







Lesion 7 Using SET Operators
*******************************************************************************
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
Intersect:对两个结果集进行交集操作,同时进行默认规则的排序;
Minus:对两个结果集进行差操作,同时进行默认规则的排序。
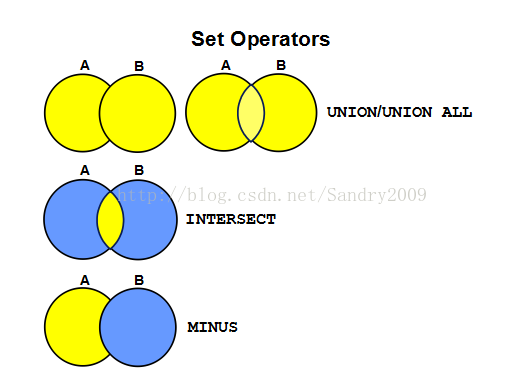
注:默认排序规则是按第一个字段的升序进行排序。
*******************************************************************************
create table myemployees
as
select * from employees where department_id = 90;
select count(*) from employees;
(20 rows)
select count(*) from myemployees;
(3 rows)
*******************************************************************************
select first_name,last_name from employees
union
select first_name,last_name from myemployees;
(20 rows)
*******************************************************************************
select first_name,last_name from employees
union all
select first_name,last_name from myemployees;
(23 rows)
*******************************************************************************
select first_name,last_name from employees
intersect
select first_name,last_name from myemployees;
(3 rows)
*******************************************************************************
select first_name,last_name from employees
minus
select first_name,last_name from myemployees;
(17 rows)
比较
select first_name,last_name from myemployees
minus
select first_name,last_name from employees;
(0 rows)
注:在使用minus求差集时,一定要将数据多的查询放在数据少的查询上方。
*******************************************************************************
select first_name from employees
intersect
select first_name,last_name from myemployees;
ERROR at line 1:
ORA-01789: query block has incorrect number of result columns
注:两个结果集中的列在数量、顺序和数据类型要保持一致。
*******************************************************************************
select first_name,last_name from employees
intersect
select first_name,last_name from myemployees
order by last_name;
比较
select first_name,last_name from employees order by last_name
intersect
select first_name,last_name from myemployees;
ERROR at line 2:
ORA-00933: SQL command not properly ended
注:默认排序规则是按第一个字段的升序进行排序,可以在最后指定Order by子句改变排序方式,order by一定要放在最后,是对整个结果集进行排序。
*******************************************************************************
select first_name fn,last_name ln from myemployees
intersect
select first_name,last_name from myemployees
order by ln;
select first_name fn,last_name ln from employees
intersect
select first_name ,last_name from myemployees
order by first_name;
ERROR at line 4:
ORA-00904: "FIRST_NAME": invalid identifier
注:系统会把第一个查询出的列名显示在输出中。这里已为first_name起别名fn
*******************************************************************************
SELECT employee_id, department_id
FROM employees
WHERE (employee_id, department_id)
IN (SELECT employee_id, department_id
FROM employees
UNION
SELECT employee_id, department_id
FROM job_history);
注:集合运算符可以用在子查询中。
*******************************************************************************
层次查询(Hierarchical Queries)
层次查询使用树的遍历,走遍含树形结构的数据集合,来获取树的层次关系报表的方法
树形结构的父子关系,你可以控制:
(1)遍历树的方向,是自上而下,还是自下而上
(2)确定层次的开始点(root)的位置
层次查询语句正是从这两个方面来确定的,start with确定开始点,connect by确定遍历的方向。
select [level], column, expr...
from table
[where condition]
start with condition
connect by [prior column1= column2 |olumn1 = prior column2];
(1)level是伪列,表示等级
(2)Where条件限制了查询返回的行,但是不影响层次关系,属于将节点截断,但是这个被截断的节点的下层child不受影响
(3)prior是个形容词,可放在任何地方
(4)彻底剪枝条件应放在connect by;单点剪掉条件应放在where子句
select employee_id, last_name, manager_id
from employees
start with employee_id=100
connect by prior employee_id=manager_id;
select employee_id, last_name, manager_id
from employees
start with employee_id=124
connect by prior employee_id=manager_id;
select employee_id, last_name, manager_id
from employees
start with employee_id=141
connect by prior manager_id=employee_id;
select employee_id, last_name, manager_id
from employees
start with employee_id=100
connect by prior employee_id=manager_id and employee_id!=102;
select employee_id, last_name, manager_id
from employees
where employee_id!=102
start with employee_id=100
connect by prior employee_id=manager_id;
*******************************************************************************
Lesion 8 Manipulating Data
*******************************************************************************
Common errors that can occur during user input:
Mandatory value missing for a NOT NULL column
Duplicate value violates uniqueness constraint
Foreign key constraint violated
CHECK constraint violated
Data type mismatch
Value too wide to fit in column
******************************************************************************
SQL>show autocommit
autocommit OFF
SQL>SET AUTOCOMMIT ON
SQL>SET AUTOCOMMIT OFF
注:Oracle默认不自动提交,SQLServer默认自动提交。
*******************************************************************************
Redo insert commit
Undo update rollback
*******************************************************************************
事务的特征:(转账举例)
原子性 表示事务具有不可分割性,同一各事务的操作要么一起成功,要么一起失败
一致性 当事务结束时,内存数据的状态与数据库状态保持一致
隔离性 多个事务之间互不干扰
持久性 当事务正常提交后,则数据会永久存放在数据库中
*******************************************************************************
并发控制
当多个数据库事务对同一个对象做出访问操作时,就会产生并发;为了保证数据的一致性,DBMS会做并发访问控制。
*******************************************************************************
锁
create table test(c1 number, c2 number);
同时开两个窗口,即开启两个session,每个session中即是一个事务。
1)对test表进行操作。在窗口1中做DML操作,但是没有commit;,那么
在窗口2中做drop table操作。出现BUG。如果在窗口1做完DML操作后
就commit,那么在窗口2中做drop table操作。成功。
2)在窗口1中做select * from test where c1=1 for update;那么在窗口2
中做insert,对除了c1=1的那条delete或者update操作都可以。但是如果
在窗口2对c1=1的那条记录做delete或者update操作的话,将会出现等待
的情况直至在窗口1中commit。
3)在窗口1中做select * from test for update;那么在窗口2中做insert操
作可以,但是如果在窗口2对做delete或者update操作的话,将会出现等
待的情况直至在窗口1中commit。
*******************************************************************************
在Oracle中事务两个隔离级别:read committed 和 serializable
(1)read commited(Oracle默认的隔离级别)
同时开两个窗口,即开启两个session,每个session中即是一个事务。
1)对test表进行操作。在窗口1中,执行insert into test values(1,1);
然后执行select * from test;可以看到新插入的数据(1,1),但是在窗口2中执
行select * from test;都看不到插入的数据。只有在窗口1中commit;后,窗口2执行select * from test;才能看到新插入的数据。
2)在窗口1中,t1时刻执行了select * from test;但是此查询可能要执行很长时间
才能显示查询的数据,在窗口2中在t2时刻执行了update语句,并且commit,
等到t3时刻,窗口1显示了查询数据,那么在窗口1中读到的数据是在t1时刻数
据库中的数据,而不是t2时刻窗口2update后commit的数据。
更改数据库事务的隔离级别:
set transaction isolation level [serializable / read committed]
(2)serializable
同时开两个窗口,即开启两个session,每个session中即是两个事务。
对test表进行操作,在窗口1中insert into test values(2,2);然后commit;然后
执行select * from test;可以看到新增的数据(2,2)。但是在窗口2中执行select *
from test;仍看不见新增的数据(2,2)。
*******************************************************************************
无条件 Insert all --多表多行插入
语法:
INSERT [ALL]
[condition_insert_clause]
[insert_into_clause values_clause]
(subquery)
示例:
INSERT ALL
INTO sal_history(emp_id,hire_date,salary) values (empid,hiredate,sal)
INTO mgr_history(emp_id, hire_date,salary) values (empid,hiredate,sal)
SELECT employee_id empid,hire_date hiredate,salary sal
FROM employees
WHERE employee_id>200;
注:向两个表插入了数据,虽然最终插入到表中的数据在列上有所区分,但是插入到这两个表的数据的来源是一样的。
有条件的Insert
语法:
INSERT [ALL | FIRST]
WHEN condition THEN insert_into_clause values_clause
[WHEN condition THEN] [insert_into_clause values_clause]
......
[ELSE] [insert_into_clause values_clause]
Subquery;
示例:
Insert All
when id>5 then into z_test1(id, name) values(id,name)
when id<>2 then into z_test2(id) values(id)
else into z_test3 values(name)
select id,name from z_test;
注:
1、当使用ALL关键字时,oracle会从上至下判断每一个条件,当条件满足时就执行后面的into语句。在上面的例子中,如果ID=6 那么将会在z_test1中插入一条记录,同时也在z_test2中插入一条记录
2、当使用FIRST关键字时,oracle会从上至下判断每一个条件,当遇到第一个满足时就执行后面的into语句,同时中断判断的条件判断,在上面的例子中,如果ID=6,仅仅会在z_test1中插入一条数据。
旋转插入Pivoting INSERT
示例:
INSERT ALL
INTO sales_info VALUES (employee_id,week_id,sales_MON)
INTO sales_info VALUES (employee_id,week_id,sales_TUE)
INTO sales_info VALUES (employee_id,week_id,sales_WED)
INTO sales_info VALUES (employee_id,week_id,sales_THUR)
INTO sales_info VALUES (employee_id,week_id, sales_FRI)
SELECT EMPLOYEE_ID, week_id, sales_MON, sales_TUE,sales_WED, sales_THUR,sales_FRI
FROM sales_data;
1、旋转Insert是无条件 insert all 的一种特殊应用,但这种应用被oracle官方,赋予了一个pivoting insert的名称,即旋转insert。
2、旋转Insert的不同之处在于所有的into子句都使用同一张表
*******************************************************************************
Lesion 9 Using DDL Statements to Create and Manage Tables
*******************************************************************************
CREATE TABLE employees_test(
employee_id NUMBER(6) CONSTRAINT emp_employee_id PRIMARY KEY,
first_name VARCHAR2(20),
last_name VARCHAR2(25) CONSTRAINT emp_last_name_nn NOT NULL,
email VARCHAR2(25)
CONSTRAINT emp_email_nn NOT NULL
CONSTRAINT emp_email_uk UNIQUE,
phone_number VARCHAR2(20),
hire_date DATE CONSTRAINT emp_hire_date_nn NOT NULL,
job_id VARCHAR2(10) CONSTRAINT emp_job_nn NOT NULL,
salary NUMBER(8,2) CONSTRAINT emp_salary_ck CHECK (salary>0),
commission_pct NUMBER(2,2),
manager_id NUMBER(6),
department_id NUMBER(4)
);
INSERT INTO employees_test (EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,DEPARTMENT_ID)
VALUES
(100,'Steven','King','SKING','515.123.4567','17-JUN-87','AD_PRES',24000,90);
create table employees_test_copy
as
select * from employees_test;
INSERT INTO employees_test_copy (EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,MANAGER_ID,DEPARTMENT_ID)
VALUES
(null,'Bruce','Ernst','BERNST','590.423.4568','21-MAY-91','IT_PROG',-6000,103,60);
注:子查询建表,完整性规则不会被传递到新表中,仅列的数据类型定义和非空约束被传递到新表中。
*******************************************************************************
CREATE TABLE dept80
AS
SELECT employee_id, last_name, salary*12, hire_date
FROM employees
WHERE department_id = 80;
ERROR at line 3:
ORA-00998: must name this expression with a column alias
*******************************************************************************
ALTER TABLE table_name
ADD(column_name datatype [DEFAULT expr] [, column_name datatype]...);
增新列原则:
可以添加或修改列。
不能指定新添加的列出的位置,新列将成为最后一列。
ALTER TABLE table_name
MODIFY(column_name datatype [DEFAULT expr][, column_name datatype]...);
修改列原则:
可以改变列的数据类型、大小和默认值,但仅在该列中只包含空值或表中没有行时。
对默认值的改变仅影响以后插入的列。
ALTER TABLE table_name DROP COLUMN column_name ;
删除列原则:
删除列时,列可以有也可以没有数据。
用ALTER TABLE语句,一次只能有一列被删除。
表被修改后必须至少保留一列。
一旦一列被删除,它不能再恢复。
当一列从表中被删除时,该表中任何其他的被用SET UNUSED选项标记列,也被删除。
*******************************************************************************
在DML语句中使用子查询
1.INSERT
INSERT INTO employees (EMPLOYEE_ID,FIRST_NAME,JOB_ID,salary)
SELECT emptno,ename,job,sal FROM emp;
2.UPDATE
UPDATE emp SET (sal,comm)=(SELECT sal,comm FROM emp WHERE ename='SMITH')
WHERE job=(SELECT job FROM emp WHERE ename='SMITH');
3.DELETE
DELECT FROM emp WHERE deptno=(SELECT deptno FROM dept WHERE dname='SALES');
在DDL语句中使用子查询
1.CREATE TABLE
CREATE TABLE new_emp(id,name,sal,job,deptno)
AS
SELECT emptno,ename,sal,joob,deptno FROM emp;
2.CREATE VIEW
CREATE OR REPLACE VIEW dept_10
AS
SELECT emptno,ename,job,sal,deptno FROM emp WHERE deptno=10 ORDER BY emptno;
*******************************************************************************
Lesion 10 Creating Other Schema Objects
*******************************************************************************
CREATE SEQUENCE myseq
MAXVALUE 3
CYCLE
CACHE 2;
CREATE TABLE testseq(
next NUMBER ,
curr NUMBER
) ;
INSERT INTO testseq(next,curr) VALUES (myseq.nextval,myseq.currval) ;
INSERT INTO testseq(next,curr) VALUES (myseq.nextval,myseq.currval) ;
INSERT INTO testseq(next,curr) VALUES (myseq.nextval,myseq.currval) ;
INSERT INTO testseq(next,curr) VALUES (myseq.nextval,myseq.currval) ;
INSERT INTO testseq(next,curr) VALUES (myseq.nextval,myseq.currval) ;
SQL> select * from testseq;
NEXT CURR
---------- ----------
1 1
2 2
3 3
1 1
2 2
*******************************************************************************
USER_INDEXES 数据字典视图包含索引和它唯一的名字
USER_IND_COLUMNS 数据字典视图包含索引名、表名和列名
脚本示例:
SELECT ic.index_name,ic.column_name,ix.uniqueness
FROM user_indexes ix, user_ind_columns ic
WHERE ic.index_name = ix.index_name AND ic.table_name = 'EMPLOYEES';
*******************************************************************************
基于函数的索引
一个基于函数的索引,就是一个基于表达式的索引。
索引表达式用表中的列、常数、SQL函数和自定义函数来构建。
示例:
–创建函数索引
CREATE INDEX upper_last_name_idx ON employees (UPPER(last_name));
–使用函数索引
SELECT * FROM employees WHERE UPPER(last_name) = 'KING';
*******************************************************************************
Oracle SYNONYM:从字面上理解就是别名的意思。
CREATE public SYNONYM memp FOR employees;
GRANT select ON memp TO hr1;
如果要创建一个远程的数据库上的某张表的同义词,需要先创建一个Database Link(数据库连接)来扩展访问,然后创建数据库同义词:create synonym table_name for table_name@DB_Link;
*******************************************************************************
Lesion 11 Managing Objects with Data Dictionary Views
*******************************************************************************
Oracle数据字典是有表和视图组成,存储有关数据库结构信息的一些数据库对象。数据库字典描述了实际数据是如何组织的。比如一个表的创建者信息,创建时间信息,所属表空间信息,用户访问权限信息等。对它们可以象处理其他数据库表或视图一样进行查询,但不能进行任何修改。它们存放在SYSTEM表空间中,当用户在对数据库中的数据进行操作时遇到困难就可以访问数据字典来查看详细的信息。用户可以用SQL语句访问数据库数据字典。
Oracle数据库字典通常是在创建和安装数据库时被创建的,Oracle数据字典是Oracle数据库系统工作的基础,没有数据字典的支持,Oracle数据库系统就不能进行任何工作。数据字典中的表是不能直接被访问的,但是可以访问数据字典中的视图。
*******************************************************************************
Lesion 12 Controlling User Access
*******************************************************************************
系统权限(System Privilege):能够对数据库进行相应的某类操作。
可以用该SQL: select distinct privilege from dba_sys_privs;查看系统权限。
注:任何用户,都必须有CREATE SESSION权限,才可以连接到数据库。
对象权限(User Table Privilege):能够对数据库对象相应的某类操作。
注:对于TABLE包括:ALTER、DELETE、INDEX、INSERT、SELECT、UPDATE、REFERENCES、ON COMMIT REFRESH、QUERY REWRITE、DEBUG、FLASHBACK
*******************************************************************************
创建用户:创建用户DB_USER,密码为DB_USER_PW
create user DB_USER identified by DB_USER_PW
当用户建立后,会自动在Oracle数据库系统中生成属于该用户的Scheme (可以理解为所有属于该用户的表,视图....等对象的集合)
用户登录:
>SQL conn hr1/hr1
*******************************************************************************
1、使用GRANT语句向用户赋予系统权限:
GRANT system_privilege TO user_name [ WITH ADMIN OPTION ] ;
注:使用WITH ADMIN OPTION语句后,使用户可以将相同权限赋给其他用户。
GRANT create session, create table, create sequence, create view TO hr1;
2、使用REVOKE语句撤销系统权限:
REVOKE system_privilege FROM user_name ;
注:当删除A用户的权限时,通过A赋予B的权限不会消失。
*******************************************************************************
1、对象权限赋予语法:
GRANT object_privilege ON object_name TO username [ WITH GRANT OPTION ];
注:使用WITH GRANT OPTION语句后,使用户可以将相同权限赋给其他用户,与系统权限相同。
GRANT select , update , delete , insert on employees TO hr1;
2、对象权限撤销语法:
REVOKE object_privilege ON object_name FROM username;
注:当删除A用户的权限时,通过A赋予B的权限自动消失,与系统权限相反。
*******************************************************************************
本用户读取其他用户对象的权限:
select * from user_tab_privs;
本用户所拥有的系统权限:
select * from user_sys_privs;
*******************************************************************************
创建ROLE:
CREATE ROLE role_name
[ NOT IDENTIFIED | IDENTIFIED BY password]
注:IDENTIFIED 表示在修改该ROLE时是否需要提供密码
在创建 role 之后,使用 grant 和 revoke 手动设置 role 对应的权限
再使用 grant 和 revoke 将 role 赋给 user
注:可以将 role 赋给 role
CREATE ROLE r1;
GRANT select ON employees TO r1;
GRANT r1 TO hr1;
*******************************************************************************
show autocommit;--查看当前commit模式,是否自动提交
set autocommit on/off;设置自动提交开启/关闭















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









