







文章目录
4.1 串的定义和实现
4.1.1 串的定义


串是一种特殊的线性表,数据元素之间呈线性关系 ;
串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等);
串的基本操作,如增删改查等通常以子串为操作对象。
4.1.2 串的基本操作

4.1.3 串的存储结构
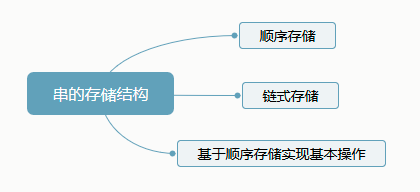
1. 顺序存储


2. 链式存储

3. 基于顺序存储实现基本操作

顺序存储结构
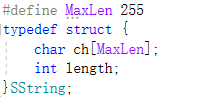
1. SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。

2. StrCompare(S,T):比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。

3.Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的 位置;否则函数值为0。

4.2 串的模式匹配
4.2.1 简单的模式匹配算法
子串的定位操作通常称为串的模式匹配,它求的是子串(常称模式串)在主串中的位置。这里采用定长顺序存储结构,给出一种不依赖其他串操作的暴力匹配算法。


算法性能分析:


4.2.1 改进的模式匹配算法 —— KMP算法
朴素(简单)模式匹配算法的缺点:当某些子串与模式串能部分匹配时,主串的扫描指针i经常回溯,导致时间开销增加。
改进思路:主串指针不回溯,只有模式串指针回溯。
kmp算法的关键:next数组。
1. 步步模拟得到next数组 + Kmp算法代码
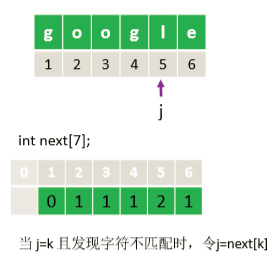
下面以 ‘google’ 为例进行说明:



最终得到:

这样就可以得出next数组了:
KMP算法实现:

2. next数组 (手算)
串的前缀:包含第一个字符,且不包含最后一个字符的子串
串的后缀:包含最后一个字符,且不包含第一个字符的子串
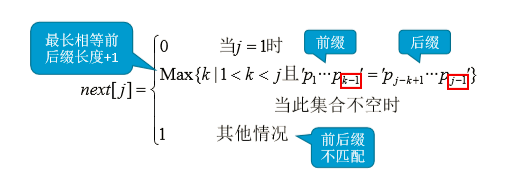
next数组手算方法:当第j个字符匹配失败,由前1~j-1个字符组成的串记为S,则 next[j]=S的最长相等前后缀长度+1。特别地,next[1] = 0、next[2] = 1。
练习:

3. next数组(机算)
上面手算next数组很快捷,但是想用代码实现的时候,却发现无从下手。下面尝试推理求解的科学步骤。
下图是next数组的公式,与上面的手算公式其实是一样的。
用例子理解:
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 模式 | a | b | a | a | b | c | a | b | a |
| next[j] | 0 | 1 | 1 | 2 | 2 | 3 | ? | ? | ? |
求next[7],因为next[6]=3,说明p1p2=p4p5,因此比较p3、p6。
如果相等,则next[7]=next[6]+1。
如果不相等,就寻找更短的最长相等前后缀。
显然p3与p6不等,去寻找更短的最长相等前后缀,next[3]=1,所以比较p1、p6,p1与p6不等,ok,再寻找更短的,next[1]=0,没有p0,无法比较下去。那么next[7]=1。
求next[8],已知next[7] = 1,因p7=p1(都是a),所以next[8] = next[7] + 1 = 2;
求next[9],已知next[8] = 2,因p8=p2,所以next[9] = next[8] + 1 = 3。
注:next数组实现的代码在4.中。
4. next数组算法代码 + Kmp算法代码

KMP算法仅在主串与子串有很多 “部分匹配” 时才显得比普通算法快得多,其主要优点是主串不回溯。
4.2.3 KMP算法的进一步优化 —— nextval数组
前面定义的next数组在某些情况下尚有缺陷,还可以进一步优化。
如下图1所示,模式串‘aaaab’在和主串进行匹配时,当i=4,j=4时发生失配,根据之前的next数组接下来要进行如图2、3、4的3次比较,很明显,这三次比较是无意义的。
其实直接从i=5、j=1开始比较就行。我们发现,将字母相同的next[j]改为一致的(从左向右),仍然可以实现匹配,而且还减少了许多不必要的比较。那么我们就可以得到nextval数组,如下图5.





nextval数组实现代码:
//nextval数组
void get_nextval(SString T, int nextval[]) {
int i = 1, j = 0;
nextval[1] = 0;
while (i < T.length) {
if (j == 0 || T.ch[i] == T.ch[j]) {
i++;
j++;
if (T.ch[i] != T.ch[j]) nextval[i] = j;
else nextval[i] = nextval[j];
}
else
j = nextval[j];
}
}















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









