







顺序一致性模型
什么是顺序一致性模型?简单来说就是代码的执行顺序和代码的编写顺序是一致的。这样的好处就是结果是一致正确的。这也是符合冯诺依曼体系的。但是现代的多核心处理器没有采用这种结构,因为这个模型最大的问题就是相当于没有做任何优化。导致效率是非常低的,而现代多核心处理器的优化方式就是重排序。
重排序
什么是重排序?重排序就是CPU优化代码的一种手段。替代指令的执行性能。
主要有三种类型的重排序。
1.编译器优化的重排序
2.指令级并行的重排序
3.内存系统的重排序
整个执行的过程如下图所示。
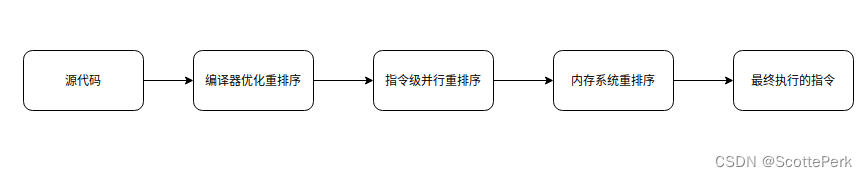
编译器优化的重排序
编译器在不改变程序在单线程环境下运行的语义的前提下,可以重新安排语句的执行顺序。这样做的目的就是为了尽可能的减少对寄存器的读取存储次数。从而充分复用寄存器信息。
例如下面的代码。c变量依赖于a变量,在栈空间里面,当给b赋值的时候是有可能把a的值给覆盖的,当c要用到a的值的时候,需要重新获取a的值,这样效率是非常低的,能够进行的优化就是编译器直接调换b和c变量这两行的执行顺序。这样c就可以直接使用a变量的值了,从而达到优化的目的,这就是编译器优化的重排序。这样的场景是非常常见的。
int a=5;
int b=6;
int c=a+1;
指令级并行的重排序
这个更好理解,如果数据不存在依赖关系,可以利用CPU的多核特性并行执行。同时也可以改变指令的执行顺序。例如下面的这种代码转换成汇编后谁先谁后都无所谓。这就是指令级并行的重排序。
int a=5;
int b=6;
int c=7;
内存系统的重排序
处理器使用缓存和读写缓冲区,多核CPU每个核心都有自己的缓存,使得数据的加载、存储操作,看上去是乱序执行的。比如在核心1有a变量,这个变量可能在核心1缓存中被修改多次,只有最后的结果被真正的写入内容。
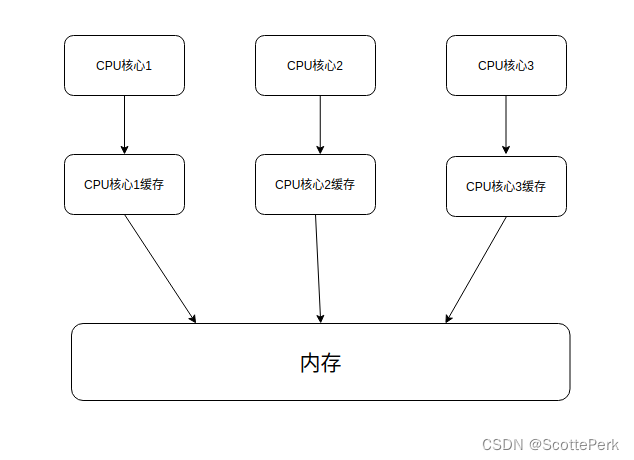
并发编程一个重要的原则,不要假定指令的执行顺序。
数据依赖
如果两个操作访问同一个共享变量,而且,这两个操作里面有一个为写操作,那么这两个操作之间就存在数据依赖性。例如下面的代码,两行代码就那么重排序,因为存在数据依赖。
int a=5;
int b=a+1;
数据依赖可分为三种类型:
1.读后写:
int a=b;
b=1;
2.写后写
int a=5;
a=6;
3.写后读
int a=5;
int b=a;
也就是说,只要对于同一个变量有两个操作只要有一个是写的情况,就不能重排序。
具有数据依赖性的指令是不会被重排序的。
as-if-serial语义
不管有没有重排序,也不关系如何进行重排序,单线程环境下,程序的执行结果不会被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
也就是说,重排序只在多线程才会存在,单线程是不会重排序的。














 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









