









Memcache的分布式算法
Memcached的分布式是什么意思?
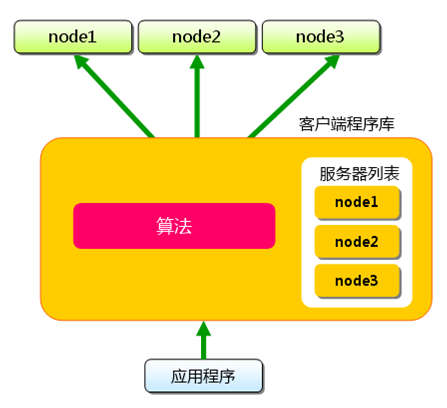
Memcached虽然成为“分布式”服务器,但是服务端根本没有“分布式”功能,而是完全有客户端实现所谓的“分布式”。
假设有node1,node2,node3三台Memcache缓存服务器,有五个不同的key值需要保存。
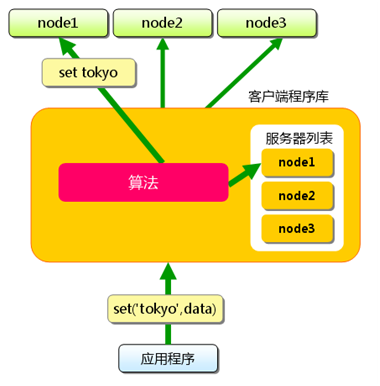
首先向memcache添加第一个key:“tokyo”,客户端接收到key后,客户端实现的算法会根据传入的键来决定保存数据的memcache服务器,服务器选定后,即保存“Tokyo”键,及其值。同样,其他剩下的键都是先选择哪台服务器,然后在保存键值对。
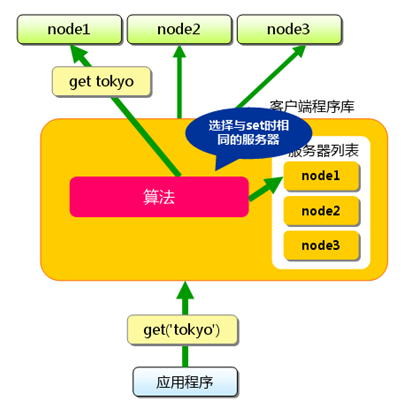
获取值的过程类似:将需要获取值的键“Tokyo”传给客户端程序,通过与保存数据时相同的算法,根据键选择服务器。使用的算法相同,就能选中与保存数据时相同的服务器。然后向选中的服务器发送get命令,进行取值操作。只要数据没有被删除,就能获取该键所对应的值。
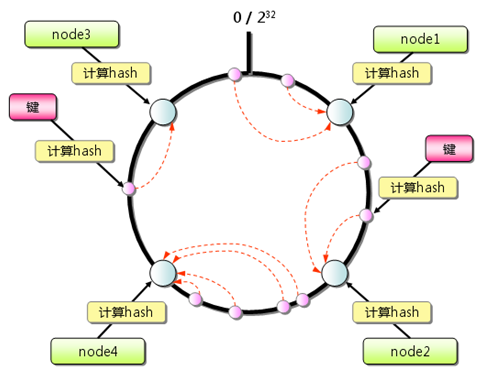
Consistent Hashing算法
分布式算法是由Memcached客户端来实现,计算键的分散的算法有余数计算分散算法(略过),Consistent Hashing算法,原理:
首先计算出Memcache**服务器(节点)的哈希值,并将其配置到0~**2的32方的圆上,然后用同样的方法找出存储的key的哈希值,并映射到圆上,然后从数据映射到圆上的位置开始顺时针寻找,将数据保存到找到的第一个服务器节点上,如果超过2的32方仍然找不到服务器,就会保存在第一台Memcached服务器上。
如果添加一台服务器,只有在增加服务器的节点与其逆时针方向第一个节点,两者之间的键值会受到影响,因此,最大程度的限制了所有键的重新排布。
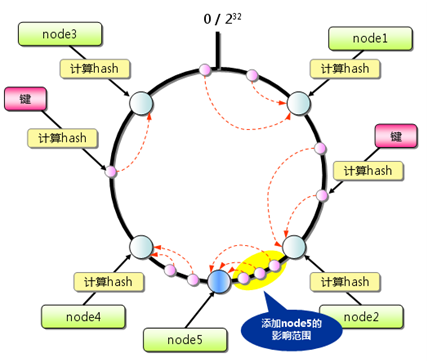
有的Consistent Hashing算法还采用了虚拟节点的思想,采用一般hash算法,服务器的映射地点分布的就不会太均匀,采用虚拟节点的思想,为每个服务器节点在continuum上分配100~200个节点,这样就能抑制服务器分布的不均匀,最大程度的减小服务器增减时的缓存重新分布















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









