







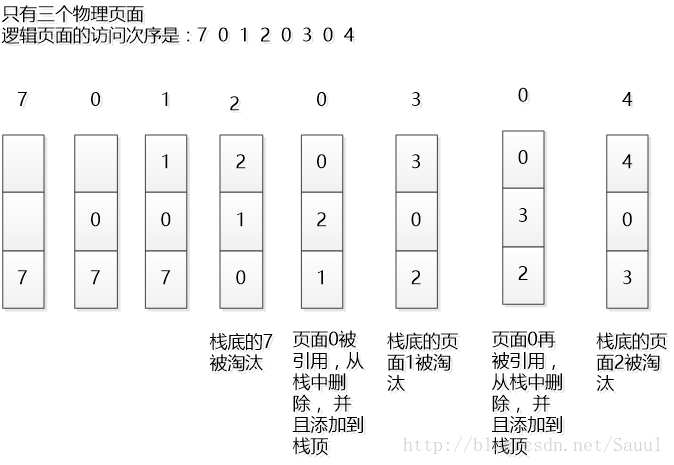
LRU全称是Least Recently Used,即最近最久未使用的意思。LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。是缓存中一种常见的机制。下图展示了逻辑页面缓存的访问情况
public class LRUPageFrame {
private static class Node {
Node prev;
Node next;
int pageNum;
Node() {
}
}
private int capacity;
private int currentSize;
private Node first;// 链表头
private Node last;// 链表尾
public LRUPageFrame(int capacity) {
this.currentSize = 0;
this.capacity = capacity;
}
/**
* 获取缓存中对象
*
* @param key
* @return
*/
public void access(int pageNum) {
Node node = find(pageNum);
//在该队列中存在, 则提到队列头
if (node != null) {
moveExistingNodeToHead(node);
} else{
node = new Node();
node.pageNum = pageNum;
// 缓存容器是否已经超过大小.
if (currentSize >= capacity) {
removeLast();
}
addNewNodetoHead(node);
}
}
private void addNewNodetoHead(Node node) {
if(isEmpty()){
node.prev = null;
node.next = null;
first = node;
last = node;
} else{
node.prev = null;
node.next = first;
first.prev = node;
first = node;
}
this.currentSize ++;
}
private Node find(int data){
Node node = first;
while(node != null){
if(node.pageNum == data){
return node;
}
node = node.next;
}
return null;
}
/**
* 删除链表尾部节点 表示 删除最少使用的缓存对象
*/
private void removeLast() {
Node prev = last.prev;
prev.next = null;
last.prev = null;
last = prev;
this.currentSize --;
}
/**
* 移动到链表头,表示这个节点是最新使用过的
*
* @param node
*/
private void moveExistingNodeToHead(Node node) {
if (node == first) {
return;
}
else if(node == last){
//当前节点是链表尾, 需要放到链表头
Node prevNode = node.prev;
prevNode.next = null;
last.prev = null;
last = prevNode;
} else{
//node 在链表的中间, 把node 的前后节点连接起来
Node prevNode = node.prev;
prevNode.next = node.next;
Node nextNode = node.next;
nextNode.prev = prevNode;
}
node.prev = null;
node.next = first;
first.prev = node;
first = node;
}
private boolean isEmpty(){
return (first == null) && (last == null);
}
}














 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









