






 本文通过对比Python和R在循环与递归操作中的性能,发现Python在大多数情况下速度比R快7倍左右。虽然R在数据可视化和统计分析上有优势,但Python在机器学习和大数据处理上的表现更优,尤其是在循环和递归等运算上。
本文通过对比Python和R在循环与递归操作中的性能,发现Python在大多数情况下速度比R快7倍左右。虽然R在数据可视化和统计分析上有优势,但Python在机器学习和大数据处理上的表现更优,尤其是在循环和递归等运算上。
R和Python都是生信分析中经常用到的编程语言,两者各有各的优势。R在数据可视化、统计分析方面较Python更为强大,而Python则在机器学习、大数据处理方面更具优势。
但无论是Python还是R,它们的运算速度或者说性能都较为一般,这一点是由自身语言特性所决定的——两者都是解释型语言,也就是在运行时逐行解释和执行代码,而不需要在编译阶段将代码转换为机器码。
那么,Python和R,谁会更快一些呢?这或许并不是一个好的问题,因为没有假设特定的场景,也没有说明要比较的方面,自然也就无从说起谁快谁慢。但是一般而言,在多数场景下,Python都要比R更快,那么快多少呢?

为了说明这个问题,我们粗略地比较了一下两者在循环、递归方面的性能差异。由于性能差异可能会因编写方式、优化技巧和使用的特定库而有所不同,因此下面的代码中,需要尽可能地保持代码简单直接,同时除了时间模块外不引入其他第三方库。
循环
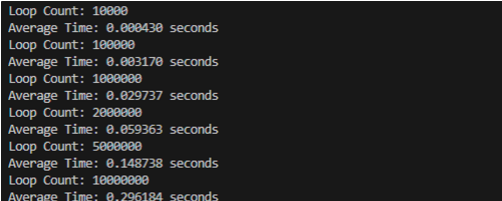
在下面的代码中,分别计算了python和R在10K, 100K, 1000K, 2000K, 5000K, 10000K的循环次数下所运行的平均时间,循环体内的操作为自增操作。
- Python
# 导入时间模块``import timeit`` ``# 循环执行时间的比较函数``def compare_loop_performance(loop_count):` `result = timeit.repeat('''``for i in range(1, {}+1):` `i += 1` `'''.format(loop_count), repeat=10, number=1)`` ` `avg_time = sum(result) / len(result)` `return f"Average Time: {avg_time:.6f} seconds"`` ``# 循环不同次数的性能比较``loop_counts = [10000, 100000,1000000,2000000,5000000,10000000]``for count in loop_counts:` `print(f"Loop Count: {count}")` `print(compare_loop_performance(count))
- R
# 加载时间模块``library(microbenchmark)``# 循环执行时间的比较函数``compare_loop_performance <- function(loop_count) {` `result <- microbenchmark(``for (i in 1:loop_count) {` `i = i + 1` `},``times = 10` `)` `avg_time <- mean(result$time) / 1e9 # 计算平均时间并转换为秒``return(paste("Average Time:", avg_time, "seconds"))``}``# 循环不同次数的性能比较``loop_counts <- c(10000, 100000,1000000,2000000,5000000,10000000)``for (count in loop_counts) {``print(paste("Loop Count:", count))``print(compare_loop_performance(count))``}
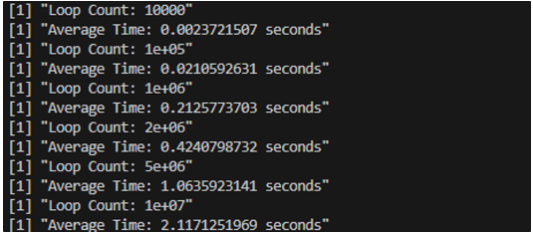
下面是Python和R运行所花费的平均时间的比较,可以看到,在循环的情况下,Python比R快7倍。
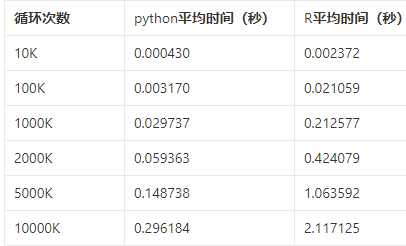
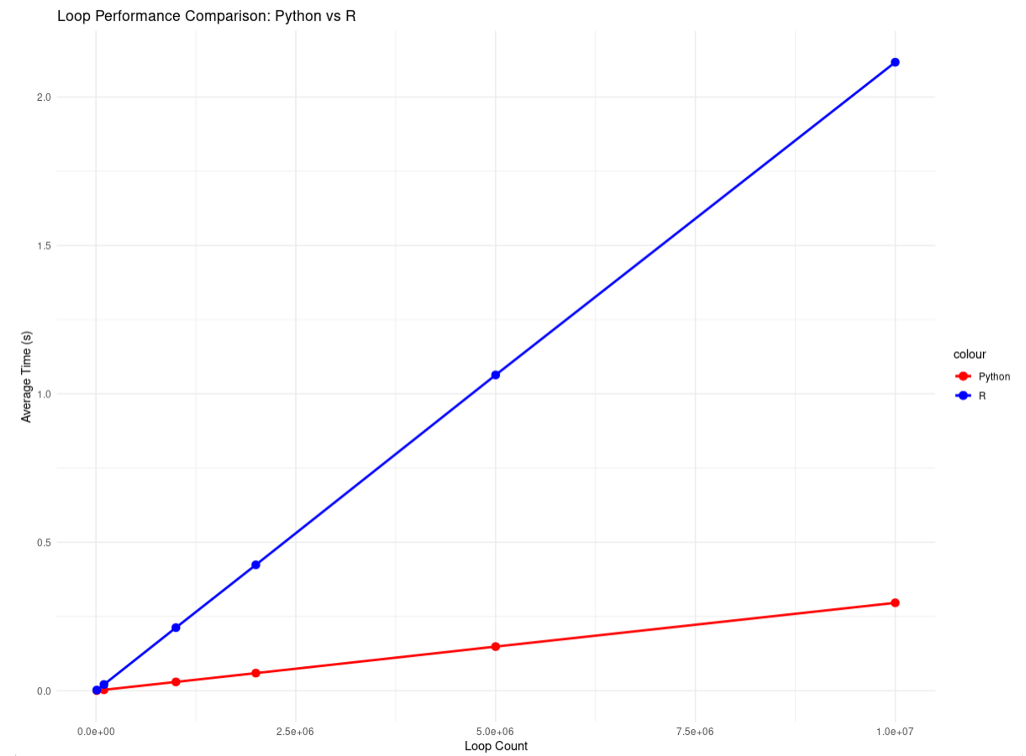
递归
由于递归是极为耗费时间的操作,因此递归的深度不可能太大。下面的代码中,分别计算了python和R在递归次数为10,15,20,30,35,36,37,38,39,40所耗费的时间。递归操作为计算前两次递归返回的值和,这其实是在计算斐波那契数列。
- Python
import time`` ``def recursive_function(n):` `if n <= 1:` `return n` `else:` `return recursive_function(n - 1) + recursive_function(n - 2)`` ``recursive_counts = [10,15,20,30,35,36,37,38,39,40]``python_times = []`` ``for count in recursive_counts:` `start_time = time.time()` `result = recursive_function(count)` `end_time = time.time()` `execution_time = end_time - start_time` `execution_time_formatted = "{:.6f}".format(execution_time)` `python_times.append(execution_time)` `print(f"Python - Loop Count: {count}, Time: {execution_time_formatted} seconds")
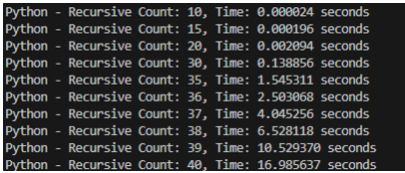
- R
recursive_function <- function(n) {` `if (n <= 1) {` `return(n)` `} else {` `return(recursive_function(n - 1) + recursive_function(n - 2))` `}``}`` ``recursive_counts <- c(10,15,20,30,35,36,37,38,39,40)``r_times <- numeric(length(recursive_counts))`` ``for (count in recursive_counts) {` `start_time <- Sys.time()` `result <- recursive_function(count)` `end_time <- Sys.time()` `execution_time <- as.numeric(difftime(end_time, start_time, units = "secs"))` `r_times[length(r_times) + 1] <- execution_time` `cat("R - Recursive Count:", count, "Time:", execution_time, "seconds\n")``}
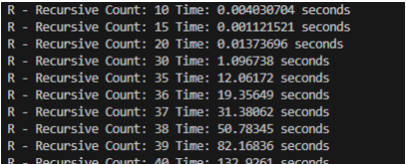
下面是两者所耗费的时间的比较,可以看到,python在递归次数达到35的时候,运行的时间超过了1s,而R在递归次数30的时候,所用的时间就超过了1s。可见对于递归操作,所用的时间增长速度极快,因此在实际数据处理中,尽量减少使用。
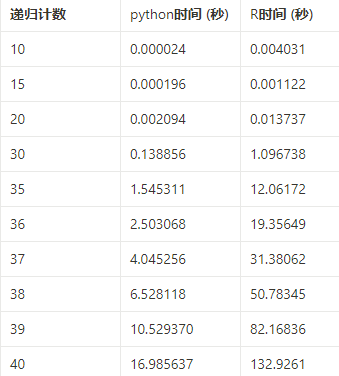
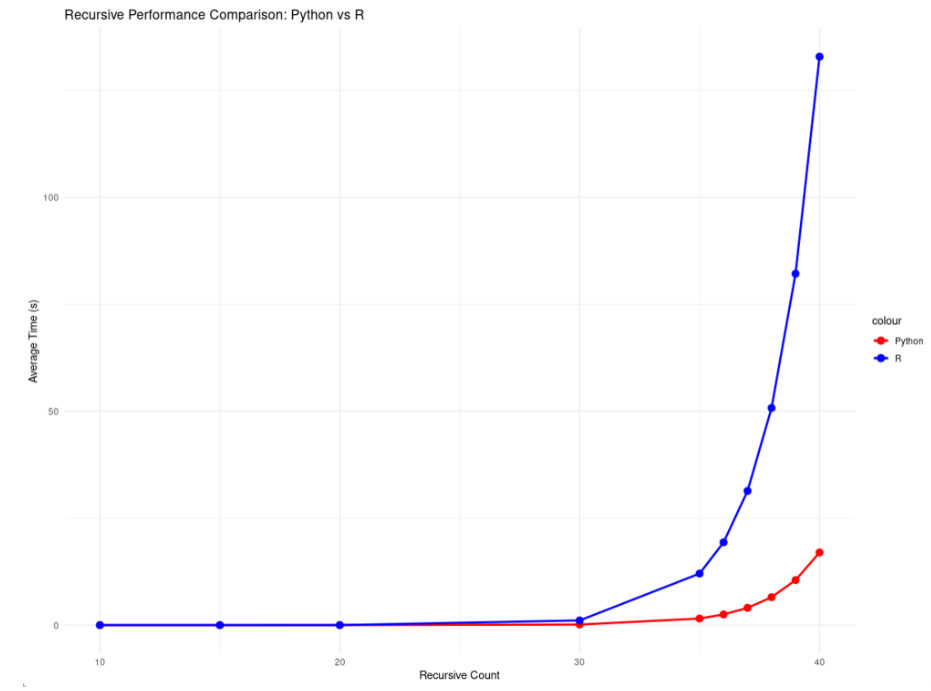
总的来说,无论是循环还是递归操作,Python比R都要快。在我的机器上,两者的性能的差异达到了7~8倍。当然,对于不同的硬件和运行环境,所得出的结果可能会不同。

题外话

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









