







总复习
前言
里面记录的知识点基本在考试范围,考柿不考的知识点有很多没有写。面向考试。
建议大家配合习题食用。
标⭐的确实是考过的,但是标得不是很全。然后⭐越多,表示我认为它还是比较重要的。

(一)绪论
1. 计算机的发展
现代计算机的理论基础:布尔代数、物质基础:双稳态触发器。
1946年,美国,ENIAC,电子数字积分和计算机
1946年6月,冯·诺伊曼提出以二进制,程序存储和程序控制为核心的思想,奠定了当代电子数字计算机体系结构的基础。
- 1946-1954年,第1代,电子管计算机,ENIAC、IBM 701
- 1955-1964年,第2代,晶体管计算机,IBM 7030、Univac LARC
- 1965-1974年,第3代,集成电路计算机,IBM 360、370、DEC PDP-8
- 1975-1990年,第4代,超大规模集成电路计算机,IBM 3090、VAX 9000、PC机、苹果机
- 1991-,第5代,多核处理器(4核和8核)
2. ⭐⭐计算机的基本组成

这是去年的考题!!!
冯·诺伊曼机的硬件固定,不同的运算功能依靠预先放在存储器中的程序实现,这是存储程序控制的基本原理,也是区别其他运算工具的关键。

计算机的软件:
- 计算机语言:机器语言、汇编语言、高级语言
- 软件分类:系统软件、应用软件、中间件
3. 计算机的层次结构
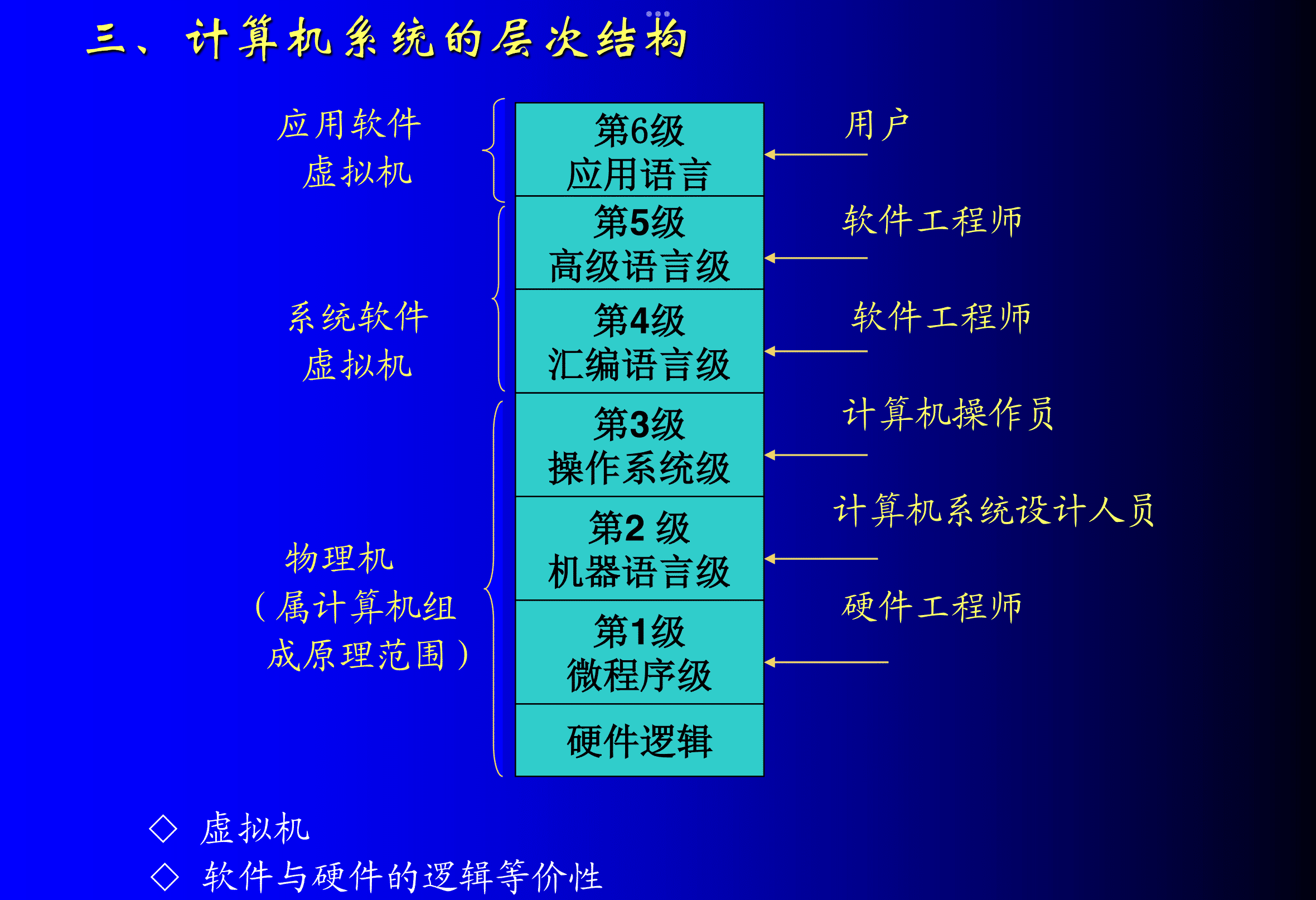
4. 计算机的分类
-
按照规模和功能分类:
巨型机、大型机、中型机、小型机、微机、单片机
-
按用途分类:
通用机(如:PC机)、专用机(如:嵌入式计算机)
-
按信息处理的特性分类:(FLYNN)费林分类法
- 单指令流单数据流计算机(SISD)
- 单指令流多数据流计算机(SIMD)
- 多指令流单数据流计算机(MISD)
- 多指令流多数据流计算机(MIMD)
Flynn分类法:按照计算机在执行程序的过程中信息流的特征进行分类的。
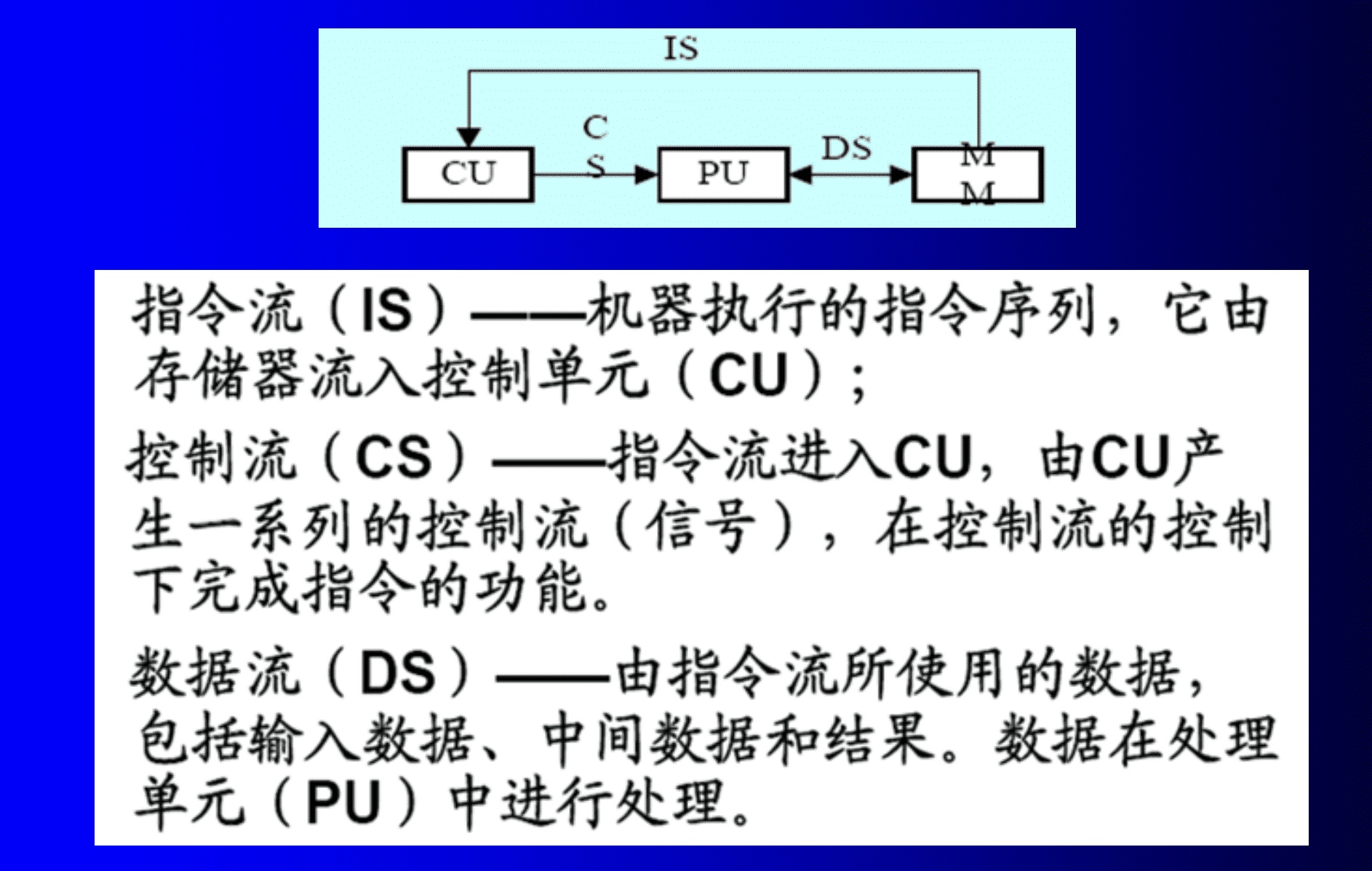
5. 计算机的性能描述
(个人认为可能概率会出题)
- MIPS:每秒钟执行指令的百万条数
- MFLOPS:每秒钟执行浮点数的百万次操作的数量
- CPI:每条指令执行所用的时钟数
- N:每条指令执行所用的时钟数
- f C L K f_{CLK} fCLK:时钟频率


(二)计算机中的数据表示


1. 不同编码的比较
- 真值为 + :原码、补码、反码的表示形式均相同。
- 真值为 - :原码、补码、反码的表示形式不同。
- 特殊的移码: 0 表示真值是负数; 1 表示真值是正数。
0有唯一的编码:补码、移码。
原码:1000 0000 | 0000 0000
反码:1111 1111 | 0000 0000
符号位用0表示正、用1表示负:原码、反码、补码
移码:1表示正、0表示负
满足真值大则码值大:移码
最高位符号位1为负数(真值小码值小):原码、反码、补码
存在负值的真值越大码值越小:原码
【-1】补=【1000 0001】补=【1111 1111】可见是:最大的负值、最大的码值。
反码 = 补码 - 1、移码 = 补码最高符号位取反 因此均不是。
负数的码值大于正数的码值:原码、反码、补码
原理是:负数的码值最高位符号位为1
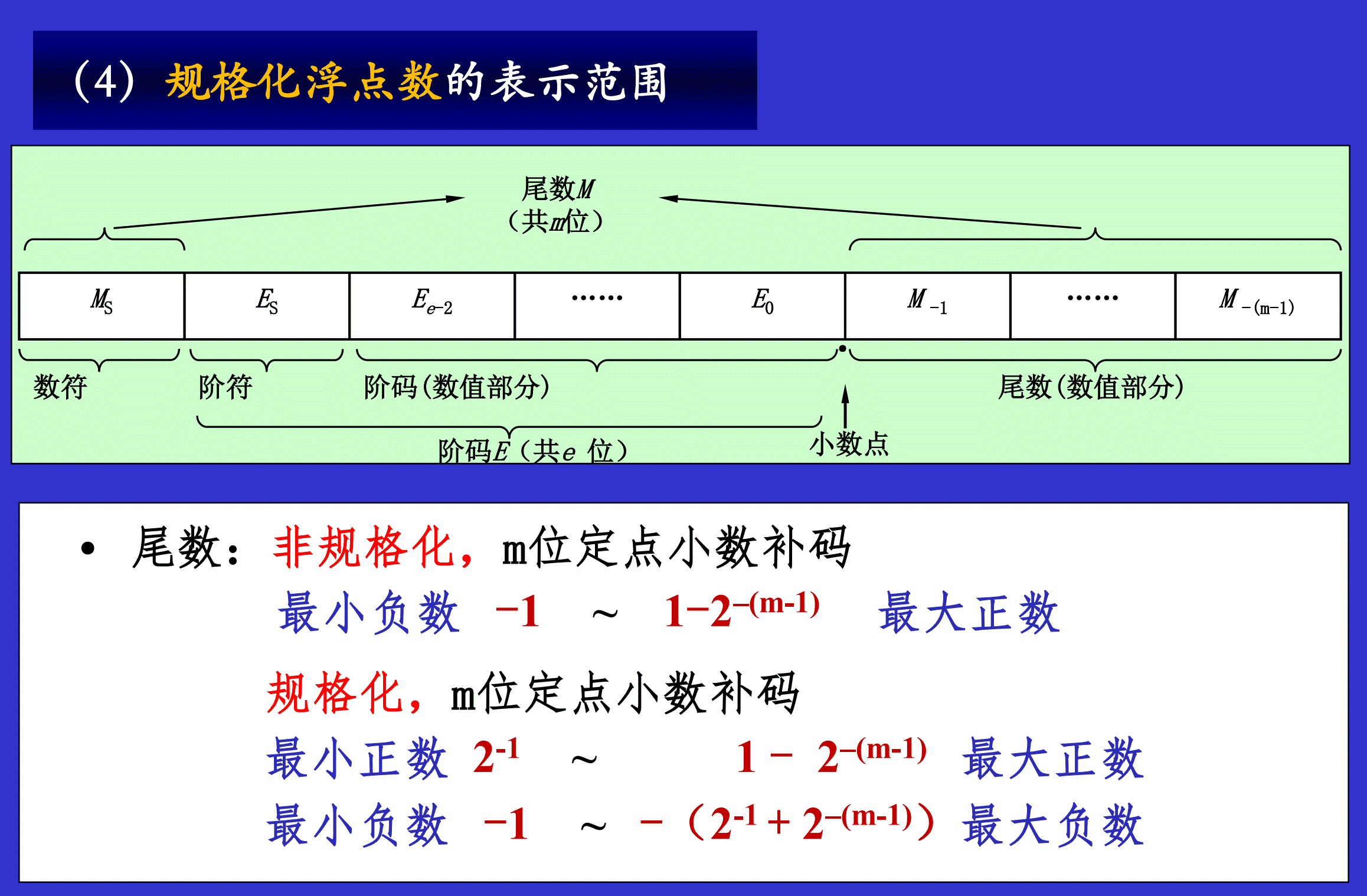
2. ⭐⭐浮点数
规格化指的是尾数的绝对值限定在$\frac{1}{2} ~ 1$之间。
若 M ≥ 0 M\ge0 M≥0: M = 0.1 X X . . . X M=0.1XX...X M=0.1XX...X是规格化数。
若
M
<
0
M\lt0
M<0:由于
[
−
1
2
]
补
=
1.1000...0
[-\frac{1}2]_{补}=1.1000...0
[−21]补=1.1000...0、
[
−
1
]
补
=
1.000...0
[-1]_{补}=1.000...0
[−1]补=1.000...0。为了使计算机判断方便,一般不把
[
−
1
2
]
[-\frac{1}2]
[−21]列为规格化的数,而把
[
−
1
]
[-1]
[−1]列为规格化的数。
M
=
1.0
X
X
X
.
.
.
X
M=1.0XXX...X
M=1.0XXX...X时,是规格化数。

貌似左规和右规都是在采用了双符号位,也就是变形补码后产生的。
左规:结果的尾数为 00.0 X X X . . . X 00.0XXX...X 00.0XXX...X或 11.1 X X X . . . X 11.1XXX...X 11.1XXX...X的形式时,需将尾数左移1位,阶码 -1,直到尾数为规格化形式为止。
右规:当浮点运算结果的尾数出现 01. X X X . . . X 01.XXX...X 01.XXX...X或 10. X X X . . . X 10.XXX...X 10.XXX...X的形式时,并不一定溢出,将尾数右移1位,阶码 +1,然后判断阶码是否溢出。


2.1 IEEE754

单精度格式:1+8+23(符号+阶码+尾数)
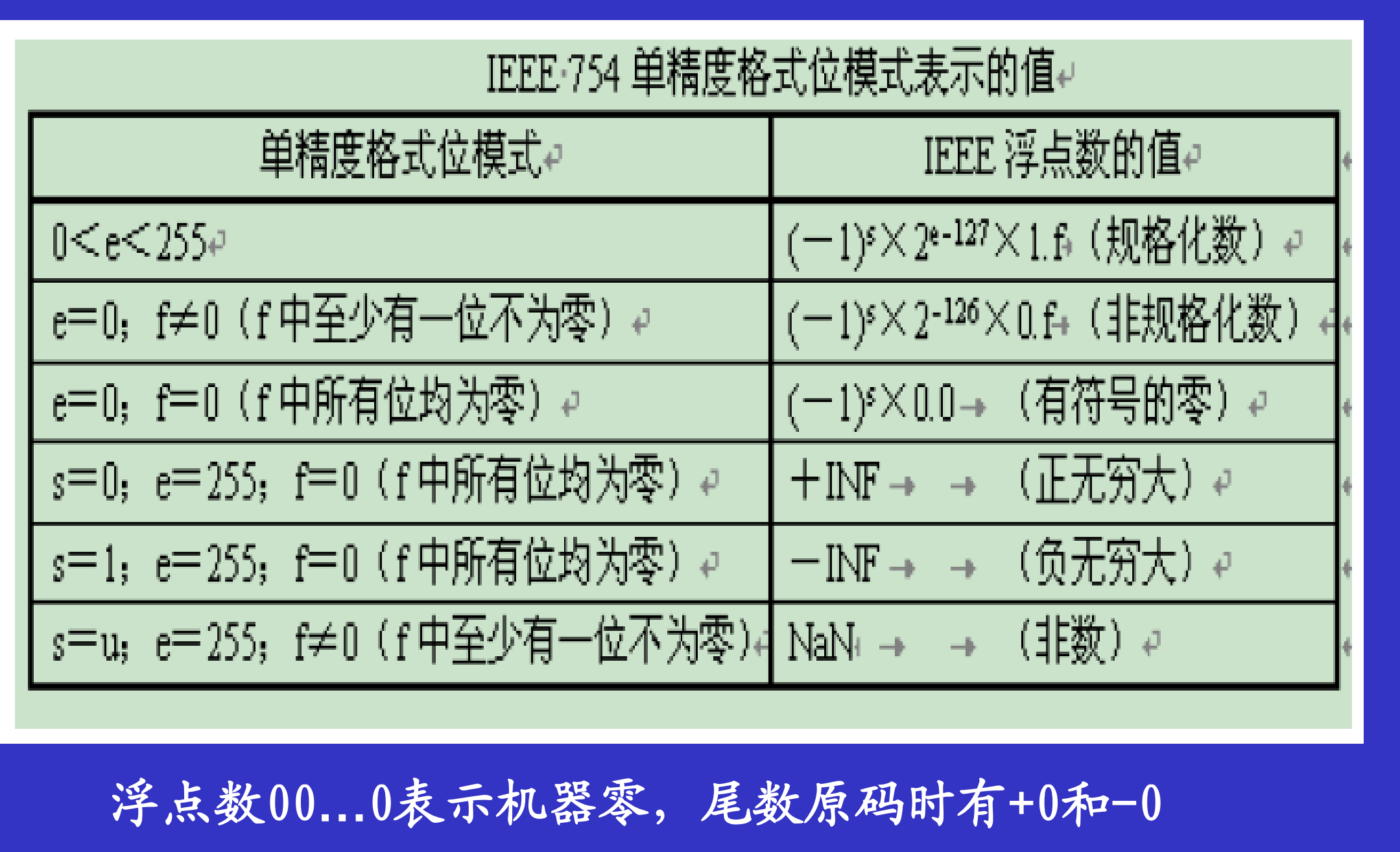
更多的重点还是放在单精度的浮点数上,至于双精度格式(1+11+52)只是被提了一下。
(三)运算方法和运算器
运算器用于数值运算及加工处理数据。
运算器的结构取决于:指令系统、数据的表示方法、运算方法以及所选用的硬件。
它由CPU中的ALU、GR(通用寄存器)等部件组成。
1. 定点数运算
1.1 加减
特别声明的是:求补运算
(主要用于 [ X ] 补 ↔ [ − X ] 补 [X]_{补}\leftrightarrow[-X]_{补} [X]补↔[−X]补 这种情况,对于符号位和数值位均按位取反,末位+1)
1.1.1 溢出判断
==只有当两个同符号的数相加(or 相异符号数相减),运算结果才可能溢出。==异号相加,永远不会产生溢出。
发生溢出时,运算结果肯定是错误的。防止溢出发生的最简单有效的方法即:增加补码的二进制编码长度。
我还想的是采用双符号位呢…不过双符号位并不能防止溢出,而是判断是否溢出。果然。
① 双符号位判决法(最常用)
补码采用两位表示符号,即00(+)和11(-)。
一旦发生溢出,则两个符号位就一定不一致。
- 出现01,结果 > +1
- 出现10,结果 < -1
所以01是上溢、10是下溢吗?
② 进位判决法
类似于双符号位,【最高数值位向符号位的进位】 ⊕ \oplus ⊕【符号位的进位】
1.1.2 移码加减 [ X ] 移 ± [ Y ] 移 ≠ [ X ± Y ] 移 [X]_{移}\pm[Y]_{移}\ne[X\pm Y]_{移} [X]移±[Y]移=[X±Y]移

1.2 ⭐⭐乘
1.2.1 原码一位乘

对于原码二位乘,只需了解(我认为意思是不会考)。
1.2.2 补码一位乘(Booth法)

\\\\
1.3 ⭐⭐除
1.3.1 原码一位除
① 恢复余数法

② 加减交替法
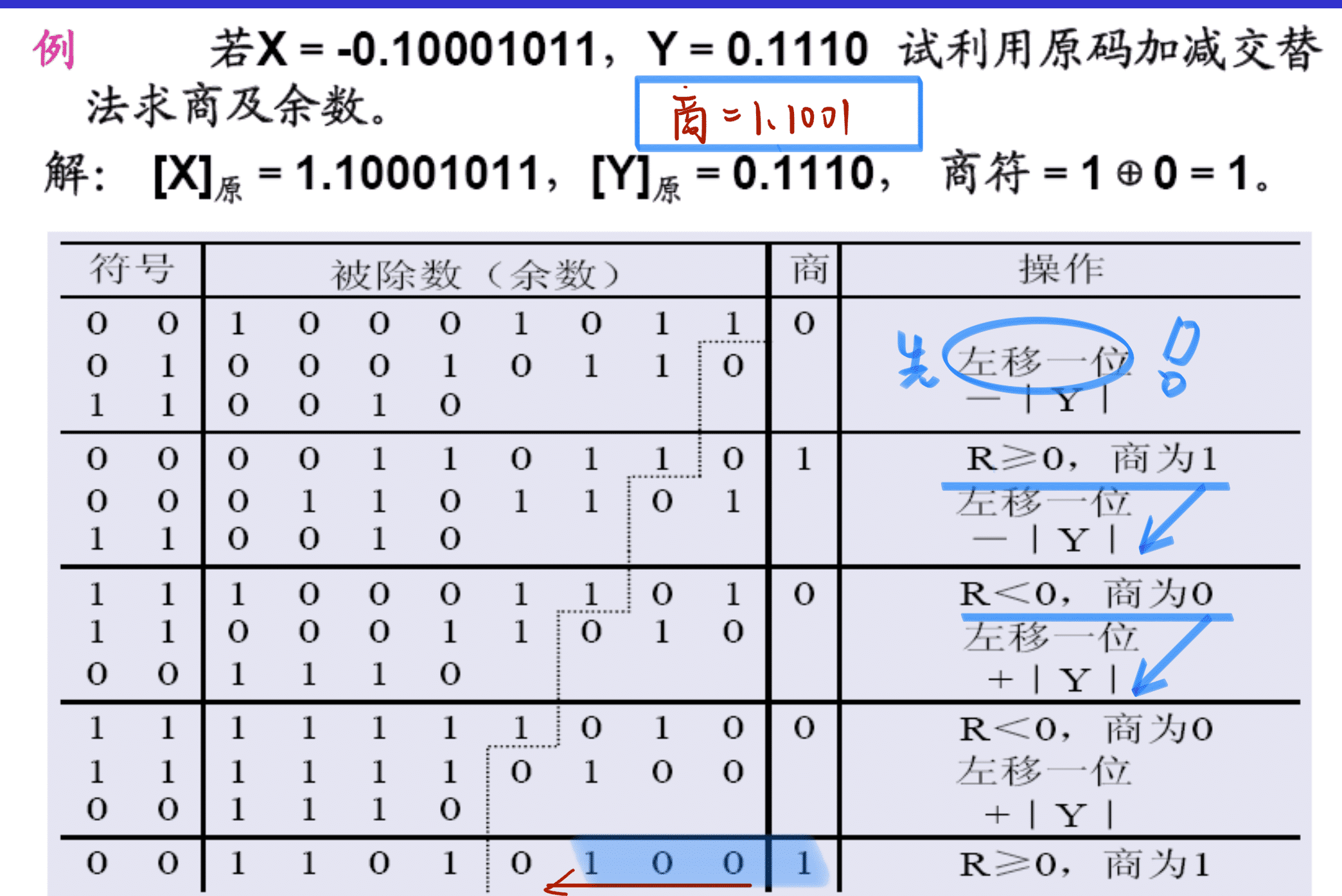
末位商如果为0,此时的余数是错误的。此时通过恢复余数码来得到正确的余数。

我觉得恢复余数法和加减交替法之间在计算过程中并无差异,主要是思想上的不同:恢复余数指的是不断减去除数,如果余数是负的,就要恢复余数为正的(加上除数),再不断减去除数;加减交替指看余数的正负,正的就减除数,负的就加除数。
1.3.2 补码一位除
这个是课后学习,但是出了一道关于这个的课后题。所以还是看看。

余数的校正规则:
- 若商为正:余数与被除数异号,余数+除数
- 若商为负:余数与被除数异号时,余数-除数
2. ALU
2.1 运算器的结构
基本组成包括算术逻辑单元ALU、暂存器、通用寄存器堆、内部总线。
2.1.1 标志寄存器、标志位
标志寄存器,又称状态寄存器。(我感觉状态寄存器更常用一点)用于保存ALU操作结果的某些状态。不同CPU,标志寄存器中包含的标志不尽相同。但是都会有如下最基本的5中标志位:
- ZF=1:结果全为0。
- CF=1:表示有进位或者是借位。
- OF=1:运算溢出。
- SF=1:运算结果为正数。(现代微机中,有符号数采用补码表示)
- PF=1:反映运算结果中‘1’的个数为偶数。
3. 浮点运算
3.1 浮点加减
①对阶:只有在两者的阶码相同时才能进行尾数的加减运算。其原则是小阶对大阶。也就是将小阶码(更小的数字挪到大数字的小数点处)
不断地右移获得阶码+1。==但是会在对阶时丢失尾数的低位,造成的误差相对较小。==但要是大阶对小阶,就会就是尾数的高位,导致错误的结果。
②尾数进行加减运算(直接相加或是加补)
③规格化:在进行完计算后可能得到的是一个非规格化数。则需要进行规格化。
(1)左规 ←
尾数是: 00.0 X X ⋅ ⋅ ⋅ X 00.0XX···X 00.0XX⋅⋅⋅X 或是 11.1 X X ⋅ ⋅ ⋅ X 11.1XX···X 11.1XX⋅⋅⋅X
左规时,尾数每左移一位,阶码减1,必须同时判断阶码是否减到比所能表示的阶码还小。
如果出现,阶码无法表示太小的阶码,就出现了下溢出。(下溢出发生可认为结果=0)
(2)右规 →
结果出现: 10. X X X ⋅ ⋅ ⋅ X 10.XXX···X 10.XXX⋅⋅⋅X 或是 $ {0}1.XXX···X$
表示尾数出现溢出,但并不代表整个结果浮点数溢出。
出现上述情况,可将尾数右移最多一次,阶码+1。
可能会出现阶码超出能表示的最大范围,发生上溢出。
④舍入处理:在对阶以及规格化的时候,需要将尾数右移,右移会丢弃尾数的最低位,出现了舍入的问题。一般采用以下三种方法。
(1)截断法:将需要丢弃的尾数低位丢弃。
(2)末位恒置1法:无论尾数右移丢弃的是0还是1,此法需要保证保留的尾数的最低位永远为1.
(3)0舍1入法:当尾数右移丢弃的是1,要保留的最末位+1,当丢弃0,保留的最末位不变。
(但是可能遇到01.1111111时发生溢出,因此需要使用截尾法。)
3.2 浮点乘除


(四)指令系统和汇编语言
1. 指令格式
设置指令系统的要求是:完备性、有效性、规整性、兼容性。
Huffman编码的主要缺点:
- 操作码长度很不规整,硬件编码困难。
- 与地址吗共同组成固定长的指令比较困难。
扩展编码方式
有等长15/15/15…扩展法 or 等长 8/64/512…扩展法。(只是众多扩展法之二)
- 是一种重要的指令优化技术:缩短指令平均长度、减少程序总位数和增加指令字所能表示的操作信息。
- 一般用在指令字长较短的微、小型机上。
2. 寻址方式
指令中以什么方式提供操作数或操作数地址,称为寻址方式(或是编址方式)。
以下是以8086/8088为例:

8088中,这些寄存器是16位的。

2.1 存储器寻址
将逻辑地址转化为物理地址(绝对地址)的计算公式:
物
理
地
址
=
段
寄
存
器
的
内
容
×
16
+
偏
移
地
址
物理地址=段寄存器的内容\times 16 + 偏移地址
物理地址=段寄存器的内容×16+偏移地址
相当于将对寄存器的内容左移4位,一个简单栗子如下:

2.2 ⭐⭐8088CPU的寻址方式
8086/8088指令中说明操作数所在地址的寻址方式一共八种。
- 立即寻址:
MOV AX,2000H后面的操作数直接包含在指令中,放在代码段 - 寄存器寻址:
MOV AX,BX操作数在CPU内部的内部寄存器中 - 段寄存器寻址:
MOV AX,DS - 直接寻址:
MOV AX,[2000H]操作数放在存储器,操作数地址的16位段内偏移地址直接包含在指令中 - 寄存器间接寻址:
MOV AX,[BX]操作数放在存储器,段内偏移地址放在指针寄存器中 - 寄存器相对寻址:
MOV AX,disp[BX]存储器+指针寄存器+指令中相对偏移量 - 基址变址寻址:
MOV AX,[BX][SI]存储器+基址+变址(寄存器) - 基址变址相对寻址:
MOV AX,disp[BX][SI]存储器+基址+变址+指令中相对偏移量 - 隐含寻址:
MOV BL、CLC将操作数的地址隐含在指令操作码中
2.2.1 转移地址的地址方式
转移地址的寻址方式,也就是找出程序转移的地址(下一条指令的地址),而不是操作数。
8086/8088中,CS:IP为CPU当前==要(will)==读取的指令的地址,改变CS:IP中的内容就会程序转移。寻求转移地址的方法有:
- 段内直接(相对)转移
- 段内间接转移
- 段间直接转移
- 段间间接转移
2.2.1.1 段内转移(CS不变、IP改变)
段内直接转移(相对转移):new IP = IP + offset
- 短程转移:
offset是8位。 - 近程转移:
offset是16位。
段内间接转移:
程序转移的地址存放在寄存器or存储器单元,指令执行使用寄存器or存储器单元的内容来更新IP的内容。
e.g. JMP BX:IP ← BX
2.2.1.2 段间转移(CS、IP均改变)
段间直接转移:
指令码中直接给出【16位的段地址+16位的偏移地址】用以更新当前的 CS & IP。
段间间接转移:
由指令码的寻址方式字节求出存放转移地址的内存地址。其低位字中存放的是偏移地址,高位字中存放的是转移段基址。
2.2.1.3 分类
从应用角度分类(汇编语言):直接转移+间接转移
从原理角度分类(机器语言):段内转移+段间转移
3. PC指令系统
3.1 传送指令
MOV OPRD1,OPRD2:OPRD1 ← OPRD2
OPRD1:主存、寄存器、段寄存器**(除CS)**
OPRD2:立即数、段寄存器(含CS)、主存、寄存器

但是以下四种情况是不允许的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wI2XXFbW-1655777085968)(https://s3.bmp.ovh/imgs/2022/06/17/892e5a1302758829.png)]
3.2 交换指令
XCHG OPRD1,OPRD2:OPRD1 ↔ OPRD2
这种交换能在通用寄存器与累加器之间、通用寄存器之间、通用寄存器与存储器之间进行。
【重点】通用寄存器!AX、BX、CX、DX
3.3 地址传送指令
-
LEA OPRD1,OPRD2:OPRD1←OPRD2(EA)load effective address

3.4 堆栈指令
PUSH OPRDPOP OPRD
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6fj3pMq-1655777355985)(https://s3.bmp.ovh/imgs/2022/06/17/938922b6d72420ff.png#pic_center)]
8088:AH/AL→SP、8086:AX→SP。
# PUSH 汇编,但是是原子操作
DEC SP
MOV SP,AH
DEC SP
MOV SP,AL
# POP 汇编,但是是原子操作
MOV AL,SP
INC SP
MOV AH,SP
INC SP
8088系统堆栈是在存储器中开辟一个特定区域,SS:SP区域始终指向栈顶,反向生长。
即栈顶是低地址,然后PUSH的时候就会栈顶地址
--。
开辟堆栈的目的:
- 存放指令操作数(变量)。
- 保护断点和现场。
此处的现场指的是CPU现场吗?是进程的上下文吗?是PCB吗?
断点:说明是发生了中断。发生中断:执行异常处理程序之前,处理器会将返回时的指令地址,以及其他一些状态(通用寄存器,堆栈指针,程序状态字等等)压入内核栈。


4. CISC & RICS
CISC:
复杂指令集计算机的主要特点是:
- 指令系统复杂,指令数目多达 200~3000 条。
- 指令长度不固定,有更多的指令格式和更多的寻址方式。
- CPU 内部的通用寄存器比较少。
- 有更多的可以访问主存的指令。
- 指令种类繁多,但各种指令的使用频度差别很大。
- 不同的指令执行时间相差很大,一般都需要多个时钟周期才能完成。
- 控制器大多采用微程序控制器来实现。
- 难以用优化编译的方法获得高效率的目的代码。
RISC:
精减指令集计算机的主要特点:
- 只设置使用频度高的一些简单指令,复杂指令的功能由多条简单指令的组合来实现。
- 指令长度固定,指令种类少,寻址方式种类少。
- 访存指令很少,有的 RISC 只有 LDA(读内存)和 STA(写内存)两条指令。多数指令的操作在速度快的内部通用寄存器间进行。
- CPU 中设置大量的通用寄存器,一般有几十个甚至几百个。
- 控制器用硬件实现,采用组合逻辑控制器。
- 采用流水线技术,大多数指令 1 个时钟周期即可完成。
- 有利用优化编译程序。
- 可简化硬件设计,降低设计成本。

\\\\\\
(五)存储系统
存储系统是指计算机中存放程序和数据的各种存储设备、控制设备以及管理信息调度的设备(Hardware)和算法(Software)所组成的系统。提供:写入和读出计算机工作需要的信息(程序和数据)的能力,实现计算机的信息记忆功能。
寄存器→Cache→MM→外存

本章主要涉及主存储器MM和高速缓存Cahce。
主存储器:关于主存的构成,各种半导体存储器的基本原理,连接使用的问题(SRAM、DRAM、ROM)。
C a c h e Cache Cache: C a c h e Cache Cache的基本原理、映射方式、替换算法以及性能分析。
1. 存储器主要的性能指标
1.1 存储容量
芯片的容量: 1 K × 4 1K\times4 1K×4位。表示该芯片有1K个存储单元、每个存储单元的长度为4位。
系统的容量: 1 K B 1KB 1KB,表示该芯片是 1 K × 8 b i t ( 1 b y t e ) 1K\times8\ bit(1\ byte) 1K×8 bit(1 byte)。
存储器速度: T m = T A + T 复 原 时 间 T_m=T_A+T_{复原时间} Tm=TA+T复原时间
T m T_m Tm:存取周期。
T A T_A TA:存取时间,包括译码时间和读出或写入时间。
T 复 原 时 间 T_{复原时间} T复原时间:读破坏类存储器的恢复时间。
可靠性:
M T B F MTBF MTBF:平均故障间隔时间( M T T F + M T T R MTTF+MTTR MTTF+MTTR)用于可维修部件的可靠性。
M T T F MTTF MTTF:平均无故障时间,用于不可维修部件的可靠性。
成本:
存储器的单位成本 c o s t cost cost: c = C S 元 位 c=\frac{C} S \frac{元}{位} c=SC位元
S:存储容量,C:整个存储器的价格
2. 主存储器

存储元:存储位、基本存储单元。用于存储1位二进制信息的电路。
存储单元:若干个存储元组成一个存储单元。许多个存储单元组成主存。
计算机的最小存储单元:字节单元。现代计算机按字节单元编址。
主存的地址空间由CPU地址线数决定。
2.1 RAM(随机读写存储器)
- SRAM(静态随机存储器)
- DRAM(动态随机存储器)
2.1.1 SRAM

数据一旦写入,其信息就稳定地保存在电路中并等待读出。只要不断电,此信息会一直保存下去。
功耗大、集成度低。
2.1.2 DRAM

2.1.3 SRAM与DRAM的对比

2.1.4 主存储器的组成和接口
- MAR:存储器地址寄存器,属于MM。
- MDR:存储器数据寄存器,属于MM。

此处的数据总线与8bit并没有关系,
存储器的速度要与CPU的速度相协调。CPU的读写内存的周期要 ≥ \ge ≥ 存储器芯片要求的读写时间。
2.1.4.1 ⭐内存构成

全地址译码:除了地址总线中参与低位地址线位,其余所有高位地址线全部参与片间地址译码的方法。它不会产生地址码重叠的存储区域,对于译码电路的要求hin高。
部分地址译码:线选与全译码结合。有的地址线未参加译码,会产生地址码重叠的存储区域。
2.1.4.2 ⭐⭐存储器的扩展
字扩展:改变译码电路,把一些地址线用于参与片选。(适用于地址线多余的情况)
位扩展:适用于数据线位数多余芯片的存储单元的长度。
字位扩展:字扩展+位扩展
2.2 ROM(只读存储器)

2.3 其他存储器
2.3.1 双端口存储器
双端口存储器指的是:具有多组(两组)独立的读写端口,允许多个(两个)CPU或控制器从多个(两个)端口同时异步访问存储单元。多端口,时间并行,用于提高访存速度。

2.3.2 多体交叉存储器
用于提高访存速度、多模块在空间上并行。
2.3.3 相连存储器
依据内容决定 内容的地址or寻找与其相关的内容。
3. Cache
高速缓存器(Cache):在程序执行时,不需要从慢速的主存中存取指令和数据,而是直接访问这种高速小容量的存储器,从而可以提高CPU程序执行速度。

3.1 ⭐地址映射
- 全相联
- 直接映射
- 组项链映射

它的地址变换表,采用相联存储器。在TLB(Transition lookaside buffer)中,为每一个存储单元设置了:
- 有效位(1位):=1有效。
- 修改为(1位):当该块在使用中数据被修改时使用。
- 为替换方便,可以使用计数器(我猜是调度)
3.2 替换算法
显然就是OS中的Memory Management调度Page的算法啦。
- RAND:随机
- FIFO:先进先出
- LRU
- LFU
- OTP

3.3 Cache性能分析
Hit Rate(命中率): H = N c N c + N m H=\frac{N_c}{N_c+N_m} H=Nc+NmNc
N C N_C NC:Cache完成存取的总次数。
N m N_m Nm:主存完成存取的总次数。

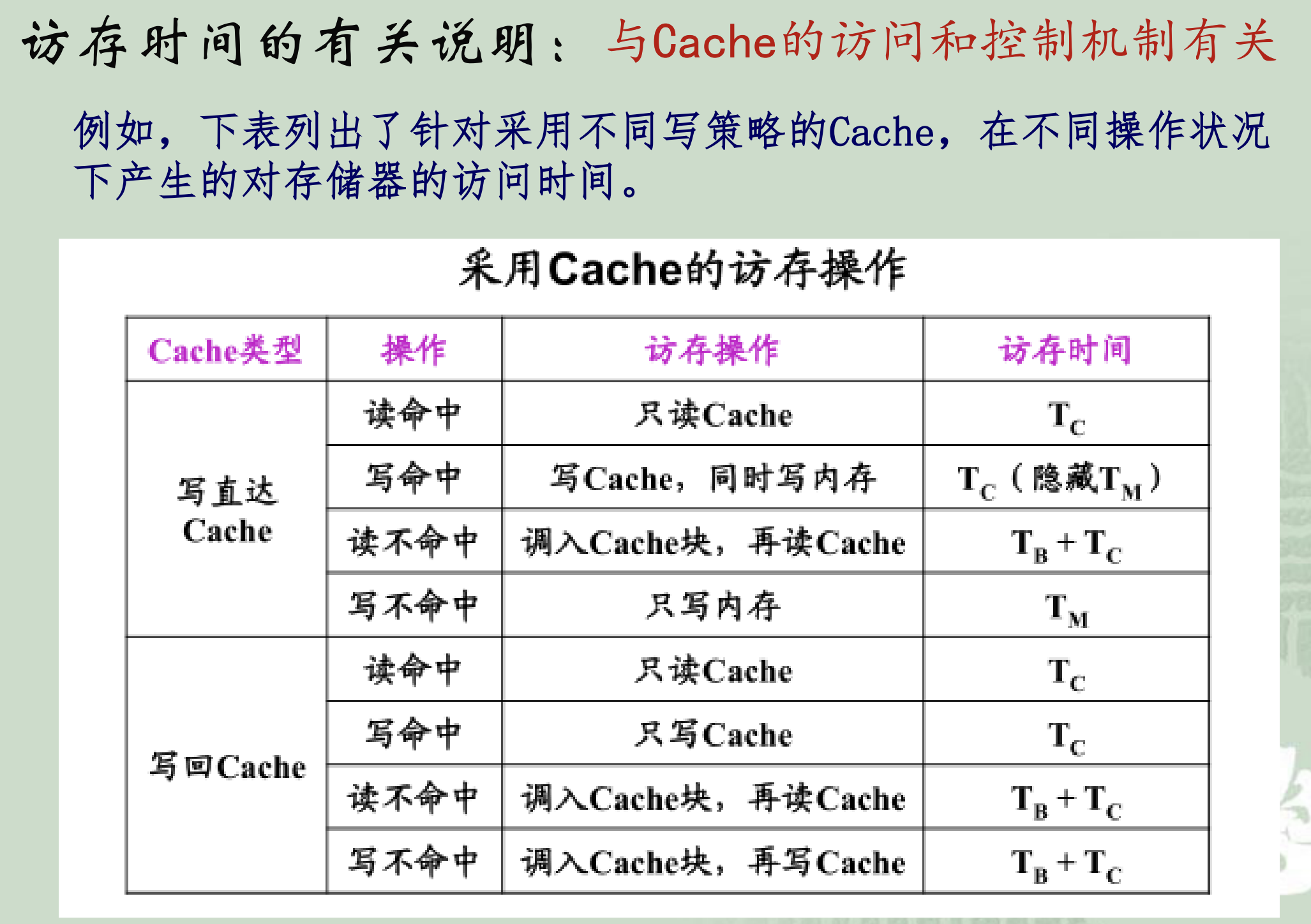
概念嘛,说不准会考呢?

4. 比较Cache-主存&主存-辅存


(六)处理器设计
1. CPU的基本构成
- 控制器:控制部件
- 运算器:数据处理
- 通用寄存器组
- (Cache高速缓存、内部总线等)
运算器和控制器在冯·诺伊曼体系中是分开的两个组成部分,但是在现代计算机中合并到了一起。

这个要和上面那个8088的寄存器图结合看一下。就是控制器内部的寄存器和通用寄存器都有,就是没有段寄存器的DS、CS、SS、ES。
CPU内部只有一条总线,是单总线结构,那么对一条加法指令ADD R0,R1来说,使用到单总线、两个锁存器以及三个时钟周期。这三个时钟周期会三次分时使用总线。
2. 指令系统设计
2.1 指令分类

这一块的详细内容按指令系统这一章来看,重点是:对于一条指令的目的、存放、还有占用地址空间(是一地址指令还是二地址这样)。
基本过程:

放一个题:

3. 时序控制方式
-
同步控制:指令执行 or 指令中每个控制信号都由事先确定的统一的时序信号进行统一控制。
-
异步控制:当控制器发出某一控制操作信号,等待执行部件完成操作后发回“回答”信号,再开始新的操作。
(没有统一的时钟信号对信号进行同步,每条指令的指令周期可由多少不等的机器周期数组成)
-
联合控制:异步联合+同步控制。
(大部分微操作序列安排在固定的机器周期中,对某些时间难以确定的操作则采用“应答”方式)

4. 指令执行
取指👉译码取操作数👉指令执行
要会写它的流程,如下:
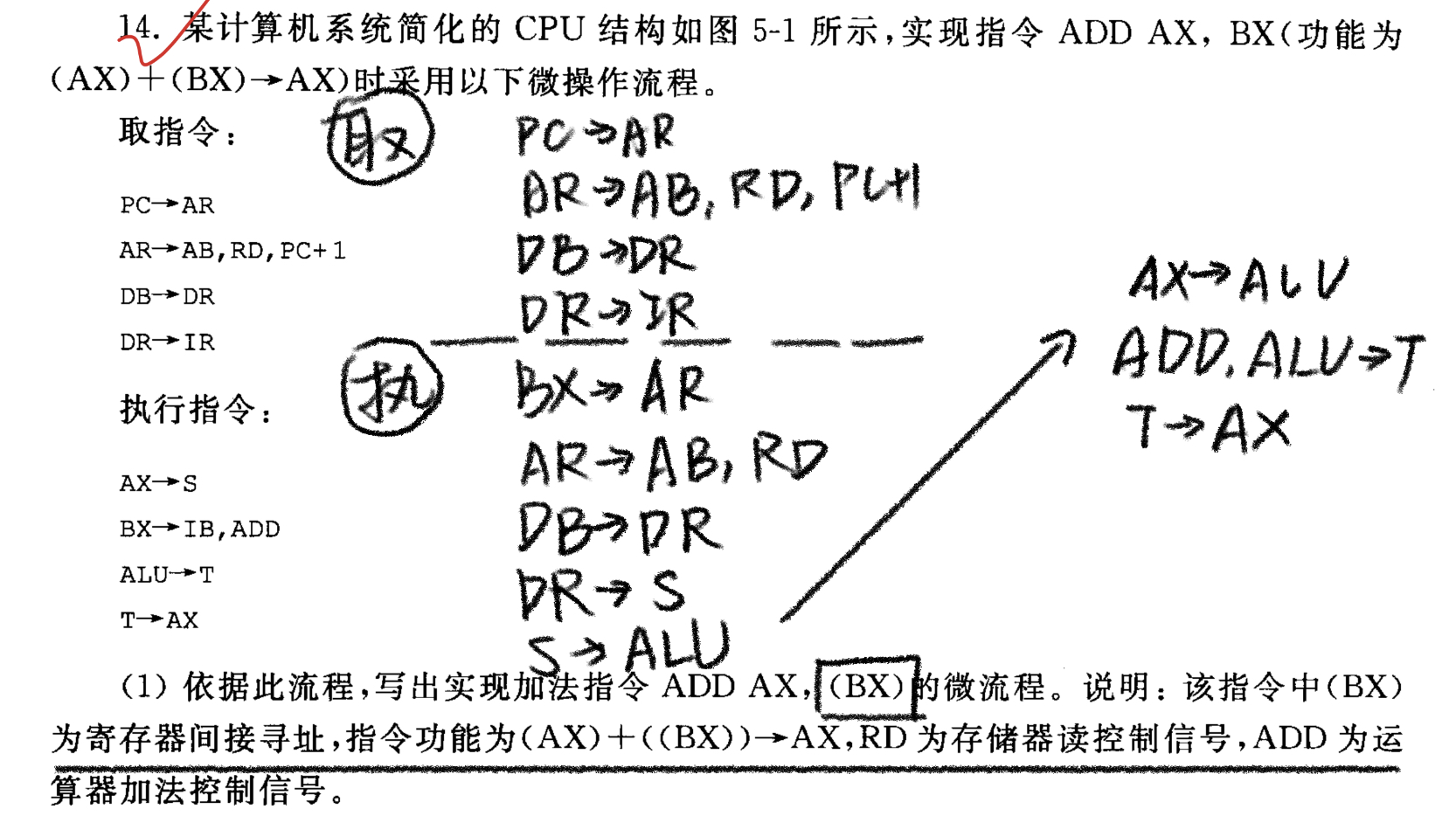
5. ⭐⭐微操作
- 微操作:控制信号控制执行的最基本操作(原子操作)。
- 微命令:实现微操作的控制信号,由控制器产生。
这个也是要会写,栗子如下:

5.1 微指令控制域编码
- 水平型微指令:多个控制信号同时有效,一条微指令定义和执行多个并行微指令。
- 垂直型微指令:**利用微操作码的不同编码来表示不同的微操作功能,**不强调微指令的并行能力,通常只能实现1-2个微命令。
5.1.1 ⭐字段译码法
将控制域分为若干字段,字段内垂直编码,字段间水平编码。互斥信号放在同一字段、相容信号放在不同字段。
- 相容信号:可以在同一个时间有效的控制信号。
- 互斥信号:不能再同一个时间有效的控制信号。
5.1.2 对水平型&垂直型的比较
















 3362
3362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









