









1、计算机硬件系统的5大功能部件
1945年,世界上出现了第一台电子数字计算机,取名ENIAC(埃尼阿克),主要用于计算弹道。它体积庞大,占地面积500多平方米,重量约30吨,功耗为170千瓦,这台计算机使用了17840支电子管,其运算速度为每秒5000次的加法运算。其运算速度为每秒5000次的加法运算。
计算机硬件发展历史
| 代 | 时间 | 硬件技术 | 速度 / (次/秒) |
|---|---|---|---|
| 1 | 1946-1957 | 电子管 | 40 00 |
| 2 | 1958-1964 | 晶体管 | 200 000 |
| 3 | 1965-1971 | 中小规模 集成电路 | 1 000 000 |
| 4 | 1972-1977 | 大规模 集成电路 | 10 000 000 |
| 5 | 1978-现在 | 超大规模 集成电路 | 100 000 000 |
“计算机之父”-冯·诺依曼
他的精髓贡献是两点:二进制思想与程序内存思想。
著名的“冯·诺依曼机”包括:运算器、逻辑控制装置、存储器、输入和输出设备五大部分,该结构一直沿用到今。
计算机硬件系统
现代计算机结构框图

2、计算机软件分类及编程语言的前世今生
计算机软件分类

二进制思想
- 采用有限个状态(用0和1)来表示、处理、存储和传输数据的技术。
- 计算机中的一切内容都是数字0、1。
从物理世界到计算机世界
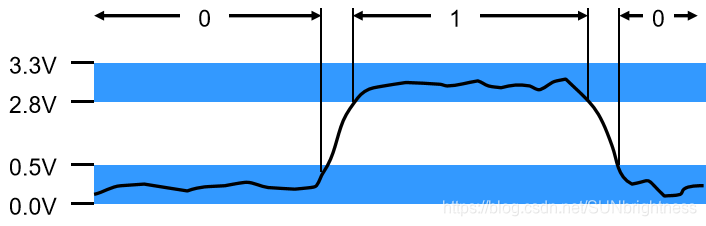
众所周知物理中后的 电流 与 电压 。计算机只能识别二进制,我们规定:
大于某个某个电压的电流就代表你输入了1
小于某个电压你就输入了0
为什么是二进制?
你想想,你把计算机设计成10进制,就需要给给电压设置10个水准。
一个瓜子是切成两半好控制还是切成10瓣好控制?
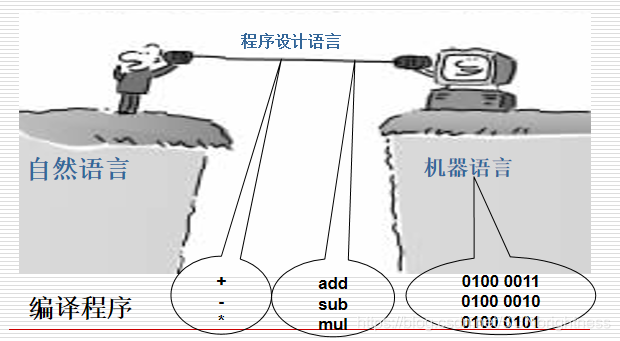
编程语言的前世今生
从上面了解到了一个真理:
计算机只能识别二进制
现在幻想是你发明的计算机:
你想实现增值运算
你得用一串二进制代表这个是一个
+,你决定使用0100 0011代表+你想实现增值运算
你得用一串二进制代表这个是一个
-,你决定使用0100 0010代表-你发现这样太费劲了,不如开发一个东西,让他把
add这个单词转换成0100 0011吧一门以二进制为底层的变成语言被你创造了。
…
有一天,你连
add都嫌费劲了,因为需要敲3下键盘。于是乎,你再次创造了一门变成语言将
+转换成add。
3、计算机如何执行你的程序
- 把程序和数据装入到主存储器中。
- 从程序的起始地址运行程序。
- CPU的工作非常简单,它从内存中获取一个指令并执行该指令,然后从内存中获取下一个指令并执行。CPU能以惊人的速度来从事枯燥的工作(机器是很辛苦的)。
- 每条指令都要经过取指、译码、执行。
计算机的性能指标
-
机器字长
进行一次运算所能处理的二进制数据的位数
-
主存容量
指主存所能存储的最大容量
-
运算速度
衡量性能的一个重要指标。CPU时钟周期、主频、MIPS(Million Instructions Per Second)等
-
数据通路带宽
数据总线一次并行传递数据的位数。
4、进制的世界
什么是进制?
N 进制的每一位最高只能是N-1,
根据10进制好好想一想阿拉伯数字:九,再往上,想要表达十应该如何去书写?
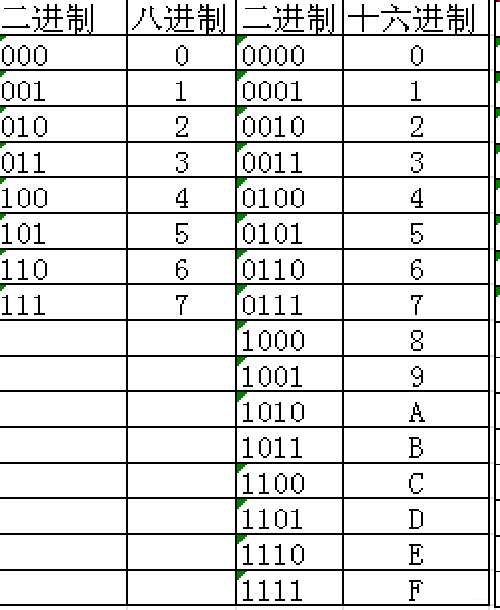
| `10进制 | 2进制 | 8进制 | 16进制 |
|---|---|---|---|
| 10 | 1010 | 12 | a |
| 11 | 1011 | 13 | b |
| 12 | 1100 | 14 | c |
| 13 | 1101 | 15 | d |
| 14 | 1110 | 16 | e |
| 15 | 1111 | 17 | f |
| 16 | 10000 | 20 | 10 |
进制间的转换
10 进制 -> N进制
整数部分:除p倒取余
小数部分:乘P正取整
例如26.325转换成二进制
整数部分
| 计算 | 值 | 余数 |
|---|---|---|
| 26/2=13…0 | 13 | 0 |
| 13/2=6…1 | 6 | 1 |
| 6/2=3…0 | 3 | 0 |
| 3/2=1…1 | 1 | 1 |
| 1/20…1 | 0 | 1 |
计算完毕。
倒取余为:11010
小数部分
| 计算 | 整数部分 | 小数部分 |
|---|---|---|
| 0.325*2=0.65 | 0 | 65 |
| 0.65*2=1.3 | 1 | 3 |
| 0.3*2=0.6 | 0 | 6 |
| 0.6 *2=1.2 | 1 | 2 |
| 0.2*2=0.4 | 0 | 4 |
| 0.4*2=0.8 | 0 | 8 |
| 0.8*2=1.6 | 1 | 6 |
计算完毕
(26.325)10 = (11010.0101001)2
关于小数的计算完毕
1、小数部分为0。
2、在数学中,存在无穷的的小数3.1415926……,算不完呀,只能精确到一定位数。
10 进制 -> N进制
N 进制==->==10进制`
将各位数码和其
权值相乘后求和,即可转换成十进制.
权值
请细细品位何为权值。
| 二进制数 | 等价的权值 |
|---|---|
| 1 | 20 |
| 10 | 21 |
| 100 | 23 |
| 1000 | 24 |
例: 10110转换成十进制
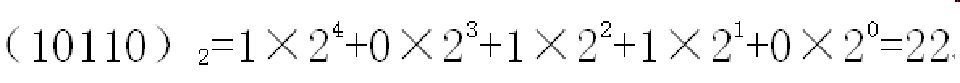
进制间的转换
5、非数值数据的编码
如上所述我们已经了解了计算机是如何在二进制世界中表示数字的。
那各种字符该怎么表示呢?
举个例子。你当下看到的:汉字、A ,他们肯定是对应着某个2进制吧?
接下来,了解一下 字符编码 的发展里程把。
ASCII编码
ASCII(American Standard Code for Information Interchange),用7个bit位表达128个符号。
American :美国
美国人发明了计算机,他们发明了一种规则,某个二进制对应某个字符这就是ASCII
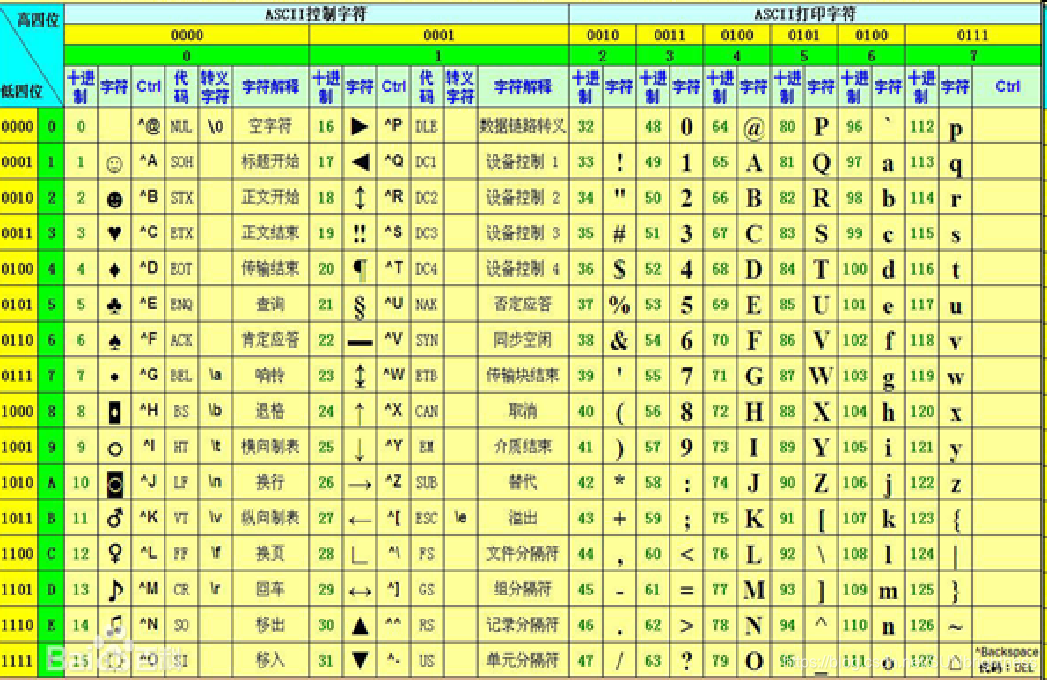
一开始是 7个 bit为的 ascii 编码,后来他们感觉不够用,又扩展了一些。
扩展的ASCII码
在原有的基础上扩展到8位。

GB2312
ASCII 码只有英文,没办法表示汉字呀,就在此时,我们的中文编码
国标2312应时而出。
- 《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB 2312—1980。
- GB 2312标准共收录6763个汉字,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆**99.75%**的使用频率。
- GB 2312把127号之后的字符取消掉,使用2个大于127的字节连在一起表示1个字符。大约表示了7000多个简体汉字。GB2312是对ASCII的中文扩展。
2个大于127的字节排列组合是远远大于,7000,之所以如此是为了留出空间兼容
ASCII
Unicode
如上两种编码产生一个问题。那就是
乱码中国有GB2312,美国有ASCII、日本有……、韩国有……当计算机网络面向世界的时候,这些都成为了很严重的问题。
unicode 正是为了结束这个三国混战的局面 而出现的。
- Unicode( Universal Multiple-Octet Coded Character Set通用多八位编码字符集),简称UCS。
- Unicode(统一码、万国码、单一码)是一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
- 在很多现代技术中,比如现代操作系统,Java语言等中都采用了Unicode标准规范。
Unicode面临的问题
如何将其与ASCII区别开来?英文字符的冗余问题。
因为unicode需要兼容一切所以他必然要适应哪些文字比较多的编码。
同样表示一个相同的字符。
不保证下方数值准确性,只为打比方
| Unicode | ASCII |
|---|---|
| 0100 0101 0010 0100 0101 0111 | 0000 0000 0000 0000 0100 0001 |
美国人:
前面这么多零是什么意思?
这样岂不是我们所有的数据都需要浪费这么多的空间去存储一大堆的0
UTF
utf 的出现打破了unicode尴尬的局面
- UTF(Universal Character Set Transformation Format)通用字符集转换格式
- 在UTF中主要有UTF-8,UTF-16和UTF-32。
- UTF-8 每次传输8位数据,UTF-16每次传输16位数据。
- UTF-8是变长字节编码方案,使用1-4个字节表示一个符号。
解释一下
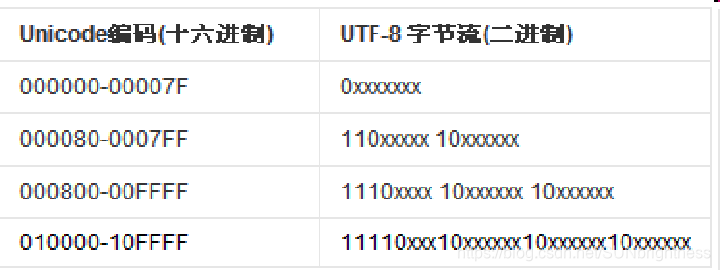
为什么说utf 是的字节长度是可变的呢?
根据上面的图片来看。
utf-8 使用了一种比之 Unicode 来说比较聪明的做法。他可以说是Unicode 的延伸
制定不同的区间 ,使用不同的前缀来节省空间。
比如计算机要解码一串 UTF-8的二进制 :
01010010 11010010 10010010 01010010 11010010 10010010 01010010 11010010 10010010 01010010 11010010 10010010(我瞎编的)
计算机一次取8位。
``01010010`
一看 0 打头。哦,这是8个字节的字符。01010010 变成字符把
接下来
11010010
一看110打头。哦,这是一个 16个字节的字符。于是乎11010010 10010010变成字符把
……
例子:
Unicode中一个中文占2个字节,但是在UTF-8中,一个中文字符占3个字节(多出来一些前缀)。
| 汉字 | Unicode编码16进制 | Unicode编码2进制 | UTF-8的编码 |
|---|---|---|---|
| 知 | 0077e5 (000800-00FFFF) | 0111 0111 1110 0101 | 1110 0111 1001 1111 1010 0101 |
6、带符号数的表示及运算
无符号数和有符号数
- 采用数字化方式来表示数据,数据有无符号数和带符号数之分,其中带符号数用‘0’表示‘正’号,用‘1’表示‘负’号。运算的时候为了统一处理数字位和符号位,演化出原码、补码和反码****3种表示形式。
- 补码的应用居多,原因是补码可以带符号运算而且可以变减为加。
- [x-y]补=[x]补+[-y]补
定点数
在定点数表示法中约定:所有数据的小数点位置固定不变。
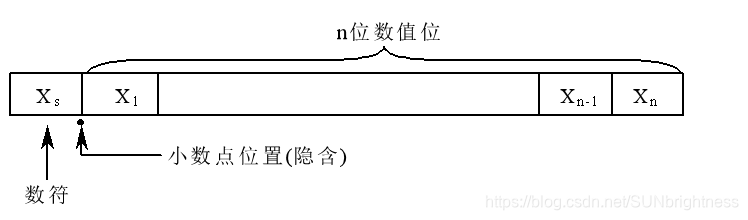
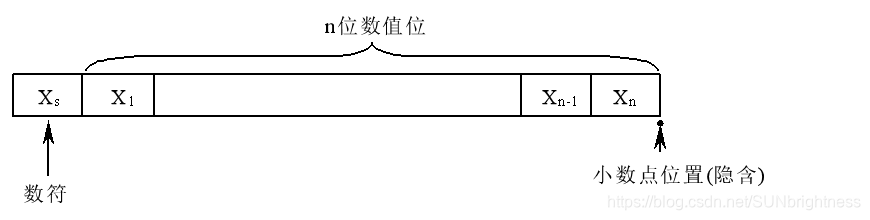
浮点数
小数点的位置根据需要而浮动,这就是浮点数。
例如:
例如:
- r为浮点数阶码的底,与尾数的基数相同,通常r=2。E和M都是带符号数,E叫做阶码,M叫做尾数。
- 为了提高运算的精度,M一般取规格化形式,即规定尾数的最高数位必须为有效值。
溢出概念
-
溢出是指运算结果超出了数的表示范围。
-
例如:4个bit位的状态
4bit表示的范围0—15
1111+ 1
10000

精度
- 对于字长相同的定点数和浮点数来说,浮点数虽然扩大了数的表示范围,但是精度降低了。
- 在实际编程中由于精度问题,会导致一些错误。比如:3和1/3的乘积应该是1.0,但是若用6位小数表示1/3,乘积为0.999999而不等于1.0.造成一些逻辑判断错误,或者运算结果精度不够。
- 建议搞清楚程序面对的问题规模,选择合适精度的数据类型。不能一概采用float。


















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











