







 本文探讨了SingleStore在处理地理空间数据方面的应用,通过伦敦行政区和地铁数据执行查询和可视化,展示其统一存储和查询字母数字及地理空间数据的能力。文章包括数据上传、转换、配置Databricks CE、创建数据库表、执行示例查询和使用Streamlit进行可视化的过程。此外,还提出了几个可进一步完善的方面,如数据更新和交通网络扩展。
本文探讨了SingleStore在处理地理空间数据方面的应用,通过伦敦行政区和地铁数据执行查询和可视化,展示其统一存储和查询字母数字及地理空间数据的能力。文章包括数据上传、转换、配置Databricks CE、创建数据库表、执行示例查询和使用Streamlit进行可视化的过程。此外,还提出了几个可进一步完善的方面,如数据更新和交通网络扩展。
摘要
SingleStore 是一个多模型数据库系统。除了关系数据,它还支持键值、JSON、全文搜索、地理空间和时间序列。
此前的一篇文章展示了 SingleStore 管理时间序列数据的能力,而在本文中,我们将探索地理空间数据。我们使用伦敦行政区和伦敦地铁的数据,用它们的数据集执行一系列地理空间查询,以测试 SingleStore 处理地理空间数据的能力。此外,我们还将讨论一个伦敦地铁数据的实际用例,即查找网络中两点之间的最短路径。最后,使用 Folium 和 Streamlit 创建伦敦地铁的可视化。
本文中使用的 SQL 脚本、Python 代码和笔记本文件可在GitHub 上获得,支持DBC、HTML 和 iPython 格式。
介绍
在此前的文章中,我们指出了使用 Polyglot Persistence 来管理各种数据和处理需求的问题,此外还讨论了 SingleStore 如何通过业务和技术优势成为时间序列数据的出色解决方案。本文将重点介绍地理空间数据,以及 SingleStore 如何提供统一的方法来存储和查询字母数字及地理空间数据。
首先,我们需要在 SingleStore 网站上创建一个免费的托管服务帐户,并在 Databricks 网站上创建一个免费的社区版(CE)帐户。在撰写本文时,SingleStore 的托管服务帐户附带 500 美元的积分,这对于本文中描述的案例研究来说绰绰有余。对于 Databricks CE,我们需要注册免费帐户而不是试用版。我们使用 Spark 是因为,如前一篇文章所述,Spark 非常适合使用 SingleStore 进行 ETL。
伦敦行政区的数据可以从London Datastore下载。我们使用的文件是statistics-gis-boundaries-london.zip,该文件大小为 27.34 MB。此外,需要对提供的数据进行一些转换,以便与 SingleStore 一起使用,接下来会对此简要说明。
伦敦地铁的数据可以从Wikimedia获得。它以CSV格式提供车站、路线和线路定义。该数据集虽被广泛使用,却落后于伦敦地铁的最新发展。但是,它足以满足我们的需求,并在未来很容易更新。
也可以在GitHub上找到伦敦地铁数据集的一个版本,其在路线中添加了额外的 time 列。这有助于查找最短路径,我们稍后讨论。
可以从本文的GitHub页面下载一组更新的伦敦地铁 CSV 文件。
总结一下:
1. 从London Datastore下载zip 文件。
2. 从本文的GitHub页面下载三个伦敦地铁 CSV 文件。
配置 Databricks CE
此前的文章给出了有关如何配置 Databricks CE 以和 SingleStore 一起使用的详细说明,在这个用例中我们可以借助它们。如图 1 所示,除了 SingleStore Spark Connector 和 MariaDB Java Client jar 文件外,还需要使用 PyPI 添加GeoPandas和Folium。

图 1. 库
上传 CSV 文件
要使用三个伦敦地铁 CSV 文件,需要将它们上传到 Databricks CE 环境。上一篇文章提供了如何上传 CSV 文件的详细说明。我们可以在这个用例中使用这些确切的说明。
伦敦行政区数据
转换伦敦行政区数据
解压下载的zip文件。其中有两个文件夹:ESRI和MapInfo。在 ESRI 文件夹中,我们只关心以London_Borough_Excluding_MHW开头的文件。有不同的文件扩展名,如图 2 所示。
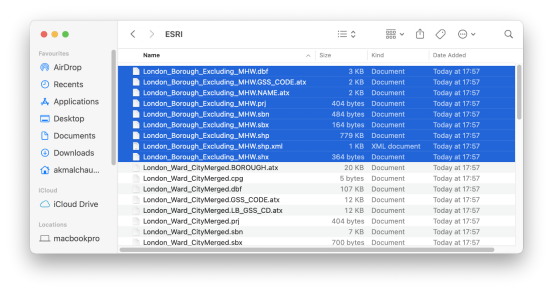
图 2. ESRI 文件夹
我们需要为 SingleStore把这些文件中的数据转换为已知文本 (WKT)格式。为此,我们可以按照 SingleStore 网站上加载地理空间数据到 SingleStore文章的建议。
第一步是使用MyGeodata Converter工具。可以拖放文件或浏览文件进行转换,如图3所示。
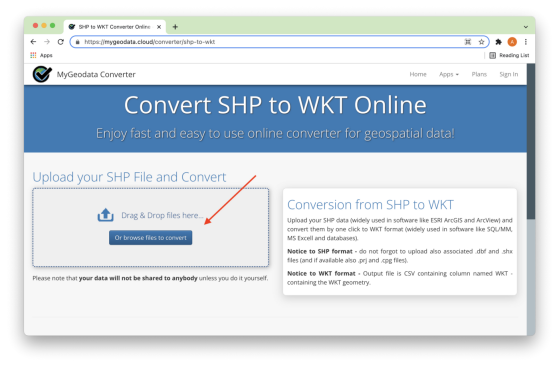
图 3. 添加文件
添加图 2 中高亮的全部九个文件,如图 4 所示。接下来,单击Continue 按钮。
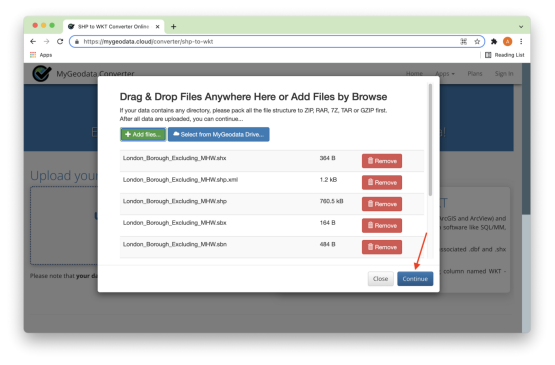
图 4. 添加文件并继续
在下一页中,需要核实输出格式是WKT,坐标系是WGS 84, 然后点击 Convert now! 按钮,如图 5 所示。
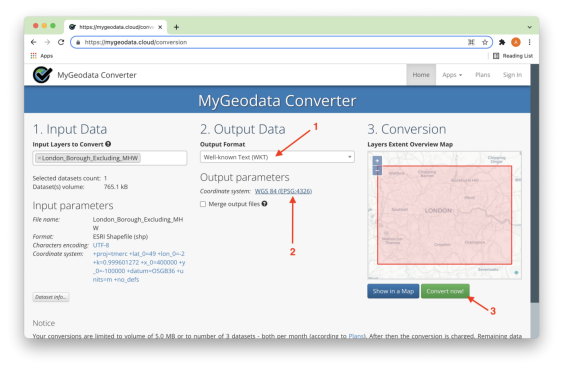
图 5. 转换选项
可以下载转换结果,如图6所示。
图 6. 下载转换结果
这会下载一个 zip 文件,其中含有一个名为London_Borough_Excluding_MHW.csv的 CSV 文件。该文件包含一个标题行和 33 行数据。名为 WKT的列,有 30 行POLYGON数据,有 3 行MULTIPOLYGON数据。我们需要将MULTIPOLYGON数据转成POLYGON数据。使用 GeoPandas 可以很快实现。
接下来,我们也要将此 CSV 文件上传到 Databricks CE。
创建伦敦行政区数据库表
在我们的 SingleStore 托管服务帐户中,使用 SQL 编辑器创建一个新数据库,名为geo_db,如下:
复制
SQL
CREATE DATABASE IF NOT EXISTS geo_db;
- .
还要创建一个表,如下:
复制
SQL
USE geo_db;
CREATE ROWSTORE TABLE IF NOT EXISTS london_boroughs (
name VARCHAR(32),
hectares FLOAT,
geometry GEOGRAPHY,
centroid GEOGRAPHYPOINT,
INDEX(geometry)
);
SingleStore 可以存储三种主要的地理空间类型:多边形、路径和点。在上表中,GEOGRAPHY可以保存多边形和路径数据。GEOGRAPHYPOINT可以保存点数据。在我们的示例中,geometry列保存每个伦敦行政区的形状,centroid列保存每个行政区的大致中心点。如上所示,可以将此地理空间数据与其他数据类型(例如VARCHAR和FLOAT)一起存储。
伦敦行政区数据加载器
现在新建一个 Databricks CE Python 笔记本,命名为Data Loader for London Boroughs。把新笔记本附加到 Spark 集群上。
在一个新代码单元中,添加以下代码以导入几个库:
复制
Python
import pandas as pd
import geopandas as gpd
from pyspark.sql.types import *
from shapely import wkt
接下来,定义模式:
复制
Python
geo_schema = StructType([
StructField("geometry", StringType(), True),
StructField("name", StringType(), True),
StructField("gss_code", StringType(), True),
StructField("hectares", DoubleType(), True),
StructField("nonld_area", DoubleType(), True),
StructField("ons_inner", StringType(), True),
StructField("sub_2009", StringType(), True),
StructField("sub_2006", StringType(), True)
])
现在使用定义的模式读取 CSV:
复制
Python
boroughs_df = spark.read.csv("/FileStore/London_Borough_Excluding_MHW.csv",
header = True,
schema = geo_schema)
- .
删除一些列:
复制
Python
boroughs_df = boroughs_df.drop("gss_code", "nonld_area", "ons_inner", "sub_2009", "sub_2006")
现在我们浏览一下数据结构和内容:
复制
Python
boroughs_df.show(33)
输出应如下所示:
复制
Plain Text
+--------------------+--------------------+---------+
| geometry| name| hectares|
+--------------------+--------------------+---------+
|POLYGON ((-0.3306...|Kingston upon Thames| 3726.117|
|POLYGON ((-0.0640...| Croydon| 8649.441|
|POLYGON ((0.01213...| Bromley|15013.487|
|POLYGON ((-0.2445...| Hounslow| 5658.541|
|POLYGON ((-0.4118...| Ealing| 5554.428|
|POLYGON ((0.1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









