






web课 Node.js 爬虫项目实验(这是一篇自我学习顺便完成作业的文章)
写在开头:说实话我是真的没有想到我们web编程课会在上来,还没还有讲Javascript的基本语法之前,老师就给我们讲解了一个简单的爬虫例子,并在期中要求我们以此为例,完成期中的爬虫项目。作为一个大一新生(还算是新生吧?至少在写代码完成项目上还是一个新生),看到这样的一个项目作业我还时挺害怕的(特别是看着ddl不断靠近,感觉老师就是想要我的命啊)。

但是该做的事情还是要做的。所以这篇文章只属于自己本人学习总结和完成作业,过于专业的知识及问题本人也未必知晓,如果文章内容有误,还待本人慢慢丰富自己的知识后在慢慢改正和增添。
另外如果老师检查作业不想看我对课上的示例的分析的话请老师直接从第三部分开始浏览,那里才是我自己写的爬取网易新闻的爬虫。
话不多说,先上问题和题目要求:
新闻爬虫及爬取结果的查询网站
核心需求:
1、选取3-5个代表性的新闻网站(比如新浪新闻、网易新闻等,或者某个垂直领域权威性的网站比如经济领域的雪球财经、东方财富等,或者体育领域的腾讯体育、虎扑体育等等)建立爬虫,针对不同网站的新闻页面进行分析,爬取出编码、标题、作者、时间、关键词、摘要、内容、来源等结构化信息,存储在数据库中。
2、建立网站提供对爬取内容的分项全文搜索,给出所查关键词的时间热度分析。
技术要求:
1、必须采用Node.JS实现网络爬虫
2、必须采用Node.JS实现查询网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
虽然要求在这,但是通过和老师的交涉,我知道了目前来讲,对于爬取文件的可视化和前端要求老师暂时要求不高,那么我也就按照自己的节奏慢慢地摸索这向前吧。
对于选题,由于老师给的例子就是中新网的爬虫,估计大对数人也都会就按照例子直接用中新网来进行工作,那么我就稍微来点不一样的,我的选题是“针对新浪新闻网的爬虫项目”。
俗话说的好“磨刀不误砍柴功”,要想更好的完成这次作业,那么就先从之前的例子入手,先做分析在开始我们的项目。
I.示例分析
1.定义域名

首先开头我们先定义我们要爬取的网站的名称(主要用于后面保存内容时的文件命名)、我们的编码标准以及爬取网站的域名。
2.定义网页元素和内容

这一部分时我们对于网页中具体内容的读取方式,语法基于jQuery的选择器。例如:

如上图,我们发现在中新网的首页的源代码文件中某一个新闻链接的连接口对应的标签元素是<a></a>,所以我们才有第一行的选择出标签为a的元素;

对于具体的某一新闻的内部的keyword,description,在源代码有这样的定义<meta name=“名称” content=“内容”>。
那么对于选择器,我们,就有定义 $('meta[name=\"keywords\"]').eq(0).attr(\"content\"),其作用,就是读取到keyword中的内容,例如途中的是“中方,生物多样性公约,达峰,生态文明,和谐共生”。

title、pubtime_baidu、editor_baidu、source_baidu也有如上定义<span id="...">........</span>,由jQuery选择器的语法(具体是什么我也还不是很清楚)有var date_format = "$('#pubtime_baidu').text()"得到
同理正文部分。取出txt文字。(注意这里id用”#“,class用”.“)

最后一句用于正则表达式,最后判断是否是我们要爬取的链接。
分析新闻的链接,我们不难看出,对于新闻的链接,他的链接名为基本为“www.chinanews.com/gn/2021(4个数字表示年)/40(2个数字表示月)-(短横)23(2个数字表示日)/9461654(7个数字表示编号).shtml”。

即“/4个数/2个数-2个数/7个数.shtml/”,故得表达式"/\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/",其中第一个斜杠表示表达式开始,\/中第一个\为转义字符\/表示一个\d{4}表示4个数字。
3.引入完成爬虫需要的库

注意这里的fs,requset,cheerio,iconv-lite,date-utils库还需要额外安装,故需要命令:npm install fs、npm install cheerio等。
fs是filesystem,我们引入主要是用于最后保存爬取内容所需函数;
request库用于获取网页的html模块库,举一个简单的例子:request(options,callback),这里的第一个参数可以是url(域名),也可以是一个options对象,但必须包含url;第二个参数是一个回调函数。

这是一个可以爬取百度首页的html的简单的request函数实现。request(url,function(error,resopnse,body)),不能成功访问,那么会返回error;成功访问到了,则会返回respond,同时将html存到body中。
运行得到:

当然这里知识缩略图,但的确是百度首页的源码。
cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。
iconv-lite实现代码编译转换模块,项目中的主要的功能是将无论什么编译标准的代码转化为标准的utf-8(其实现在的网站基本都是统一的utf-8,这个的作用我个人感觉不是很大)。
date-utils是一个日期工具类,方便我们对爬取时间的操作。
4.为爬虫创建浏览器请求头(防止爬虫被拦下来,拒接访问)

这里的话具体的原理和方法我目前还不太懂,但我们如上则是让要爬取的网页以为爬虫是从safari浏览器对网页发起请求。
类似的有(p.s:这些是我抄来的)
var headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}
5.读取种子页面的函数构造

一开始只看上面一段的时候,说实话,我是完全看不懂的,为什么又来一个requset函数?那么myReques又是什么?callback又是什么?ʕ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ•̫͡•ʕ•̫͡•ʔ•̫͡•ʕ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ
后面上课上完回调函数后我终于明白了,这和下面这段代码是分不开的。

简单的来讲,上一张图讲的是我们申明了一个名为requset的函数(到底为什么要弄一个这么容易混淆的名字啊?),而后一张图是对这段requset函数的具体内容进行详细描述。
直接讲这么长的函数毕竟还是会有点懵逼,那么我们先来一个简单一点的例子:
还记得前面讲requset库提到的爬取百度首页源码的代码吗?我们做一个简单的改造

为了防止该混了,我特别的吧函数命名为re(),你别看这一小段短,它已经包含上面两张图面中的代码的主体部分。
首先,我们申明一个re()函数,这个函数有两个参数,url和回调callback——什么?不知道什么是回调函数?这种简单的东西我就不讲了(主要还是不太懂)——然后下面是re()函数中含有myRequest,即引入的requset中默认get,这一部分便是re的回调函数,可以看到和前面怕百度html的一模你一样,所以它的结果也和上面一样。
那么再具体分析这段代码定义的requset,requset中有参数url和回调函数callback,然后requset函数中包含myRequsey的引入以及option的定义,options包含url,encoding,headers和times,这些是要传入myRequest函数中作为参数的值。简而言之,这里的requset函数函数就是我们只用传入种子的url然后就定义出optionns并将此作为参数传入requset库映入的myRequest函数。
然后对于具体实现,首先传入种子页面url,然后开始callback函数的内容白编写。
首先讲读到的存入body中的html转换编码,利用iconv-lite中的函数decode()转换编码,并保存为变量html。
然后将html,并且是转换编码后的用cheerio模块库中load函数传入变量$开始解析,即开始实现对此时html代码的分析筛选。

然后把前面定义的查找新闻页面表达式seedURL_format作为参数放入eval函数,读取到所有含有标签<a>的html语句并存入变量seedurl_news中。

接着each函数进行历遍,接下来就是对看这些链接是否满足我们一开始定义的正则表达式,若是就打开然后对内容爬取。
再观察标签为‘a'的元素部分![]() 前面是herf为名称开头接下来才是链接。
前面是herf为名称开头接下来才是链接。
一般的链接有http:开头,也有https:开头,然后对于标签a中名称为href的元素,如果它有这样的开头我们就直接取出就行;没有的话,就加上,这样域名才完整,才能通过爬虫打开。故有如下语句:

对于我们构成的链接,接下来就看它满不满足最开始我们定义的正则表达式,满足了就开始我们正式的爬取操作了。newsGet()函数打开正确的链接并开始爬取。
6.新闻内容的处理(这才是重头戏)
首先newsGet()函数开始相同,先打开来链接,进行读取、转码、以及写入cheerio开始解析。

毕竟爬下来的东西是要现有变量承接,然后存到本地文件,所以还要先定义变量。


注意这里的赋值都是直接用来开头定义的那几个表达式。这一部分就比较简单了只是当一些要爬取的东西没有时注意要不要用其他来替代而已。以及内部元素需要的某些替代规则。
最后只需要将这些放到本地文件就行。

至此代码完成,示例分析完成,先来看一下效果


ok,还算不错,示例完成。接下来开始我的爬虫项目。
不过这里我想再加一些自己的东西:
因为老师的爬虫爬下来的东西直接就以字符串的形式加到了txt文件中,看上去就特别乱,所以我们最后写入部分稍加修改改成这样
fs.writeFileSync(filename, "url:"+fetch.url+"\n"+"title:"+fetch.title+"\n"+"content:"+fetch.content+"\n"+"publish_date:"+fetch.publish_date+"\n"+"source_name:"+fetch.source_name+"\n"+"crawltime"+fetch.crawltime+"\n");然后再不同内容后有了换行和名称,看上去会好很多,大致效果如下

但其实也还有其他方法,按照老师的,爬位json文件,然后安装json tool,打开时运行Ctrl+alt+M
就可以得到

II.本人项目完成
在我的项目中我想要把爬下的存入mysql数据库,并进行简单的网页关键词查询,所以还需要有数据库构建和网页搭建。
首先搭建mysql数据库,需要如下代码:命名为mysql.js(与爬虫放在统一文件下)。(这一部分我是真的还不会,老师倒是说以后慢慢学,唉...那也只能先照搬了)

另外MySQL数据库的构建主要就是MySQL的使用方法,网上都有教程的,所以这里也不再赘述。
爬虫代码方面变化不大(其实我就是再依葫芦画瓢),但是需要加入将内容存到mysql数据库中所以需要
![]()
其他的变化都不大,本来这里想糊过去,直接用原来示例中的来糊过去——但还是算了。
中间部分不变。
然后需要改进的判断符合正则表达式后进行新闻页面的读取,改进为:
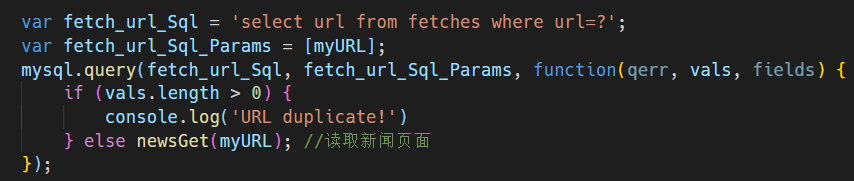
然后最后要改是爬到的新闻的保存工作:

至此完毕。唉?你说我为什么之极端都不写分析了,不写函数用法了?那当然是应为我不会啊后面慢慢学吧(老师也是这样说的)。
代码总结为:
//开头先引入库
var fs = require('fs');
var myRequest = require('request');
var myCheerio = require('cheerio');
var myIconv = require('iconv-lite');
require('date-utils');
var mysql = require('./mysql.js');
//定义爬取的种子网站信息
var source_name = "中国新闻网";
var myEncoding = "utf-8";
var seedURL = 'http://www.chinanews.com/';
//种子网站以及新闻网页内容选择器和网站链接正则表达式
var seedURL_format = "$('a')";
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
var title_format = "$('title').text()";
var date_format = "$('#pubtime_baidu').text()";
var author_format = "$('#editor_baidu').text()";
var content_format = "$('.left_zw').text()";
var desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
var source_format = "$('#source_baidu').text()";
var url_reg = /\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/;
//浏览器请求头
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 10000 //
}
myRequest(options, callback)
};
//读取种子页面
request(seedURL, function(err, res, body) {
//用iconv转换编码
var html = myIconv.decode(body, myEncoding);
//准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
var seedurl_news;
try {
seedurl_news = eval(seedURL_format);
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(i, e) { //遍历种子页面里所有的a链接
var myURL = "";
try {
//得到具体新闻url
var href = "";
href = $(e).attr("href");
if (href == undefined) return;
if (href.toLowerCase().indexOf('http://') >= 0 || href.toLowerCase().indexOf('https://')>=0) myURL = href;
else if (href.startsWith('//')) myURL = 'http:' + href;
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href;
} catch (e) { console.log('识别种子页面中的新闻链接出错:' + e) }
if (!url_reg.test(myURL)) return;
var fetch_url_Sql = 'select url from fetches where url=?';
var fetch_url_Sql_Params = [myURL];
mysql.query(fetch_url_Sql, fetch_url_Sql_Params, function(qerr, vals, fields) {
if (vals.length > 0) {
console.log('URL duplicate!')
} else newsGet(myURL); //读取新闻页面
});
});
});
//读取新闻页面
function newsGet(myURL) {
request(myURL, function(err, res, body) {
var html_news = myIconv.decode(body, myEncoding);
var $ = myCheerio.load(html_news, { decodeEntities: true });
myhtml = html_news;
console.log("转码读取成功:" + myURL);
var fetch = {};
fetch.title = "";
fetch.content = "";
fetch.publish_date = (new Date()).toFormat("YYYY-MM-DD");
//fetch.html = myhtml;
fetch.url = myURL;
fetch.source_name = source_name;
fetch.source_encoding = myEncoding;
fetch.crawltime = new Date();
if (keywords_format == "") fetch.keywords = source_name; // eval(keywords_format); //没有关键词就用sourcename
else fetch.keywords = eval(keywords_format);
if (title_format == "") fetch.title = ""
else fetch.title = eval(title_format); //标题
if (date_format != "") fetch.publish_date = eval(date_format); //刊登日期
console.log('date: ' + fetch.publish_date);
fetch.publish_date = regExp.exec(fetch.publish_date)[0];
fetch.publish_date = fetch.publish_date.replace('年', '-')
fetch.publish_date = fetch.publish_date.replace('月', '-')
fetch.publish_date = fetch.publish_date.replace('日', '')
fetch.publish_date = new Date(fetch.publish_date).toFormat("YYYY-MM-DD");
if (author_format == "") fetch.author = source_name; //eval(author_format); //作者
else fetch.author = eval(author_format);
if (content_format == "") fetch.content = "";
else fetch.content = eval(content_format).replace("\r\n" + fetch.author, ""); //内容,是否要去掉作者信息自行决定
if (source_format == "") fetch.source = fetch.source_name;
else fetch.source = eval(source_format).replace("\r\n", ""); //来源
if (desc_format == "") fetch.desc = fetch.title;
else fetch.desc = eval(desc_format).replace("\r\n", ""); //摘要
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +
'keywords,author,publish_date,crawltime,content) VALUES(?,?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,
fetch.title, fetch.keywords, fetch.author, fetch.publish_date,
fetch.crawltime.toFormat("YYYY-MM-DD HH24:MI:SS"), fetch.content
];
//执行sql,数据库中fetch表里的url属性是unique的,不会把重复的url内容写入数据库
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
}); //mysql写入
});
}
结果为

然后数据库方面,利用mysql workbench得到简单的可视化

这还不够,我们稍微添加一点东西。其实就是非常非常简单的前端后端联系,应为学的还不多,就先做个简单的例子。
我们实现用express构建网站访问mysql,有如下代码(这一部分就是把老师上课讲的发个我们的代码而已)命名为:search.js

搭建网页,命名为search.html:

这俩和爬虫放到统一目录(其实不放也可以)
最后使用时先运行search.js然后运行运行search.html.
不过注意,VScode不能运行html,不过我有装插件Live Server,所以可以直接再VScode打开,不然的话就只能通过打开http://127.0.0.1:8080/search.html来打开。
打开后如图:



搜索关键字新冠得结果如上。
III.应老师要求爬取中新网之外其他网站(以网易新闻为例)
要爬取网易新闻那么和上面一样先定义引入的模块和种子网页
// 首先引入需要的模块库
var myRequest=require('request')
var myCheerio=require('cheerio')
var myIconv=require('iconv-lite')
require('date-utils');
var mysql = require('./mysql.js');
var fs = require('fs');
// 引入种子网页链接
var source_name="网易新闻网";
var myEncoding = "utf-8";
var seedURL = 'https://news.163.com/';首先观察网易新闻的首页如下

我们可以简单的看出新闻的链接再种子页面中还是存在于<a>标签中同样实在href中,但是相应的链接的正则表达式与中新网大不相同,也复杂了一点,分析下面几个:
https://www.163.com/news/article/G8HKU84M000189FH.html
https://www.163.com/news/article/G8HKSTGH000189FH.html
https://www.163.com/dy/article/G8GK31NP0514R9OJ.html
相同分的组成都是/article/长度为16的数字字母的组合.html
所以我们可以得到新的正则表达式:
var url_reg=/\/article\/(\w{16}).html/
然后对于新闻内部有分析


我们就爬取keyword、description、author、正文部分进行爬取,所以我们有选择器如下:
// 定义选择器
var seedURL_format = "$('a')";// 选择出子链接所在的标签,此处<a>
var title_format = "$('title').text()";
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
var desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
var author_format = "$('meta[name=\"author\"]').eq(0).attr(\"content\")";
var content_format = "$('.post_body').text()";
var url_reg=/\/article\/(\w{16}).html/接下来就是浏览器请求头
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}接着对requset读取种子页面函数进行定义
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 10000 //
}
myRequest(options, callback)
};
//读取种子页面
request(seedURL, function(err, res, body) {
//body用iconv转换编码
var html = myIconv.decode(body, myEncoding);
//html存入cheerio准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
var seedurl_news;
try {
seedurl_news = eval(seedURL_format);
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(i, e) { //遍历种子页面里所有的a链接
var myURL = "";
try {
//得到具体新闻url
var href = "";
href = $(e).attr("href");
if (href == undefined) return;
if (href.toLowerCase().indexOf('http://') >= 0 || href.toLowerCase().indexOf('https://')>=0) myURL = href; //http://开头的//也要主力遇到网站是http是开头的
else if (href.startsWith('//')) myURL = 'http:' + href; 开头的
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href; //其他
} catch (e) { console.log('识别种子页面中的新闻链接出错:' + e) }
if (!url_reg.test(myURL)) return; //检验是否符合新闻url的正则表达式
// 这里是是我们要存入mysql数据库,所以查看数据库有没有爬过爬过就不用再爬
var fetch_url_Sql = 'select url from fetches where url=?';
var fetch_url_Sql_Params = [myURL];
mysql.query(fetch_url_Sql, fetch_url_Sql_Params, function(qerr, vals, fields) {
if (vals.length > 0) {
console.log('URL duplicate!')
} else newsGet(myURL); //读取新闻页面
});
});
});对于符合正则表达式的链接,我们开对其进行爬取newsGet()
function newsGet(myURL) { //读取新闻页面
request(myURL, function(err, res, body) { //读取新闻页面
var html_news = myIconv.decode(body, myEncoding); //用iconv转换编码
//准备用cheerio解析html_news
var $ = myCheerio.load(html_news, { decodeEntities: true });
myhtml = html_news;
console.log("转码读取成功:" + myURL);//这里还能作为一个反馈让我们看到我们爬虫在进行工作
//动态执行format字符串,构建json对象准备写入文件或数据库
var fetch = {};
fetch.title = ""; //标题
fetch.content = ""; //正文
fetch.url = myURL; //网址
fetch.source_name = source_name; //来源,即网易新闻网
fetch.author = author_format; //作者
fetch.source_encoding = myEncoding; //编码
fetch.crawltime = new Date(); //爬取时间
if (keywords_format == "") fetch.keywords = source_name; // eval(keywords_format); //没有关键词就用sourcename
else fetch.keywords = eval(keywords_format);
if (title_format == "") fetch.title = ""
else fetch.title = eval(title_format); //标题
if (author_format == "") fetch.author = source_name; //eval(author_format); //作者
else fetch.author = eval(author_format);
if (content_format == "") fetch.content = "";
else fetch.content = eval(content_format).replace("\r\n" + fetch.author, ""); //内容,是否要去掉作者信息自行决定
if (desc_format == "") fetch.desc = fetch.title;
else fetch.desc = eval(desc_format).replace("\r\n", ""); //摘要
var filename ="F:\jscrawler"+ source_name + "_" + (new Date()).toFormat("YYYY-MM-DD") +
"_" + myURL.substr(myURL.lastIndexOf('/') + 1) + ".json";
存储json
fs.writeFileSync(filename, JSON.stringify(fetch));
// 不仅要把爬到的东西存到本地文件还要存到数据库,所以有如下
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +
'keywords,author,publish_date,crawltime,content) VALUES(?,?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,
fetch.title, fetch.keywords, fetch.author,
fetch.crawltime.toFormat("YYYY-MM-DD HH24:MI:SS"), fetch.content
];
//执行sql,数据库中fetch表里的url属性是unique的,不会把重复的url内容写入数据库
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
}); //mysql写入
});
}其中值得注意的是我们需要把爬到的数据存入数据库所以有query。
然后我们需要搭建数据库,因为数据库中存入的东西与老师不太一样,所以需要改进。


这里注意搭建数据库是数据库中的东西与你存入的信息要一致。当然mysql.js也要修改
var mysql = require("mysql");
var pool = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'crawl2'
});
var query = function(sql, sqlparam, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, sqlparam, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
var query_noparam = function(sql, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
exports.query = query;
exports.query_noparam = query_noparam;最后运行程序
如图


效果如图。
爬虫阶段到此结束。
对于前端网页的搭建和运用我也只能是依葫芦画瓢。
我们需要利用express脚手架来创建一个网页引擎。在我们代码文件位置创建search_site文件。但是一开始我的是有问题,会显示“express不是内部或外部命令.......”,然后在网上查阅不少资料后发现是自己的express文件少了express-generator文件,需要单独安装。
然后有命令如下


这里需要注意,应为搜索引擎需要与数据库有交互,所以需要把他放入search_site文件夹下(其实不放也行只是这样的话后面我们引入mysql模块是注意路径就行)
接着打开文件夹search_site运行如下命令npm install mysql –save安装需要的所有modules。

然后打开search_site/routes/index.js(默认已经创建的),这里面是为了实现关键字检索函数
var express = require('express');
var router = express.Router();
var mysql = require('../mysql.js');
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/process_get', function(request, response) {
//sql字符串和参数
var fetchSql = "select url,source_name,title,author,crawltime " +
"from fetches where title like '%" + request.query.title + "%'";
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
response.write(JSON.stringify(result));
response.end();
});
});
module.exports = router;
接着在search_site/public/位置下创建网页界面
<!DOCTYPE html>
<html>
<header>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
<meta charset="utf-8">
<!-- 这里meta的功能在于确定网页编码为utf-8 -->
<meta name="viewport" content="width=device-width initial-scale=1.0">
<!-- 这里的meta功能在于网页的终端自适应 -->
</header>
<body>
<form>
<br> 标题:<input type="text" name="title_text">
<input class="form-submit" type="button" value="查询">
</form>
<div class="cardLayout" style="margin: 10px 0px">
<table width="100%" id="record2"></table>
</div>
<script>
$(document).ready(function() {
$("input:button").click(function() {
$.get('/process_get?title=' + $("input:text").val(), function(data) {
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td><td>crawltime</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
Object.values(list).forEach(element => {
table += (element + '</td><td>');
});
$("#record2").append(table + '</td></tr>');
}
});
});
});
</script>
</body>
</html>最后我们的工作就完成啦!
然后让我们来康康是什么结果:先运行bin/www文件,这里就相当于开始和网页有有连接,此时打开网页和搜索关键字在后端都会有响应,基本如下


达到老师要求的结果。终于作业完成了!!!!!!
总结:综上所述,其实每个网站爬虫的不同点就是在于正则表达式和爬取内容的选择器的构建不同,所以学会了一个网站的爬取,其他改改就行,只要慢慢的分析链接的正则表达式,其他很多网站都可以爬取。
例如换一下人民网,就有var url_reg = /\/(\d{4})\/(\d{4})\/(\w{5})-(\d{8}).html/
得到

至此,本篇文章结束,作业终于做完了ʕ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ•̫͡•ʕ•̫͡•ʔ•̫͡•ʕ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ•̫͡•ʕ•̫͡•ʔ•̫͡•ʔ
后记
本篇文章只是自己学习期中作业的记录,文章内容可能有误,毕竟本人才疏学浅,学的东西还不多,但本人也在努力抓紧自己的学习。如有问题,欢迎指正。
以上
目录
Node.js 爬虫项目实验(这是一篇自我学习顺便完成作业的文章)
III.应老师要求爬取中新网之外其他网站(以网易新闻为例)















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









