







一、常用序列化器字段
序列化器字段处理基元值和内部数据类型之间的转换。它们还处理输入值的验证,以及从它们的父对象检索和设置值。
(1)核心参数
每个序列化器字段类构造函数至少接受这些参数。一些字段类还接受额外的,字段特定的参数,但以下应参数应该一直被接受:
read_only
字段只读,默认值为False。只读字段只会包含在序列化输出中,创建修改对象时不会包含该字段,即使输入了也会被忽略。
write_only
字段只写,默认值为False。和read_only相反,序列化时不包含,创建修改对象时必须包含该字段。
required (模型中设置blank=True,该模型序列化器自动给你设置required=False)
字段必须,默认值为True。必须字段在创建修改对象时必须包含,否则抛出异常。当设置为False时,在创建修改对象时可以不用包含该字段。
default
默认值。如果一个字段设置了默认值,那么在反序列化时,如果没有提供该字段,则使用默认值进行填充。
在进行局部更新时,default不会应用。因为局部更新时,只有更新的字段会被校验和返回。
还可以设置一个函数或者一个可调用对象,
可以设置为一个函数或其他可调用对象,在这种情况下,会使用调用后的结果进行填充。调用时,它将不接收任何参数。如果可调用对象有一个requires_context = True的属性,那么序列化字段会被当做参数传入。例如:
class CurrentUserDefault:
"""
May be applied as a `default=...` value on a serializer field.
Returns the current user.
"""
requires_context = True
def __call__(self, serializer_field):
return serializer_field.context['request'].user在序列化实例时,如果实例中不存在对象属性或字典键,将使用default的值填充。
注意,设置默认值意味着该字段不是必需的。同时包含默认和必需的关键字参数是无效的,将引发错误。
allow_null
通常,如果将None传递给序列化器字段,将引发错误。如果None应该被认为是一个有效值,则将该关键字参数设置为True。
注意,如果没有显式的默认值,将该参数设置为True将意味着序列化输出的默认值为None,但这并不意味着输入反序列化是默认的。
默认值为False
source
将用于填充字段的属性的名称。可以是一个只接受self参数的方法, 比如URLField(source='get_absolute_url'),或者是一个句点法的属性,比如CharField(source='channel.name')。
当使用句点法序列化字段时,如果在属性遍历期间没有任何对象或为空,则可能需要提供一个默认值。
默认值为字段的名称。
用法一:模型序列化器上新定义一个属性,source对应模型里面的方法,属性值是模型里该方法的返回值。
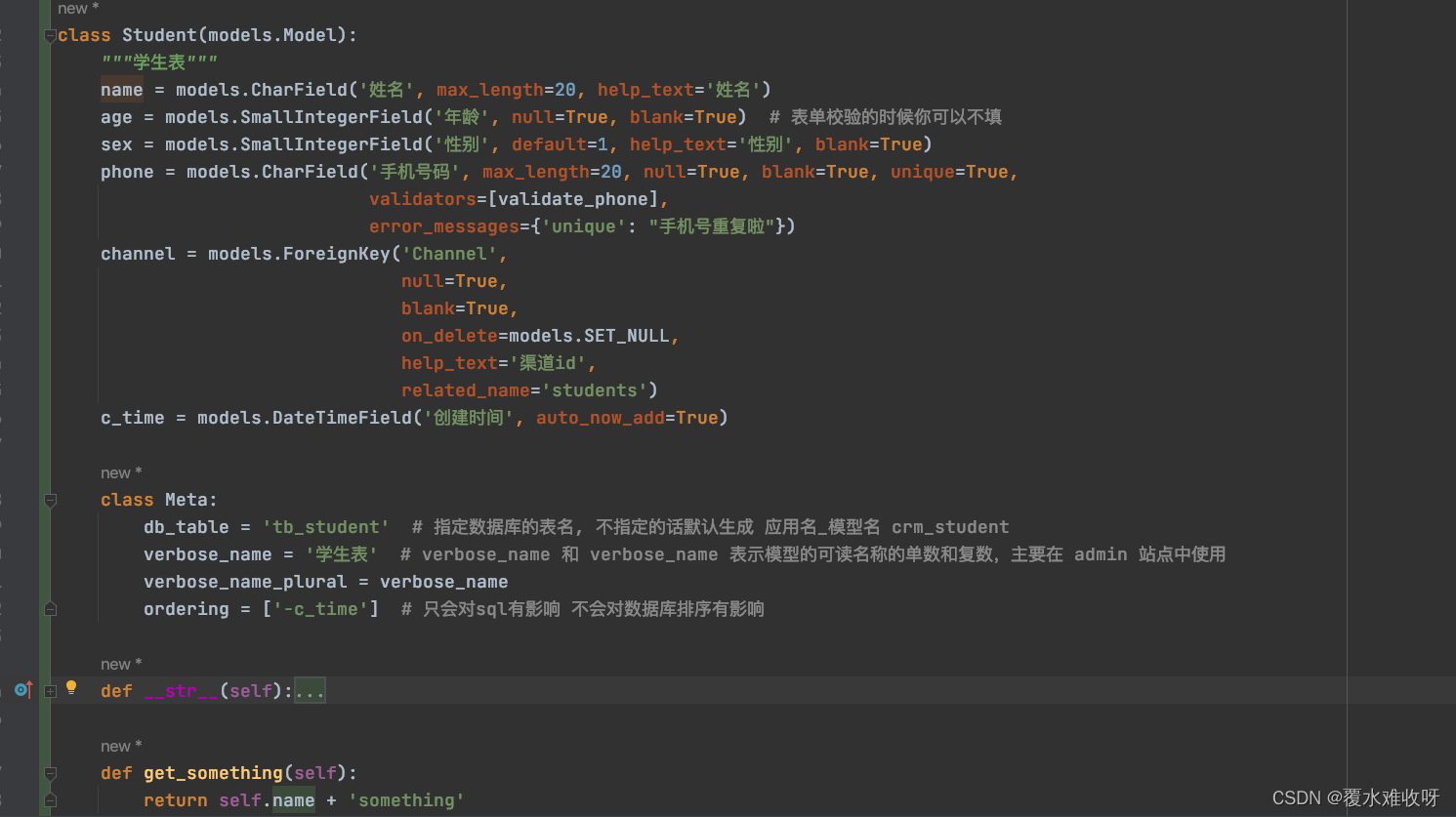

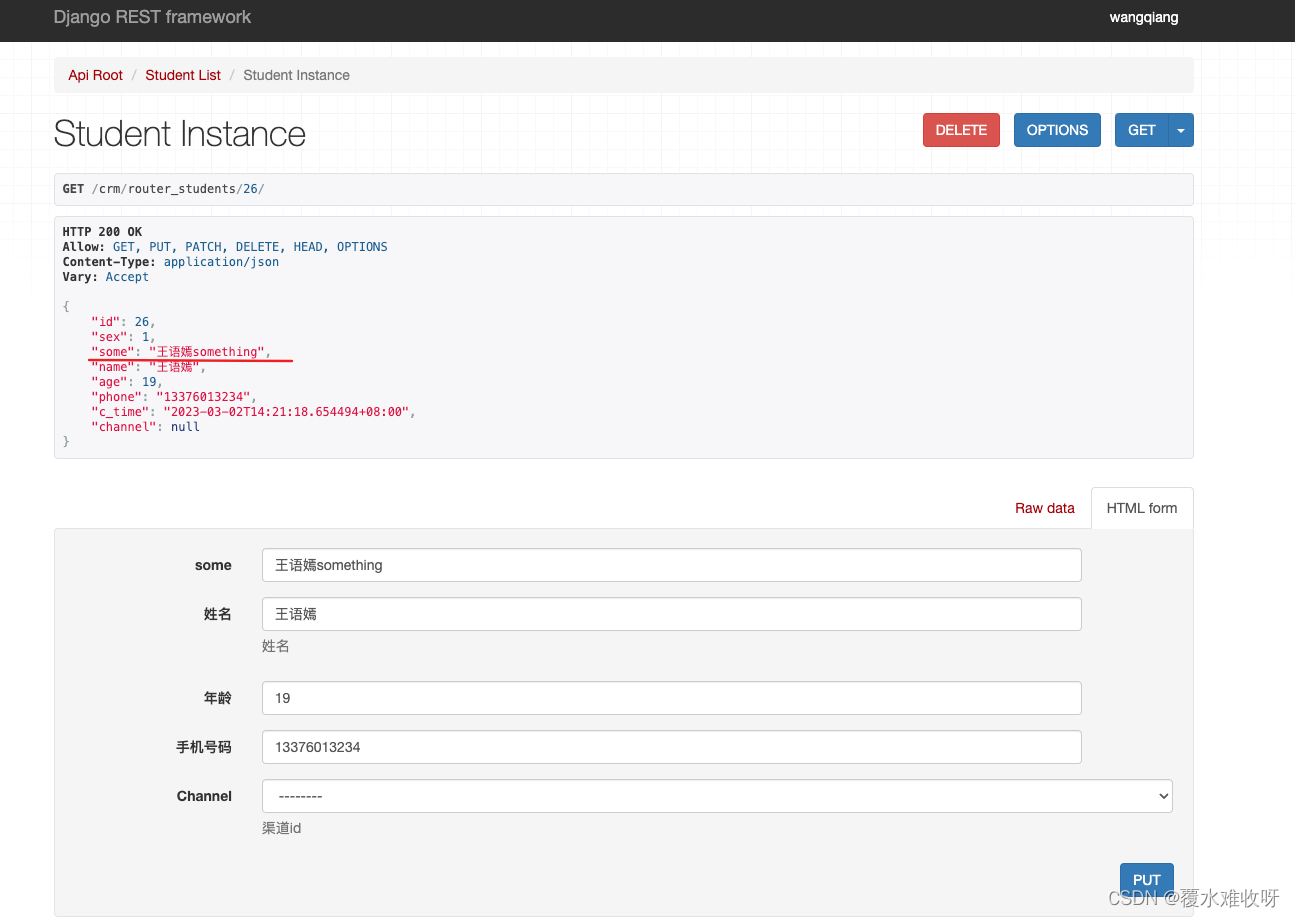
用法二 :模型序列化器上新定义一个属性channel,source='channel.title',意思就是取当前模型对象的channel.title。
没用之前效果展示:
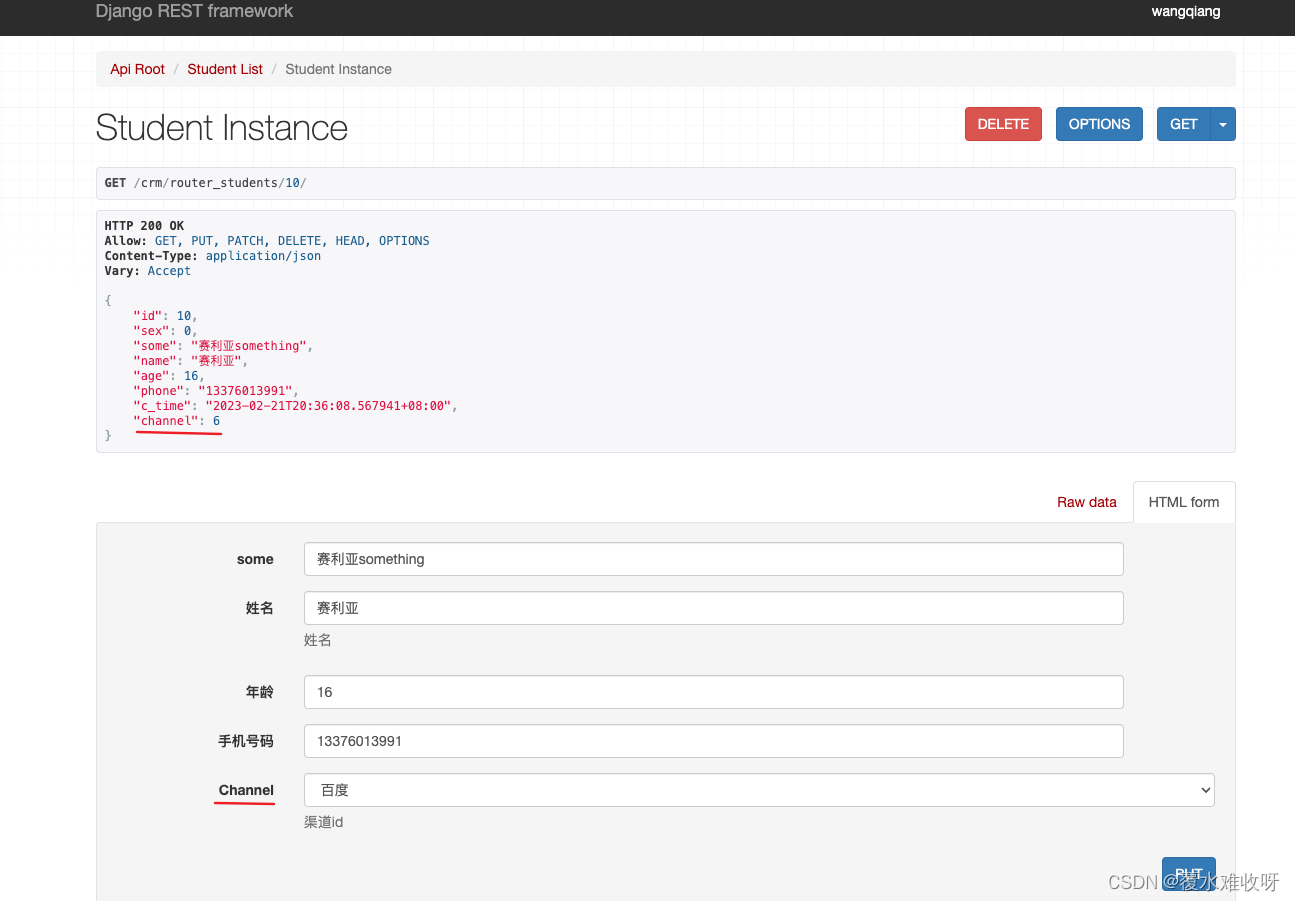
用了之后效果图:能看出来区别了吗

validators
应该应用到输入字段的验证器函数的列表,它要么引发验证错误,要么简单地返回。验证器函数通常应该引发serializers.ValidationError,但Django内置的ValidationError也被支持,以便与Django或第三方Django包中定义的验证器兼容。
error_messages
错误消息字典。
label
一个短文本字符串,可以用作HTML表单字段或其他描述性元素中的字段名。
help_text
可以在HTML表单字段或其他描述性元素中用作字段描述的文本字符串。
CharField
文本字段,可以验证文本小于max_length大于min_length
RegexField
文本字段,可以验证文本是否匹配给定正则表达式。在CharField得基础上增加得功能
IntergerField
整数字段,可以验证整数小于max_value,大于min_value
FloatField
实数字段,可以验证整数小于max_value,大于min_value
DecimalField
以十进制表示Python中由decimal的实例。
更多详解官方文档:Serializer fields - Django REST framework
(2)关系字段
关系字段用来表达模型关系。它们可以应用于ForeignKey, ManyToManyField和OneToOneField关系,以及反向关系,和自定义关系,如GenericForeignKey。
通常使用模型序列化器时,将自动生成序列化字段和关系。
StringRelatedField
StringRelatedField可以使用关系目标的__str__方法来表示。
例如:
class StudentSerializer(serializers.ModelSerializer):
# 序列化后显示channel实例的__str__返回的值
channel = serializers.StringRelatedField()
class Meta:
model = Student
fields = '__all__'序列化学生表示如下:
{
'id': 3,
'channel': '抖音',
'name': '赵六',
...
}用之前:
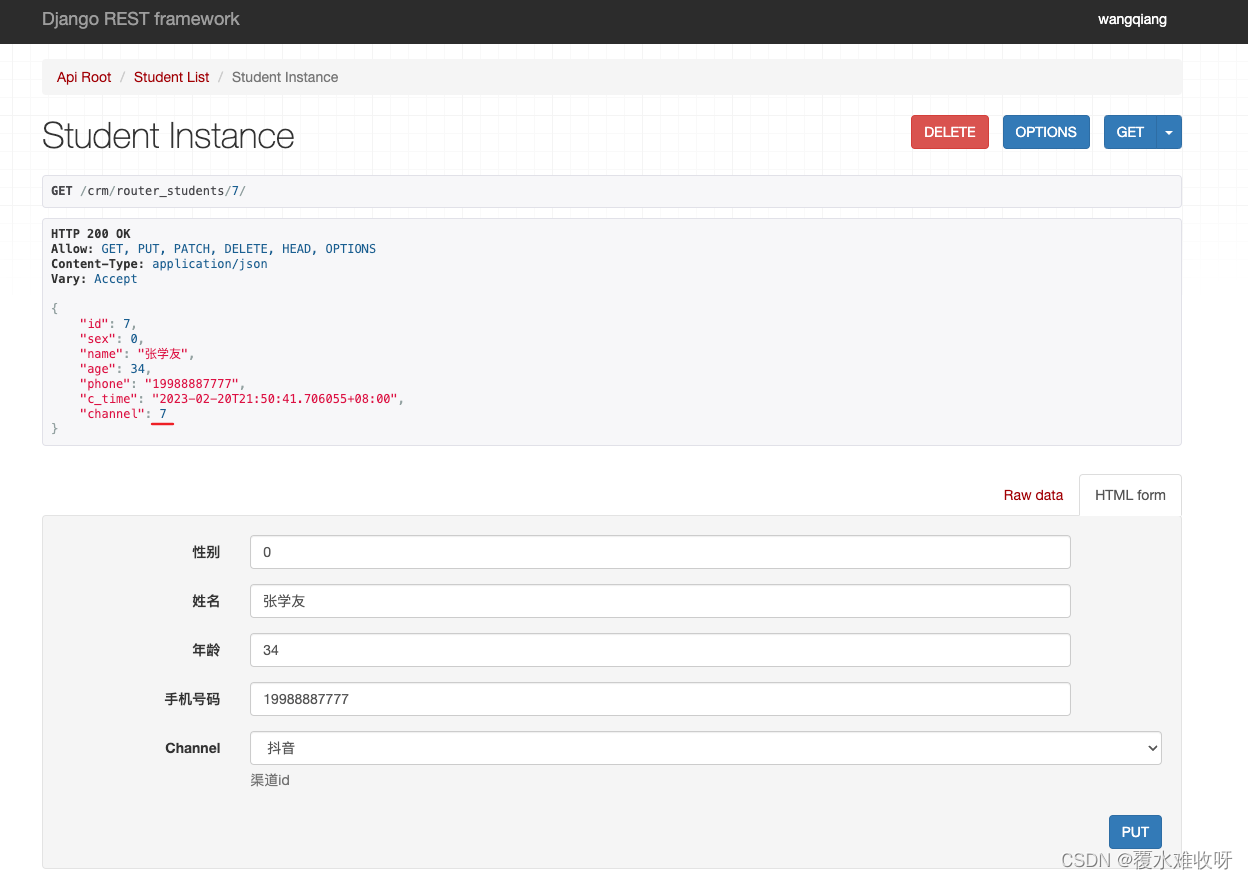
用之后:
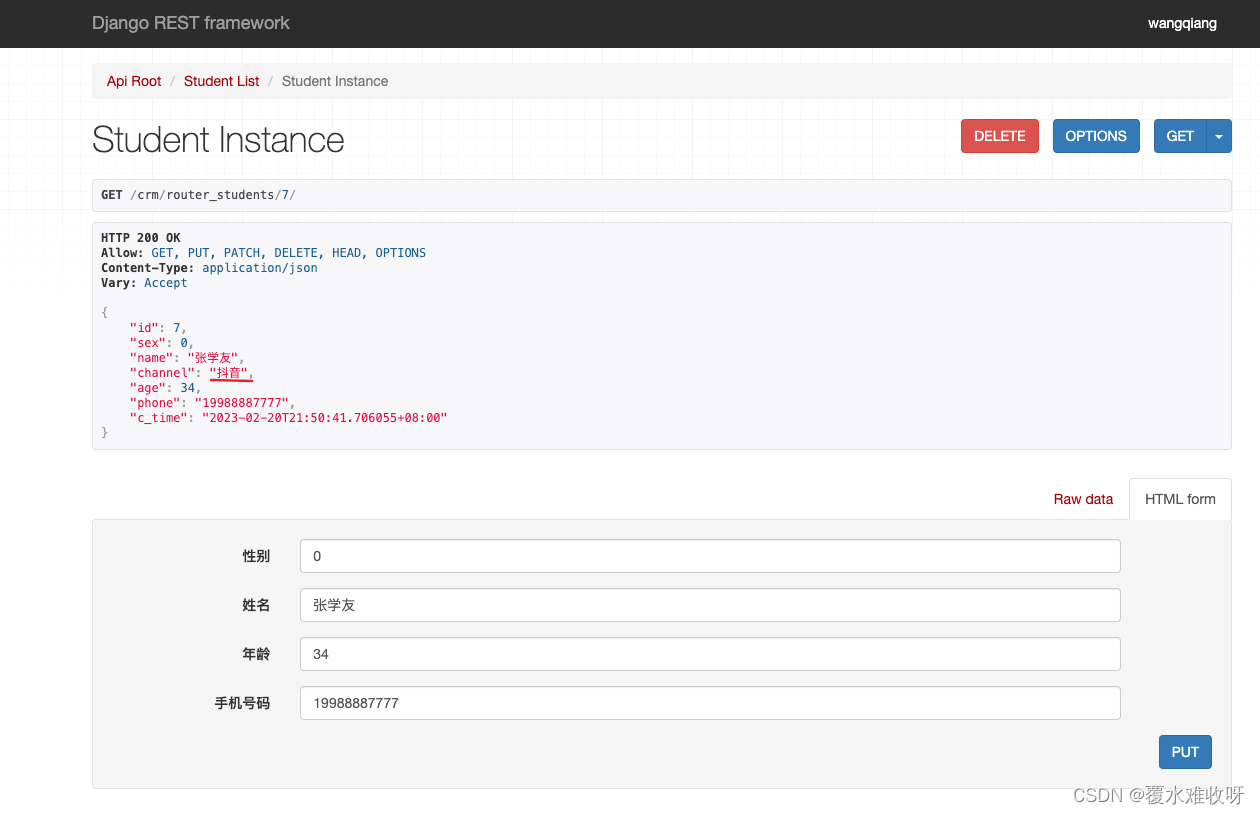
大家看出区别来了吗?
为什么下面看不到channel字段,因为这个字段默认是只读的,只可序列化不能反序列化。
channel字段7对应的title是抖音也展示出来了。
参数
many-如果应用于一对多关系,则应该将此参数设置为True。
PrimaryKeyRelatedField
PrimaryKeyRelatedField可以使用关系目标的主键来表示。一般自动去生成,不需要手动去生成。

原先channel列表展示:
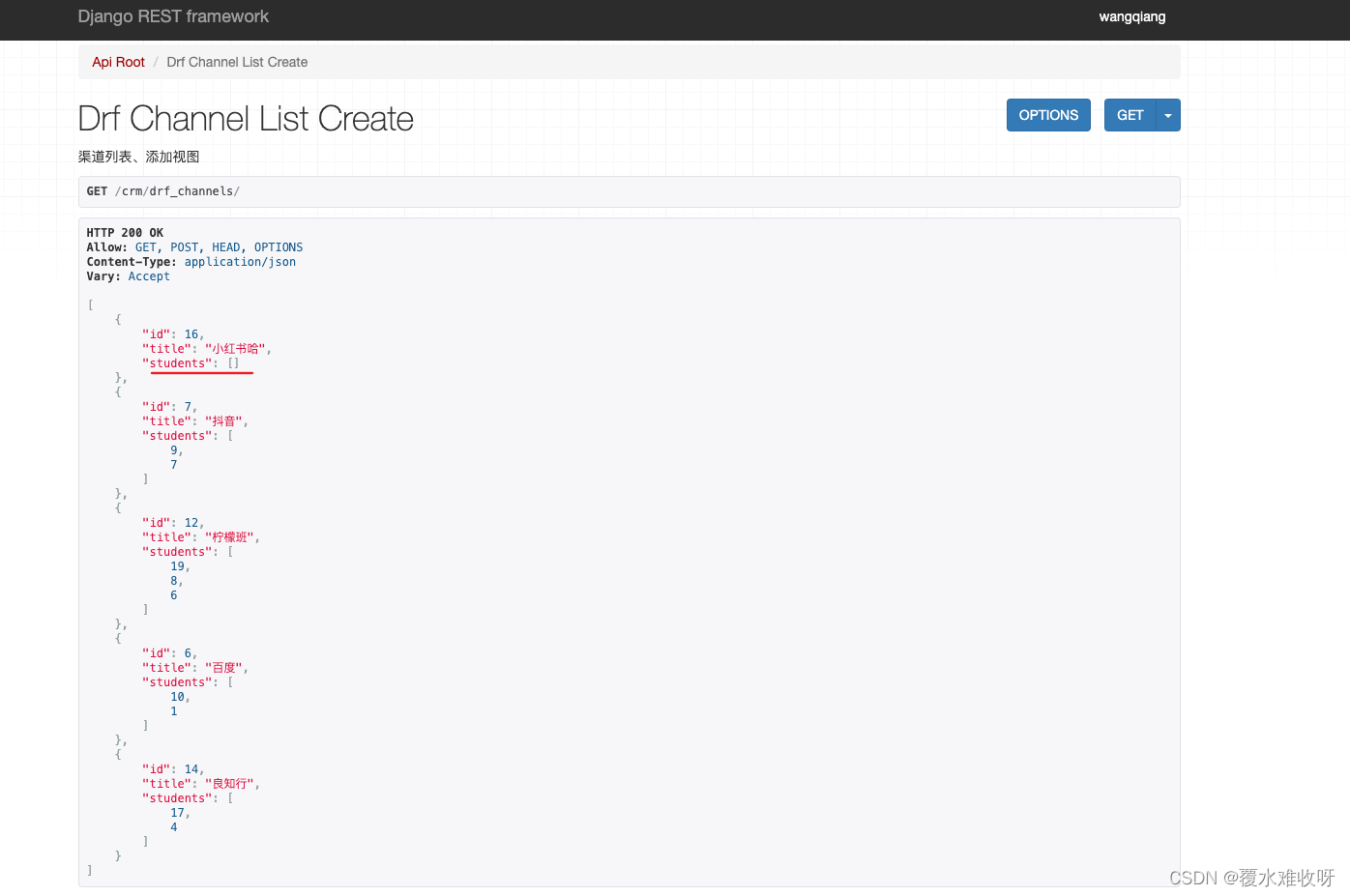
我们在channel序列化器中fields新增一个students试试看

这个时候再看下channel列表有啥变化。是不是多了一个students字段。手动添加这个students之后就能发反向把你这个值获取。这个students是一个列表。
例如:
class StudentSerializer(serializers.ModelSerializer):
# 序列化后显示channel实例的__str__返回的值
channel = serializers.PrimaryKeyRelatedField(read_only=True)
class Meta:
model = Student
fields = '__all__'序列化学生表示如下:
{
'id': 3,
'channel': 1,
'name': '赵六',
...
}默认情况下,这个字段是可读写的,可以使用read_only设置为只读。
参数
queryset- 验证字段输入时用于模型实例查找的queryset。关系必须显式设置一个queryset,或者设置read_only=True。many- 如果应用于一对多关系,则应该将此参数设置为True。allow_null- 如果设置为True,该字段将接受None的值或空字符串的可空关系。默认是Falsepk_field- 设置为一个字段来控制对主键值的序列化/反序列化。
HyperlinkedRelatedField
HyperlinkedRelatedField使用一个超链接来表示关系目标。
例如:
class StudentSerializer(serializers.ModelSerializer):
channel = serializers.HyperlinkedRelatedField(read_only=True, view_name='channel-detail')
class Meta:
model = Student
fields = '__all__'序列化学生表示如下:
{
'id': 3,
'channel': 'http://127.0.0.1:8000/channel/1/',
'name': '赵六',
...
}默认情况下,这个字段是可读写的,可以使用read_only设置为只读。
注意:该字段是为映射到一个URL的对象设计的,该URL接受一个URL关键字参数,使用lookup_field和lookup_url_kwarg参数设置。
这仅适用于URL中包含一个主键或slug参数的URL。
参数
view_name - 关系对象的视图名称。这个参数是必须的。
queryset - 验证字段输入时用于模型实例查找的queryset。关系必须显式设置一个queryset,或者设置read_only=True。
many - 如果应用于一对多关系,则应该将此参数设置为True。
allow_null - 如果设置为True,该字段将接受None的值或空字符串的可空关系。默认是False
lookup_field - 应用于查询的字段。应该对应于被引用视图上的URL关键字参数。默认为pk
lookup_url_kwarg - URL配置文件中定义的关键字参数的名称,对应于查找字段。默认使用与lookup_field相同的值。
format - 如果使用格式后缀,超链接字段将为目标使用相同的格式后缀,除非使用format参数重写。
SlugRelatedField
SlugRelatedField使用目标上的某个字段来表示关系。
例如:
class StudentSerializer(serializers.ModelSerializer):
channel = serializers.SlugRelatedField(read_only=True, slug_field='name')
class Meta:
model = Student
fields = '__all__'序列化学生表示如下:
{
'id': 3,
'channel': '抖音',
'name': '赵六',
...
}默认情况下,这个字段是可读写的,可以使用read_only设置为只读。
当使用SlugRelatedField作为读写字段时,您通常需要确保slug字段对应的模型字段设置了unique=True。
参数
slug_field - 目标上应该用来表示它的字段。这应该是唯一标识任何给定实例的字段。这应该是必须的。
queryset - 验证字段输入时用于模型实例查找的queryset。关系必须显式设置一个queryset,或者设置read_only=True。
many - 如果应用于一对多关系,则应该将此参数设置为True。
allow_null - 如果设置为True,该字段将接受None的值或空字符串的可空关系。默认是False
(3)嵌套关系
序列化器还可以进行嵌套表示。例如:
class ChannelSerializer(serializers.ModelSerializer):
class Meta:
model = Channel
fields = '__all__'
class StudentSerializer(serializers.ModelSerializer):
qq = serializers.CharField(allow_blank=True, allow_null=True, help_text='qq号码', label='Qq号码', max_length=20, required=False,
validators=[ UniqueValidator(queryset=Student.objects.all())],
error_messages={
'max_length': 'qq号码长度大于20位'
})
phone = serializers.RegexField(r'^1[3-9]\d{9}$',allow_blank=True, allow_null=True, help_text='手机号码', label='手机号码', max_length=11, min_length=11, required
=False, validators=[ UniqueValidator(queryset=Student.objects.all())])
channel = ChannelSerializer(read_only=True)
# 元信息
class Meta:
# 指定根据哪个模型生成序列化器
model = Student
# 指定序列化哪些字段
# fields = ['id', 'name', 'sex']
# 所有字段
fields = '__all__'
# fields = ['id', 'name', 'channel_name']
# 排除
# exclude = ['id']
(4)模型序列化器
检查一个模型序列化器
直接打印模型序列化器的实例
指定包含字段
fields = ['id', 'account_name', 'users', 'created'] # 显示指定
fields = '__all__' # 所有字段
exclude = ['users'] # 排除字段指定内嵌序列化
默认的ModelSerializer使用主键作为关系,但你也可以使用depth选项轻松地生成嵌套表示:
class StudentSerializer(serializers.ModelSerializer):
...
class Meta:
model = Student
fields = '__all__'
depth = 1应该将depth选项设置为一个整数值,表示嵌套的深度。如果您想自定义序列化的方式,您需要自己定义字段。
显示指定额外字段
你可以通过在类上声明字段来向ModelSerializer添加额外的字段,或者覆盖默认字段,就像您对Serializer类所做的那样。
class StudentSerializer(serializers.ModelSerializer):
channel_name = serializers.CharField(source='channel.name')
class Meta:
model = Student
fields = '__all__'指定只读字段
您可能希望将多个字段指定为只读。您可以使用快捷的Meta选项read_only_fields,而不是使用read_only=True属性显式地添加每个字段。
class StudentSerializer(serializers.ModelSerializer):
channel_name = serializers.CharField(source='channel.name')
class Meta:
model = Student
fields = '__all__'
read_only_fields = ['channel_name']额外的关键字参数
还有一个快捷方式,允许您使用extra_kwargs选项在字段上指定任意额外的关键字参数。与read_only_fields的情况一样,这意味着您不需要在序列化器上显式声明该字段。这个选项是一个字典,将字段名映射到关键字参数的字典。例如:
class StudentSerializer(serializers.ModelSerializer):
...
# channel = ChannelSerializer(read_only=True)
# 元信息
class Meta:
# 指定根据哪个模型生成序列化器
model = Student
# 指定序列化哪些字段
# fields = ['id', 'name', 'sex']
# 所有字段
fields = '__all__'
extra_kwargs = {
'qq': {'error_messages':{'max_length':'qq号码长度大于20位'}}
}反序列化校验
反序列化数据时,始终需要在尝试访问已验证数据或保存对象实例之前调用is_valid()。如果发生任何验证错误,该.errors属性将包含一个字典,表示生成的错误消息。
{'phone': [ErrorDetail(string='请确保这个字段至少包含 11 个字符。', code='min_length'), ErrorDetail(string='输入值不匹配要求的模式。', code='invalid')]}字典中的每个键都将是字段名称,值将是与该字段对应的任何错误消息的字符串列表。non_field_errors将列出任何一般验证错误。
字段级验证
您可以通过向子类添加.validate_<field_name>方法来指定自定义字段级验证。这些方法采用单个参数,即需要验证的字段值。您的validate_<field_name>方法应该返回经过验证的值或引发serializers.ValidationError. 例如:
class StudentSerializer(serializers.ModelSerializer):
...
def validate_phone(self, value):
if not re.match(r'^1[3-9]\d{9}$', value):
raise serializers.ValidationError('请输入正确的手机号码!')
return value
class Meta:
model = Student
fields = '__all__'如果<field_name>在序列化程序上声明了参数,required=False则如果不包含该字段,则不会执行此验证步骤。
对象级验证
要执行需要访问多个字段的任何其他验证,请添加一个调用.validate()到您的Serializer子类的方法。此方法采用单个参数,即字段值字典
class StudentSerializer(serializers.ModelSerializer):
...
def validate(self, data):
if not (data['phone'] and data['qq']):
raise serializer.ValidationError('请同时提供qq和电话号码')
return data
class Meta:
model = Student
fields = '__all__'验证器
序列化器上的各个字段可以包含验证器,方法是在字段实例上声明它们,例如:
def validate_phone(value):
if not re.match(r'^1[3-9]\d{9}$', value):
raise serializers.ValidationError('请输入正确的手机号码!')
class StudentSerializer(serializers.ModelSerializer):
phone = serializers.CharField(validators=[validate_phone])序列化程序类还可以包括应用于完整字段数据集的可重用验证器。这些验证器通过在内部Meta类中声明它们来包含,如下所示:
class EventSerializer(serializers.Serializer):
name = serializers.CharField()
room_number = serializers.IntegerField(choices=[101, 102, 103, 201])
date = serializers.DateField()
class Meta:
# Each room only has one event per day.
validators = [
UniqueTogetherValidator(
queryset=Event.objects.all(),
fields=['room_number', 'date']
)
]有关更多信息,请参阅验证器文档。















 2310
2310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









