间。这样服务进程每秒可以处理的请求可成几十倍的增长。
而这样的模式,就是在一个进程之间同时处理多个协程,充分利用CPU时间,这就是我们需要的异步编程。而
Tornado就是可以支持异步非堵塞IO模式


Tornado的优势
Tornado是一整套的异步编码方案: 不仅仅一个套完整web框架,还包含了一整套http协议以及、websocket协议的库、还有异步库
Tornado 不只是Web框架 ,也是Web服务器
我们不光可以通过Tornado开发web应用,还可以通过Tornado部署其它的web应用(充当的就是Nginx)
虽然核心来说可以当服务器使用,一般不会用tornado替代掉nginx,毕竟nginx有的功能tornado是没有的,比如说发送邮件,流量限速,负载均衡等等
那为什么torndao要是一个web服务器呢?因为nginx服务器从一开始的就是用来提供给同步的web应用框架使用的,而tornado是一个套异步的web框架,可以说算是一套新的框架。所以说如使用nginx这样的服务器,也不能很好结合的。所以说,tornado不得不重新实现一个基于epoll协议的web服务器
Tornado是基于协程的解决方案
Tornado能高并发主要的原因就是因为协程。我们之前了解过进程、线程、协程。而操作系统可以调度的最小单元就是线程。所以说,若想调度协程需要我们自己程序来调度,没有办法通过操作系统来调度。早起版本的Python开发协程比较复杂,现在Python开发比较容易了(3.6+以后)。Tornado底层协程使用asyncio。所以我们后面也是通过asyncio实现的任务调度
Tornado提供websocket的长连接(Web聊天、消息推送)比如说:常规网络服务是这样的,我们在聊天时,想看别人有没有发消息过来,我们要刷新页面才知道。后来随之时代的进度,收别人的消息就不在用刷新页面。
再比如:打个某些,尤其是金融或者新闻网站 。当打网站时,一有新消息就会有信息推送出来
这些都是websocket支持的
Tornado注意事项
Tornado提供的不只是web框架
异步编码的一整套方案,包含了框架与,也提供了事件循环的功能,也就是服务器功能,在部署时也可以直接部署。
使用了Tornado不一定就是高并发
如果在代码中使用了同步的IO后,效果也是比较低,甚至会比Flask与Django还要低。
所以在使用Tornado时,我们需要了解什么是事件循环,什么是协程。
事件循环的模式是单线程完成的,那就意外着,有一个地方使用了同步IO操作,那整个所有消息都会被堵塞住。
Tornado中尽量不要使用的同步IO
根据之前说的,我们再使用Tornado时,尽量不要使用同步IO,这也就是有的小伙伴在测试Tornado时发现效率没有Flask、Django高的主要原因。甚至有的小伙伴都不清楚什么样的操作是异步的,什么样的操作是同步的。所以以后我们在使用时,要多加注意
Tronado只需要把耗时的操作放到线程池中就可以达到高并发??
这个也是不对的。在实际写代码时,遇到耗时比较多,也或者使用别人的库耗时比较多。他们放到线程池中能否提高效率取决于是否是异步的。如果不是异步只能考虑换库,或者自己写一个。
Tornado入门
Python安装Tornado:
pip install tornado简单程序展示:
from tornado import web from tornado import ioloop # 这是Tornado的请求处理函数类。当处理一个请求时,Tornado将这个类实例化,并调用与HTTP请求方法所对应的方法 class IndexHandler(web.RequestHandler): def get(self): # Tornado的RequestHandler类有一系列有用的内建方法,write,它以一个字符串作为函数的参数,并将其写入到HTTP响应中 self.write('Hello Tornado!!') if __name__ == '__main__': # 创建一个Tornado的Application类的实例,传递给Application类init方法的最重要的参数是handlers。它告诉Tornado应该用哪个类来响应请求 app = web.Application([('/',IndexHandler)],debug = True) app.listen(8000) ioloop.IOLoop.current().start()编写一个Tornado应用中最多的工作是定义类继承Tornado的RequestHandler类。在这个例子中,我们创建了一个简单的应用,在给定的端口监听请求,并在根目录("/")响应请求。
你可以在命令行里尝试运行这个程序以测试输出:
$ python hello.pyTornado的options选项
options 可以让服务运行前提前设置参数,而常见的2种设置参数方式为:
- 命令行设置
- 文件设置
命令行解析:
使用
tornado.options.define前定义,通常在模块的顶层。然后,可以将这些选项作为以下属性的属性进行访问
tornado.options.options但要解析命令行参数时,需要使用
tornado.options.parse_command_line方法来解析参数即:
# main.py import time from tornado import web import tornado from tornado.options import define, options, parse_command_line #define, 定义一些可以在命令行中传递的参数以及类型 define('port', default=8008, help="port to listen on", type=int) define('debug', default=True, help="set tornado debug mode", type=bool) #parse_command_line() #options是一个类,全局只有一个options class IndexHandler(web.RequestHandler): async def get(self): self.write("hello Tornado") class IndexHandler2(web.RequestHandler): async def get(self): self.write("hello Tornado22") if __name__ == "__main__": app = web.Application([ ("/", IndexHandler), ("/index/", IndexHandler2) ], debug=options.debug) app.listen(options.port) tornado.ioloop.IOLoop.current().start()文件设置:创建文件,将必要的参数直接写入即可
# server.conf port=8000设置好文件后,通过
tornado.options.parse_config_file来解析
提示:有了以上方法,就可更新的设置服务器的各种通用参数了,如数据库参数、文件目录参数、服务器参数等
URL设置
Tornado在元组中可以传递指定的规则,并会根据规则来匹配HTTP请求的路径(这个路径是URL中主机名后面的部分)。匹配完成后,会实例化相应的类。
url地址可以如下操作:
- 完整匹配,跳转控制器
- 通过re匹配,跳转控制器
- 通url传递参数
- 跳转 url 反转 使用web.URLSpec中的
name属性,在处理函数中使用reverse_url
例子:from tornado.web import RequestHandler,Application,URLSpec from tornado.ioloop import IOLoop # 用来处理请求,并响应结果 class IndexHandler(RequestHandler): def get(self): self.write('Hello Tornado!!') class Index2Handler(RequestHandler): def get(self): self.write('Hello Tornado!!22') class Index3Handler(RequestHandler): def get(self): self.write('Hello Tornado!!33') class UserHandler(RequestHandler): def get(self,id): self.write(f'您好,您的用户ID是:{id}') class UserNameHandler(RequestHandler): def get(self,name): self.write(f'您好,您的用户名是:{name}') class BookNameHandler(RequestHandler): def get(self,book_type,book_name): self.write(f'您好,您获取的资源类型是:{book_type} 分类是:{book_name}') class Rediect1Handler(RequestHandler): def get(self): # self.redirect('/') # 跳转到另一个URL地址 # self.reverse_url('index') 通过控制器的名字进行反向查找URL的地址 self.redirect(self.reverse_url('index')) class Rediect2Handler(RequestHandler): def initialize(self,name,pwd): self.name = name self.pwd = pwd print(f'{self.name}======={self.pwd}') def get(self): self.redirect(self.reverse_url('index')) if __name__ =='__main__': # 定义要传递的参数 args ={'name':'sxt','pwd':123} # 创建一个tornado应用 app = Application([ # ('/',IndexHandler), # 精准匹配 URLSpec('/',IndexHandler,name='index'), ('/index2/',Index2Handler), ('/index3/?',Index3Handler), # 控制模糊匹配 ('/user/(\d+)/',UserHandler), # 使用re匹配 ('/user/(\w+)/',UserNameHandler), # URL匹配是根据从上到下依次匹配的,匹配到后会直接处理并响应 # ('/book/(\w+)/(\w+)/',BookNameHandler), # 传递多个数据 ('/book/(?P<book_type>\w+)/(?P<book_name>\w+)/',BookNameHandler), # 传递多个数据,通过 “(?<var_name正则的规则>)” ('/test/?',Rediect1Handler), # 跳转 URLSpec('/test2/?',Rediect2Handler,args) # 方式时,可以传递参数 ],debug = True) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 IOLoop.current().start()请求控制类-RequestHandler
tornado.web.RequestHandler是HTTP请求处理程序的基类,每个RequestHandler类可以定义多个HTTP方法的行为,一般会把概念相关的功能绑定到同一个类是一个很好的方法。功能方法:
initialize:钩子类初始化,每个请求都会调用prepare:在get,post,put之前的请求开始时调用,执行通用初始化
on_finish:请求结束后调用,此方法以执行清理,日志记录等
set_status:显示地设置HTTP状态码,Tornado会自动地设置HTTP状态码
状态码:
404 Not Found
Tornado会在HTTP请求的路径无法匹配任何RequestHandler类相对应的模式时返回404(Not Found)响应码。
400 Bad Request
如果你调用了一个没有默认值的get_argument函数,并且没有发现给定名称的参数,Tornado将自动返回一个400(Bad Request)响应码。
405 Method Not Allowed
如果传入的请求使用了RequestHandler中没有定义的HTTP方法(比如,一个POST请求,但是处理函数中只有定义了get方法),Tornado将返回一个405(Methos Not Allowed)响应码。
500 Internal Server Error
当程序遇到任何不能让其退出的错误时,Tornado将返回500(Internal Server Error)响应码。你代码中任何没有捕获的异常也会导致500响应码。
200 OK
如果响应成功,并且没有其他返回码被设置,Tornado将默认返回一个200(OK)响应码。
finish:结束响应,在函数中可以返回内容
请求方法:get/head/post/delete/patch/put/Options
案例:
from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def initialize(self,db = None) -> None: # 初始化函数,一般用来初始化环境变量 self.db = db def prepare(self): print(111111111111111) # 记录日志,打开文件 def on_finish(self) -> None: print(333333333333333) # 清理内容 def get(self): print(22222222222) self.write('Hello Tornado!!') # self.set_status(500) # 直接返回响应的状态码 self.finish({'msg':'get success!!'}) def post(self): print('info from post') self.write('POST请求接收成功!!') # put delete patch if __name__ =='__main__': # 创建一个tornado应用 app = web.Application([('/',IndexHandler)],debug = True) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start()获取参数
get_argument返回具有给定名称的参数的值
get_arguments返回具有给定名称的参数列表
get_query_argument从请求查询字符串中返回具有给定名称的参数的值
get_query_arguments返回具有给定名称的查询参数的列表
get_body_argument从请求主体返回具有给定名称的参数的值
get_body_arguments返回具有给定名称的主体参数列表。
request属性 包含附加请求参数的对象,例如头文件和主体数据
提示:
url字符串参数可以使用
Content-Type为application/x-www-form-urlencoded或者multipart/form-data 的可以使用
如果是json无法获取数据
案例:
from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def get(self): self.write('Hello Tornado!!') # 如果获取查询参数,可以使用 get_argument get_query_argument get_arguments get_query_arguments # name = self.get_argument('uname') # pwd = self.get_argument('pwd') # # name = self.get_arguments('uname') # # pwd = self.get_arguments('pwd') # hobby = self.get_arguments('q') name = self.get_query_argument('uname') pwd = self.get_query_argument('pwd') hobby = self.get_query_arguments('q') # 不推荐使用 # name = self.get_body_argument('uname') # pwd = self.get_body_argument('pwd') # hobby = self.get_body_arguments('q') print(f'{name=} {pwd=} {hobby=}') def post(self): self.write('Hello Tornado!! POST') # 如果获取请求体参数,可以使用 get_argument get_body_argument get_arguments get_body_arguments # name = self.get_body_argument('uname') # pwd = self.get_body_argument('pwd') # hobby = self.get_body_arguments('q') # print(f'{name=} {pwd=} {hobby=}') # name = self.get_argument('uname') # pwd = self.get_argument('pwd') # hobby = self.get_arguments('q') # print(f'{name=} {pwd=} {hobby=}') # 获取不到数据 # name = self.get_query_argument('uname') # pwd = self.get_query_argument('pwd') # hobby = self.get_query_arguments('q') # print(f'{name=} {pwd=} {hobby=}') # 获取 raw 的数据 ,可能通过request.body对象 # 但是是bytes,需要数据转换 decoode()转成字符串, # 如果str是一个dict类型,可以通过json.loads进行数据转换 args = self.request.body.decode('utf-8') from json import loads args = loads(args) print(args.get('uname')) if __name__ =='__main__': # 创建一个tornado应用 app = web.Application([('/',IndexHandler)],debug = True) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start()重定向 RedirectHandler
在网络应用中,一般在访问个人主页时,系统会先判断用户是否登录。如果没有登录,会提示没有登录。也有的系统发现没有登录,系统会自动跳转到登录的页面。问题是这个内部跳转的功能叫什么?Tornado中又如何实现呢?
向这种跳转可以称之为重定向,一般重定向的http状态码有2种:
301是永久的重定向,在使用域名跳转的情况下
- 比如: 搜索引擎在搜索到新内容后,做跳转
302是暂时的重定向,在域名 内跳转的情况下
- 比如: 在登陆用户访问用户中心的时候重定向到登录页面
在开发时,重定向一般有2种情况
直接重定向
RequestHandler.redirect('/')处理业务后,再重定向
RedirectHandler
案例:
from tornado import web, ioloop from tornado.web import RedirectHandler # 301是永久重定向, 302是临时重定向 class IndexHandler(web.RequestHandler): def get(self): self.finish('Hello Tornado!') class LoginHandler(web.RequestHandler): def get(self): self.redirect('/') # print(self.reverse_url('index')) if __name__ == "__main__": app = web.Application([ web.URLSpec('/',IndexHandler,name='index'), web.URLSpec('/login/',LoginHandler), web.URLSpec('/index/',RedirectHandler,{'url':'/'}) ],debug=True) app.listen(8000) ioloop.IOLoop.current().start()设置静态资源 StaticFileHandler
在网络应用中,为了提高用户体验,往往给会用户展示些多媒体的文件,比如:图片、音乐、视频等。
在Tornado中若想设置静态文件访问资料,可以通过以下方式:
通过在
Application对象中通过static_path参数来设置静态的目录,
- 附加功能:通过
static_url_prefix参数来设置访问资源的前缀通过
StaticFileHandler控制类来设置路径方法1:
from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def get(self): self.write('Hello Tornado!!') if __name__ =='__main__': static_args = { 'static_path':'./static/', 'static_url_prefix':'/img/' } # 创建一个tornado应用 app = web.Application( [web.URLSpec('/',IndexHandler,name='index'),], debug = True, # static_path='./static/', # 默认访问静态资源的前缀是static # static_url_prefix = '/img/' # 可选项:设置静态资源的前缀 **static_args ) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start()方法2:
from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def get(self): self.write('Hello Tornado!!') if __name__ =='__main__': import os static_path = os.path.join(os.path.dirname(__file__),'static') # 创建一个tornado应用 app = web.Application( [ web.URLSpec('/',IndexHandler,name='index'), # http://127.0.0.1:8000/static/img/aa.jpg ('/static/(.*)',web.StaticFileHandler,{'path':static_path}), # 通过控台类来设置静态文件 ], debug = True,) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start() # print(static_path)设置模板Template
建立一个漂亮的页面需要html,css,js,我们可用通过把这一堆字段全部写到视图中, 作为
HttpResponse()的参数,响应给客户端通过字符串返回:
import tornado class IndexHandler(web.RequestHandler): def get(self): arg = 'Template' self.finish(f'<h1>Hello {arg}!!</h1>')通过模板Template返回(tornado.template)
例子:
class IndexHandler1(web.RequestHandler): def get(self): arg = 'Template1' t = template.Template(f'<h1>Hello {arg}!!</h1>') self.finish(t.generate()) class IndexHandler2(web.RequestHandler): def get(self): arg1 = 'Template2' t = template.Template('<h1>Hello {{arg}}!!</h1>') self.finish(t.generate(arg = arg1)) class IndexHandler3(web.RequestHandler): def get(self): arg1 = 'Template3_file' loader = template.Loader('./templates/') self.finish(loader.load('index.html').generate(arg = arg1))<!-- templates/index.html --> <h1>Hello {{arg}}!!</h1>通过模板render返回:
class IndexHandler4(web.RequestHandler): def get(self): arg1 = 'render_Template3_file' self.render('index.html',arg=arg1)模板的语法使用
一:填充表达式
填充Python变量的值或表达式到模板的双大括号中的使用。Tornado将插入一个包含任何表达式计算结果值的字符串到输出模板是
{{ args }} {{ 'dasdasd'[-4:] }} {{ sum(1,5)}}二:控制流语句
可以在Tornado模板中使用Python条件和循环语句。控制语句以{%和%}包围,并以类似下面的形式被使用
控制语句的大部分就像对应的Python语句一样工作,支持if、for、while和try。在这些情况下,语句块以{%开始,并以%}结束
{% if page is None %} {% if len(entries) == 3 %} {% endif %}三:提供静态文件
·设置静态路径:通过向Application类的构造函数传递一个名为static_path的参数来告诉Tornado从文件系统的一个特定位置提供静态文件
在这里,我们设置了一个当前应用目录下名为static的子目录作为static_path的参数。现在应用将以读取static目录下的filename.txt来响应诸如/static/filename.txt的请求,并在响应的主体中返回
app = tornado.web.Application( handlers=[(r'/', IndexHandler), (r'/poem', MungedPageHandler)], template_path=os.path.join(os.path.dirname(__file__), "templates"), static_path=os.path.join(os.path.dirname(__file__), "static"), debug=True )·使用static_url生成静态URL:Tornado模板模块提供了一个叫作static_url的函数来生成static目录下文件的URL。让我们来看看在index.html中static_url的调用的示例代码:
<link rel="stylesheet" href="{{ static_url("style.css") }}">这个对static_url的调用生成了URL的值,并渲染输出类似下面的代码:
<link rel="stylesheet" href="/static/style.css?v=ab12">那么为什么使用static_url而不是在模板中硬编码呢?有如下几个原因。其一,static_url函数创建了一个基于文件内容的hash值,并将其添加到URL末尾(查询字符串的参数v)。这个hash值确保浏览器总是加载一个文件的最新版而不是之前的缓存版本。无论是在你应用的开发阶段,还是在部署到生产环境使用时,都非常有用,因为你的用户不必再为了看到你的静态内容而清除浏览器缓存了。
另一个好处是你可以改变你应用URL的结构,而不需要改变模板中的代码。例如,你可以配置Tornado响应来自像路径/s/filename.txt的请求时提供静态内容,而不是默认的/static路径。如果你使用static_url而不是硬编码的话,你的代码不需要改变。比如说,你想把静态资源从我们刚才使用的/static目录移到新的/s目录。你可以简单地改变静态路径由static变为s,然后每个使用static_url包裹的引用都会被自动更新。如果你在每个引用静态资源的文件中硬编码静态路径部分,你将不得不手动修改每个模板。
模板案例:
通过模板返回一下内容:
<section class="wrap" style="margin-top:20px;overflow:hidden;"> <table class="order_table"> <tr> <th><input type="checkbox" /></th> <th>产品</th> <th>名称</th> <th>属性</th> <th>单价</th> <th>数量</th> <th>小计</th> <th>操作</th> </tr> {% set total = 0 %} {% for order in orders %} <tr> <td class="center"><input type="checkbox" /></td> <td class="center"><a href="product.html"><img src="{{order.get('img')}}" style="width:50px;height:50px;" /></a> </td> <td><a href="product.html">{{ order.get('name') }}</a></td> <td> <p>{{ order.get('type')}}</p> </td> <td class="center"><span class="rmb_icon">{{ order.get('price')}}</span></td> <td class="center"> <span>{{ order.get('num') }}</span> </td> <!-- <td class="center"><strong class="rmb_icon">{{order.get('price')*order.get('num')}}</strong></td> --> <td class="center"><strong class="rmb_icon">{{count_price(order.get('price'),order.get('num'))}}</strong></td> <td class="center">{% raw order.get('opts') %}</td> <!-- 后端传递了标签,可以通过 raw 方式解析--> <div hidden> {{ total = total + count_price(order.get('price'),order.get('num')) }} </div> </tr> {% end %} </table> <div class="order_btm_btn"> <a href="index.html" class="link_btn_01 buy_btn" />继续购买</a> <a href="order_confirm.html" class="link_btn_02 add_btn" />共计金额<strong class="rmb_icon">{{total}}</strong>立即结算</a> </div> </section>from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def count_price(self,price:int,num:int) -> int: return price*num def get(self): orders = [ { 'id':1, 'name':'MacPro 2060', 'type':'32G', 'price':10000, 'num':1, 'img':'/static/img/goods.jpg', 'opts':'<a href="delelte?id=1">删除</a>' }, { 'id':2, 'name':'HuaWei Mate 2060', 'type':'32G', 'price':8000, 'num':2, 'img':'/static/img/goods007.jpg', 'opts':'<a href="delelte?id=2">删除</a>' }, { 'id':3, 'name':'Sony耳机', 'type':'立体混音', 'price':2000, 'num':1, 'img':'/static/img/goods008.jpg', 'opts':'<a href="delelte?id=3">删除</a>' }, ] self.render('shop13.html',orders = orders, count_price = self.count_price) if __name__ =='__main__': import os base_path = os.path.dirname(__file__) settings = { 'template_path':os.path.join(base_path,'templates'), 'static_path':os.path.join(base_path,'static'), 'static_url_prefix':'/static/' } # 创建一个tornado应用 app = web.Application([ ('/',IndexHandler), ],debug = True,**settings) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start()模板继承
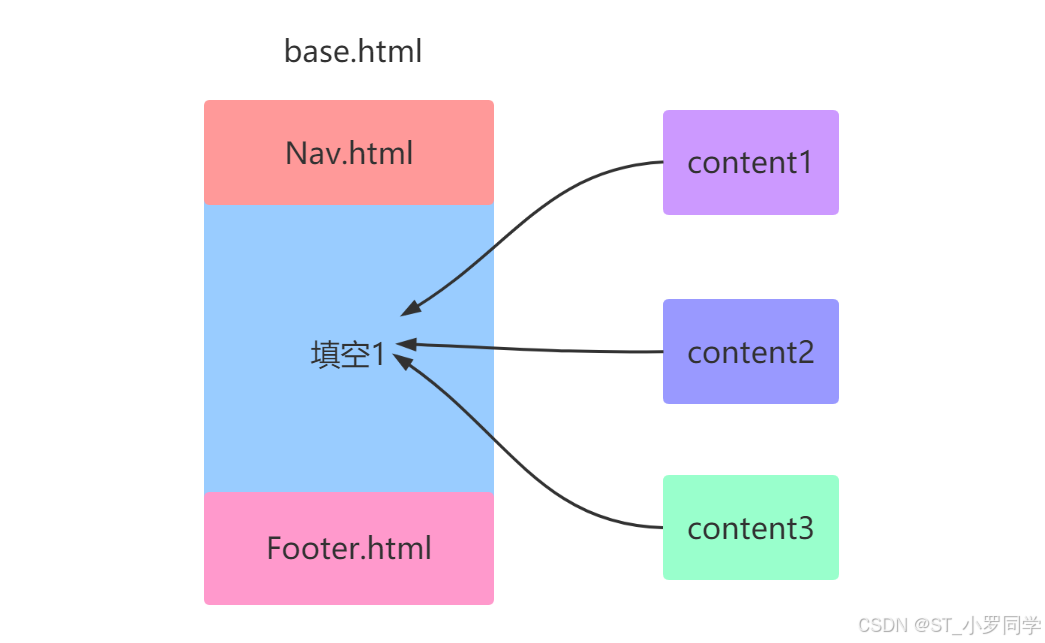
在很多情况下,前端模板中在很多页面有都重复的内容可以使用,比如页头、页尾、甚至中间的内容都有可能重复。 这时,为了提高开发效率,我们就可以考虑在共同的部分提取出来,模板继承就是主要方法之一
# common/base.html {% block content %} {% end %}# shop2.html {% extends 'common/base.html'%} {% block content %} {% end %}UI模型
Tornado中支持类似Vue中的组件功能,就是也公共的内容提取出来当成组件。
具体的使用方式:
继承
tornado.web.UIModule建立UI模型类
- 实现 render方法,返回UI模型
在
tornado.web.Application对象中使用ui_modules参数设置UI模型映射
- 值的格式为:
{"UI模型名":"UI模型类"}在使用UI模型时,通过
{% module UI名(<参数>) %}from tornado import web from tornado import ioloop # 用来处理请求,并响应结果 class IndexHandler(web.RequestHandler): def count_price(self, price: int, num: int) -> int: return price * num def get(self): orders = [ { "id": 1, "name": "MacPro 2060", "type": "32G", "price": 10000, "num": 1, "img": "/static/img/goods.jpg", "opts": '<a href="delelte?id=1">删除</a>', }, { "id": 2, "name": "HuaWei Mate 2060", "type": "32G", "price": 8000, "num": 2, "img": "/static/img/goods007.jpg", "opts": '<a href="delelte?id=2">删除</a>', }, { "id": 3, "name": "Sony耳机", "type": "立体混音", "price": 2000, "num": 1, "img": "/static/img/goods008.jpg", "opts": '<a href="delelte?id=3">删除</a>', }, ] self.render("shop15.html",orders=orders) # 创建一个UImodule class ProductModule(web.UIModule): def count_price(self, price: int, num: int) -> int: return price * num def render(self,orders:list=[]) -> str: return self.render_string('ui_module/product15.html', orders=orders, count_price=self.count_price) if __name__ == "__main__": import os base_path = os.path.dirname(__file__) settings = { "template_path": os.path.join(base_path, "templates"), "static_path": os.path.join(base_path, "static"), "static_url_prefix": "/static/", # 告诉tornado,有哪些UImodule可以使用 "ui_modules":{ "product":ProductModule } } # 创建一个tornado应用 app = web.Application( [ ("/", IndexHandler), ], debug=True, **settings ) # 设置监听端口 app.listen(8000) # 通过事件循环来监听访问的端口 ioloop.IOLoop.current().start()UI模型-样式
为了让UI模型给用户更好的用户体验。一般会给UI模型增加样式以及动态JS效果。
如果需要给UI模型中增加样式和JS代码,可以通过
tornado.web.UIModule类中的方法实现:
embedded_javascript
- 嵌入到模型中JS代码
javascript_files
- 返回一个JS列表,内容为文件地址即可
embedded_css
- 嵌入到模型中css代码
css_files
- 返回一个CSS列表,内容为文件地址即可
注意:嵌入代码是将内容写入到head标签中,因此推荐在UI模型中增加上head标签
class ProductModule(web.UIModule): def count(self,price,num): return price*num def render(self,orders): # print(orders) return self.render_string('ui_module/product.html',orders=orders,count_price = self.count) # def embedded_css(self): # return 'html {color:red}' def css_files(self): return ['css/style.css']个人信息案例
前端:
copy 原生素材
html--->templates
css--->static/css
js--->static/js
img--->static/img到项目中后端:
from tornado import web, ioloop from tornado.web import StaticFileHandler class IndexHandler(web.RequestHandler): def get(self): self.render('personal.html') import os base_url = os.path.dirname(os.path.abspath(__file__)) settings={ 'static_path':os.path.join(base_url,'static'), 'static_url_prefix':'/static/', 'template_path':os.path.join(base_url,'templates') } if __name__ == "__main__": app = web.Application([ web.URLSpec('/',IndexHandler,name='index'), ], debug=True, **settings ) app.listen(8000) ioloop.IOLoop.current().start()同时配置MySql数据库
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uname` varchar(32) DEFAULT NULL, `nick_name` varchar(32) DEFAULT NULL, `email` varchar(32) DEFAULT NULL, `pwd` varchar(32) DEFAULT NULL, `phone` varchar(32) DEFAULT NULL, `language` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8异步操作MySQL
我们需要使用一个异步的框架,在这,我们推荐使用
aiomysql,它的底层大量的使用了pymysql,只是它通过asyncio实现的访问数据库Python安装:
pip install aiomysqlimport asyncio import aiomysql async def test_example(loop): pool = await aiomysql.create_pool(host='127.0.0.1', port=3306, user='root', password='', db='mysql', loop=loop) async with pool.acquire() as conn: async with conn.cursor() as cur: await cur.execute("SELECT 42;") print(cur.description) (r,) = await cur.fetchone() assert r == 42 pool.close() await pool.wait_closed() loop = asyncio.get_event_loop() loop.run_until_complete(test_example(loop))
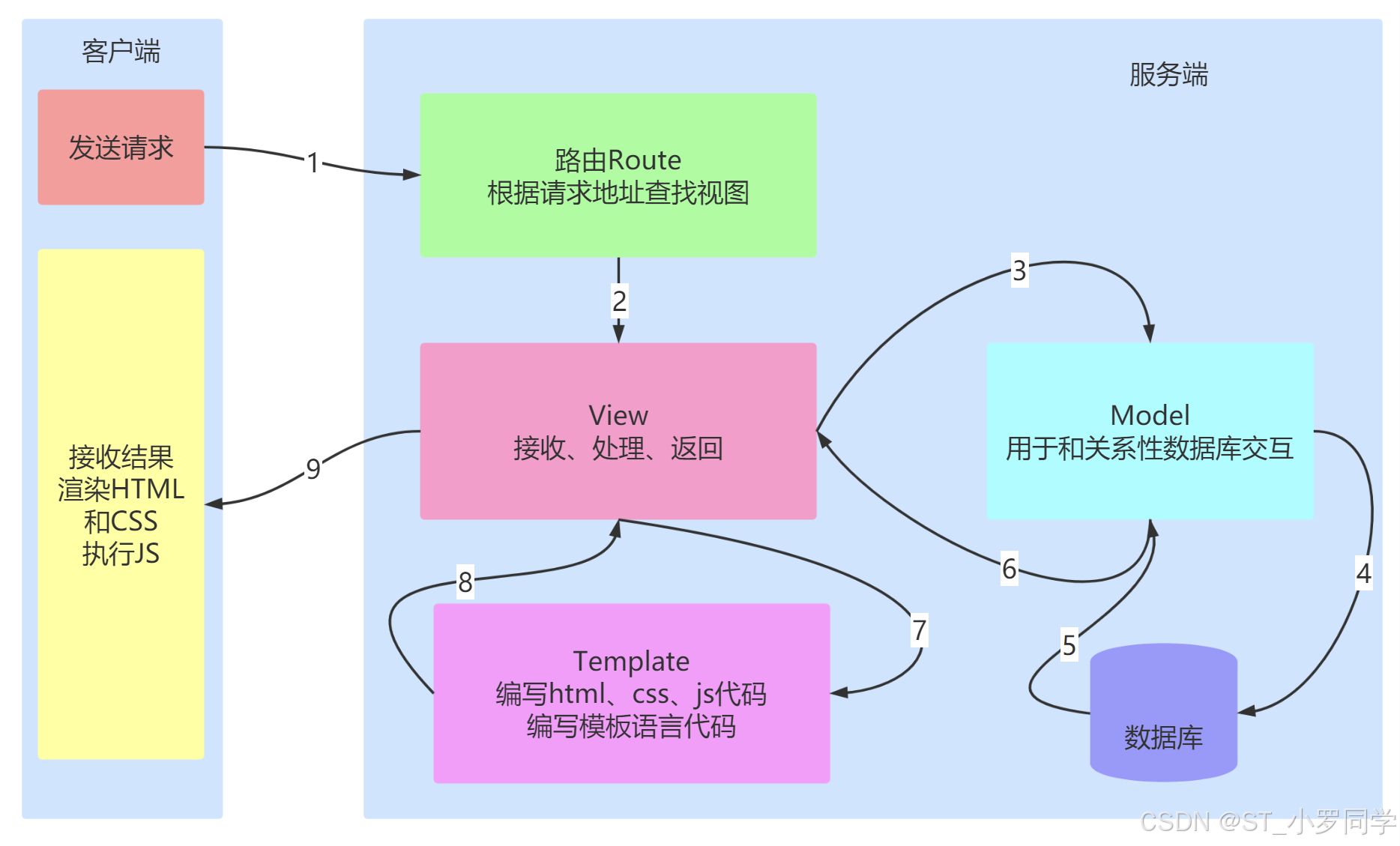
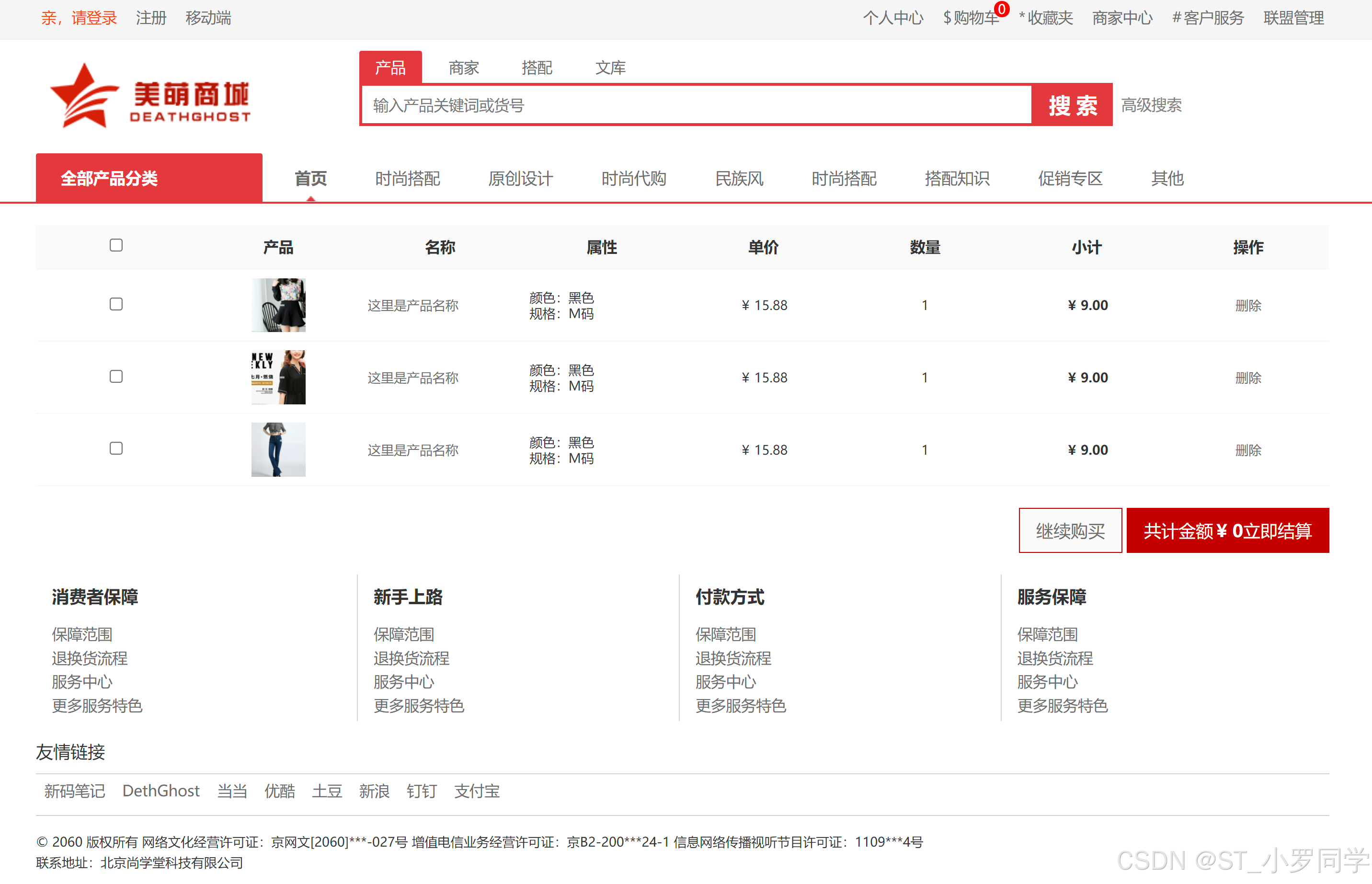
peewee的介绍与安装
官网链接:peewee
Python安装:(tip 需要安装pymysql,不然会报错)
pip install peeweePeewee是一个简单而小型的ORM。使其易于学习且使用直观。
一个小的,表达力很强的ORM
python 2.7+和3.4+(使用3.6开发)
支持sqlite,mysql,postgresql和cockroachdb
大量的扩展
Peewee创建表
模型与数据库的映射关系:
Python 数据库 模型类 表 属性 字段 实例对象 数据 具体的使用方式:
创建数据库的实例
peewee.数据库对象()创建一个指定数据库的模型类
- 继承
peewee.Model- 重写类
Meta并指定database属性为数据库实例字段类型参考地址:模型和字段
例子:
from peewee import * # 1. 创建数据库实例 db = MySQLDatabase('tornado_db',host='192.168.30.151',port=3306,user='root',passwd='123') # pymysql # db = SqliteDatabase() # db = PostgresqlDatabase() # 2. 创建模型类 class Commany(Model): # 会默认生成ID, 表名是以类的小写为命名 name = CharField(verbose_name = '公司名称') full_name = CharField() year = IntegerField(2050) class Meta: database = db # 3. 映射表结构 def init_table(): db.create_tables([Commany]) if __name__ == '__main__': init_table()Peewee创建关联表
在实际的数据关系中,有可能会产生一些有关联性的数据,比如说:
课程表与学生表建立关系
- 1位学生报了哪门课程
- 1门课程都有哪些学生学习
公司表与产品表建立关系
- 1个公司有哪些产品
- 1类产品有哪些公司生产
问题
如何建立表之间的关联关系?
解决方案
使用字段
ForeignKeyField建立外键关系,ForeignKeyField是一种特殊的字段类型,它允许一个模型引用另一个模型例子:
from peewee import * from peewee import database_required # 1. 获取数据库的链接 db = MySQLDatabase('tornado_db',host='127.0.0.1',port=3306,user='root',passwd='123') # 创建一个基础模型类 class BaseModel(Model): class Meta: database = db # 2. 创建表的结构-模型类 class Commany(BaseModel): name = CharField(verbose_name='公司名称') full_name = CharField(verbose_name='公司全名称') year = IntegerField(verbose_name='开业时间') class Meta: table_name = 't_commany' class Music(BaseModel): name = CharField(verbose_name='音乐名称') singer = CharField(verbose_name='演唱者') duration = CharField(verbose_name='时长') _type = CharField(verbose_name='类型') # 3. 创建关联关系 # 如果没有写field,会默认用另一张表的主键做外键 # 会创建一响应的变量名ID,比如:commany_id commany = ForeignKeyField(Commany,verbose_name='版权所属',backref='musics') class Meta: table_name = 't_music' # 4. 映射表 def init_table(): db.create_tables([Commany,Music]) if __name__ =='__main__': init_table()ORM-peewee增加数据
在开发项目,避免不了数据的增加操作,比如说:
- 注册用户
- 增加购物车
- 增加关注
- 增加收藏
我们可用直接调用对象方法save即可
def add_one1(): c1 = Commany() c1.name ='CCTV' c1.full_name = '中央广播电视台' c1.year = 2000 c1.save() m1 = Music() m1.name = '青花瓷' m1.singer ='周杰伦' m1.duration = '2:30' m1._type = '流行' m1.commany = c1 m1.save() def add_one2(): m1 = Music(name='大鱼',singer = '周深',duration='2:00',_type='流行',commany=2 ) m1.save() def add_many(): for c in commanys: # print(c) c1 = Commany(**c) c1.save() for m in musics: m1 = Music(**m) m1.save() # print(m)案例数据:
commanys = [ { 'name': '滚石唱片', 'full_name': '滚石国际音乐股份有限公司', 'year': 1980 }, { 'name': '华谊兄弟', 'full_name': '华谊兄弟传媒股份有限公司', 'year': 1994 }, { 'name': '海蝶音乐', 'full_name': '北京太合音乐文化发展有限公司', 'year': 1986 }, ] musics = [ { "name": "你是我左边的风景", "singer": "林志炫", "duration": "2:20", "_type": "摇滚", "commany": 1 }, { "name": "把你揉碎捏成苹果", "singer": "薛之谦", "duration": "2:10", "_type": "摇滚", "commany": 3 }, { "name": "游戏人间", "singer": "童安格", "duration": "1:20", "_type": "流行", "commany": 2 }, { "name": "故乡的云", "singer": "费翔", "duration": "2:40", "_type": "摇滚", "commany": 1 }, { "name": "诺言Jason", "singer": "青城山下白素贞", "duration": "1:10", "_type": "古典", "commany": 3 }, { "name": "勇敢的幸福", "singer": "Sweety", "duration": "1:23", "_type": "古典", "commany": 2 }, { "name": "爱丫爱丫", "singer": "By2", "duration": "2:22", "_type": "流行", "commany": 1 }, { "name": "我也曾像你一样", "singer": "马天宇", "duration": "2:28", "_type": "流行", "commany": 1 } ]ORM-peewee查询数据
peeweee支持的运算符:
peeweee支持的方法:
Comparison Meaning ==x equals y <x is less than y <=x is less than or equal to y >x is greater than y >=x is greater than or equal to y !=x is not equal to y <<x IN y, where y is a list or query >>x IS y, where y is None/NULL %x LIKE y where y may contain wildcards **x ILIKE y where y may contain wildcards ^x XOR y ~Unary negation (e.g., NOT x) peeweee支持的逻辑运算符:
Method Meaning .in_(value)IN lookup (identical to <<)..not_in(value)NOT IN lookup. .is_null(is_null)IS NULL or IS NOT NULL. Accepts boolean param. .contains(substr)Wild-card search for substring. .startswith(prefix)Search for values beginning with prefix..endswith(suffix)Search for values ending with suffix..between(low, high)Search for values between lowandhigh..regexp(exp)Regular expression match (case-sensitive). .iregexp(exp)Regular expression match (case-insensitive). .bin_and(value)Binary AND. .bin_or(value)Binary OR. .concat(other)Concatenate two strings or objects using ||..distinct()Mark column for DISTINCT selection. .collate(collation)Specify column with the given collation. .cast(type)Cast the value of the column to the given type. 代码案例:
Operator Meaning Example &AND (User.is_active == True) & (User.is_admin == True)|(pipe)OR (User.is_admin) | (User.is_superuser)~NOT (unary negation) ~(User.username.contains('admin'))# Find the user whose username is "charlie". User.select().where(User.username == 'charlie') # Find the users whose username is in [charlie, huey, mickey] User.select().where(User.username.in_(['charlie', 'huey', 'mickey'])) Employee.select().where(Employee.salary.between(50000, 60000)) Employee.select().where(Employee.name.startswith('C')) Blog.select().where(Blog.title.contains(search_string))问题
运行代码,总是提示警告
Warning: (3090, "Changing sql mode 'NO_AUTO_CREATE_USER' is deprecated. It will be removed in a future release.") result = self._query(query)解决方案
在数据库中执行如下语句:
set @@GLOBAL.sql_mode=''; set sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';ORM-peewee更新数据
在开发的应用中,有的时候业务需要程序对数据修改的功能。比如:修改产品库存、更新用户会员等级、更新用户密码等操作。
在peewee中要更新数据,可以使用以下2种方式:
- 直接修改对象的属性,并保存(save)
- 通过类名.update方法修改,并执行(execute方法)
代码如下:
from models24 import Music def update_by_object(): m = Music.get_by_id(1) print(m.singer) m.singer = '林志炫666' # 还没更新到数据库 m.save() # 保存到数据库 def update_by_function(): # update table set field=value where field = arg sql_object = Music.update(singer = '林志炫').where(Music.id == 1) # 生成的SQL对象 sql_object.execute() def query_object(): m = Music.get_by_id(1) print(m.singer) if __name__ == '__main__': # update_by_object() # query_object() # update_by_function() query_object()ORM-peewee删除数据
在开发的应用中,有的时候业务需要程序对数据删除的功能。比如:删除用户、删除购物车信息、删除产品信息等操作。
在peewee中要删除数据,可以使用以下2种方式:
- 直接调用对象的
delete_instance方法- 通过
类名.delete方法,并执行(execute方法)代码如下:
def delete_by_object(): m = Music.get_by_id(8) m.delete_instance() # 不用考虑save方法 def delete_by_function(): # delete from table where field = args Music.delete().where(Music.id > 5).execute()注意:由于应用的数据比较宝贵,一般不会做真的删除。只是做伪删除(修改状态)!
peewee_async异步使用
对于使用peewee这个模块默认情况下是同步的框架,而在tornado中,需要尽量写异步的操作,用异步的库。因此我们只能考虑下这个peewee库如何才可以异步。
实际自己将peewee改成异步,虽然不难,但还是比较麻烦的。所以可以考虑找下github,看看有没有现成的peewee异步库。
现成的异步peewee库:github-peewee-async
安装:
PostgreSQL:
pip install --pre peewee-async; pip install aiopgMySQL:
pip install --pre peewee-async; pip install aiomysqlpeewee使用方法
类的创建基本与peewee一样,需要注意的是:
- 创建peewee_async异步的数据库实例
- 修改Model里面的database属性为 peewee_async的实例
数据的操作,需要注意是的使用异步:
通过 peewee_async.Manager(database) 对象操作数据
增加数据
- await peewee_async.Manager(database).create(类名,field属性=value)
执行SQL模型
- await peewee_async.Manager(database).execute(TestModel.select())
官网案例:
import asyncio import peewee import peewee_async # Nothing special, just define model and database: database = peewee_async.PostgresqlDatabase( database='db_name', user='user', host='127.0.0.1', port='5432', password='password' ) class TestModel(peewee.Model): text = peewee.CharField() class Meta: database = database # Look, sync code is working! TestModel.create_table(True) TestModel.create(text="Yo, I can do it sync!") database.close() # Create async models manager: objects = peewee_async.Manager(database) # No need for sync anymore! database.set_allow_sync(False) async def handler(): await objects.create(TestModel, text="Not bad. Watch this, I'm async!") all_objects = await objects.execute(TestModel.select()) for obj in all_objects: print(obj.text) loop = asyncio.get_event_loop() loop.run_until_complete(handler()) loop.close() # Clean up, can do it sync again: with objects.allow_sync(): TestModel.drop_table(True) # Expected output: # Yo, I can do it sync! # Not bad. Watch this, I'm async!案例:
from models29 import Music,manager import asyncio def create_data_by_model(): Music.create(name='我以为我可以一了百了',singer='林志炫',duration='3:10',_type='流行',commany=1) async def create_data_by_manager(): await manager.create(Music,name='逆战',singer='张杰',duration='2:10',_type='流行',commany=1) async def query_data_by_manager(): m_list = await manager.execute(Music.select()) for m in m_list: print(f'{m.id} == {m.name} == {m.singer}') if __name__ == '__main__': # create_data_by_model() loop = asyncio.get_event_loop() # loop.run_until_complete(create_data_by_manager()) loop.run_until_complete(query_data_by_manager())
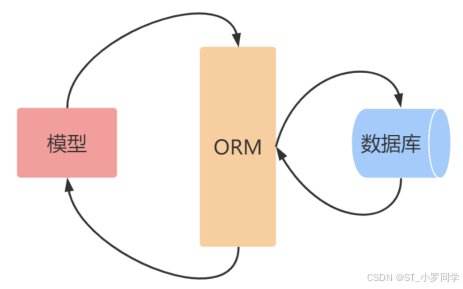
WTForms使用
WTForms是用于Python Web开发的灵活的表单验证和呈现库。它可以与您选择的任何Web框架和模板引擎一起使用。
WTForms文档 // WTForms_Tornado: Github
为了保证数据的合法性,因此需要做数据的验证。
Python安装:
pip install wtforms-tornado使用方式
创建表单类
需要继承
wtforms_tornado.Form定义字段类型
- 可以使用
wtforms.fields引入定义验证规则
- 可以使用
wtforms.validators引入创建表单对象
调用表单验证方法
案例:
import tornado.ioloop import tornado.web from wtforms.fields import IntegerField from wtforms.validators import Required from wtforms_tornado import Form class SumForm(Form): a = IntegerField(validators=[Required()]) b = IntegerField(validators=[Required()]) class SumHandler(tornado.web.RequestHandler): def get(self): self.write("Hello, world") def post(self): form = SumForm(self.request.arguments) if form.validate(): self.write(str(form.data['a'] + form.data['b'])) else: self.set_status(400) self.write("" % form.errors) application = tornado.web.Application([ (r"/", SumHandler), ]) if __name__ == "__main__": application.listen(8888) tornado.ioloop.IOLoop.instance().start()Tornado_wtfrom渲染模板
渲染模版是WTForms的第二个作用。具体功能就是通过Python代码生成html代码。
使用方式
表单对象.属性.label
- 获取带有label标签的属性
表单对象.属性.label.text
- 获取属性名
表单对象.属性()
- 获取对应表单元素
<form action="/" method="post"> {% autoescape None%} {% for f in uf %} {% if f.label.text == 'ID'%} <div class="form-group"> {{ f(class_="au-input au-input--full",placeholder=f.label.text) }} </div> {%else%} <div class="form-group"> {{ f.label }} {{ f(class_="au-input au-input--full",placeholder=f.label.text) }} </div> {% end %} {% end %} <button class="au-btn au-btn--block au-btn--green m-b-20" type="submit">确 认</button> </form>wtfrom与peewee结合使用
from tornado.web import Application,RequestHandler from tornado.ioloop import IOLoop from wtform32 import UserForm from models32 import User,manager class IndexHandler(RequestHandler): async def get(self): uf = UserForm() self.render('personal32.html',uf = uf) async def post(self): uf = UserForm(self.request.arguments) # 验证数据 if uf.validate(): del uf.data['id'] await manager.create(User,**uf.data) # 数据回显 self.render('personal32.html',uf = uf) else: self.render('personal32.html',uf = uf) if __name__ == '__main__': import os base_path = os.path.abspath(os.path.dirname(__file__)) # 设置应用参数 settings = { 'template_path':os.path.join(base_path,'templates'), 'static_path':os.path.join(base_path,'static'), 'static_url_prefix':'/static/', 'debug':True } # 创建tornado应用 app = Application([('/',IndexHandler)],**settings) # 设置监听端口号 app.listen(8000) # 事件循环开始 IOLoop.current().start()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











