






 本文介绍了如何爬取电视剧《从前有座灵剑山》分集剧情,通过BeautifulSoup解析HTML,自动化爬取并整理为txt文件。同时,利用jieba和matplotlib进行角色出场频次和顺序的可视化分析。
本文介绍了如何爬取电视剧《从前有座灵剑山》分集剧情,通过BeautifulSoup解析HTML,自动化爬取并整理为txt文件。同时,利用jieba和matplotlib进行角色出场频次和顺序的可视化分析。
本文目录如下:

第0步,准备
本文运行环境:Python3.8,Pycharm;Win10系统
需要的库 :requests、bs4
整个项目的思路是
找到目标电视剧分集剧情的链接
根据第一集剧情的网页链接,构造全部剧集的链接
爬取内容并保存
简单可视化
第1步,分析目标网页
本文的目标网页为《从前有座灵剑山》的分集剧情
分析链接
第一集的链接:https://www.jingdianlaoge.com/news/10_3829_1.htm第三十集的链接:https://www.jingdianlaoge.com/news/10_3829_30.htm数据猿发现,每一集仅数字改变,所以只需要在代码里枚举集数构造到链接里,即可实现爬取全部剧情网页。
转化为代码如下:
url_list = []
for i in range(1, num+1):
url = page_link[:-5]+'{}.htm'.format(i)
url_list.append(url)解析所爬位置
浏览器内按F12,查看该剧情页面的html代码,crtl+F来查询某一章节``,从而找到剧情内容所在的位置,可以发现没有动态加载,且全部都在一个div标签里,非常便于爬取。
第2步,解析页面
bs4解析文本
可以定位到章节所在的位置在/html/body/div[6]/div[1]/div[1]/div/div/div[1]/p标签中,而所有P标签的内容非常整齐,都在class="page-center-main ml-10 talk-main-info"的div里。所以可以使用bs4库的BeautifulSoup库,使用get_text()方法定位获取该div标签下全部P 标签的文本内容。
soup = BeautifulSoup(r.text, "lxml")
result = soup.find('div',{'class':'page-center-main ml-10 talk-main-info'}).get_text()第3步,自动化爬取
伪装浏览器响应头
这里,因为数据量小,所以不需要使用fake_useragent库生成实时改变的响应头来伪装浏览器,可以直接晚上找一个user-agent来伪装浏览器。
然后,直接使用requests库的get()方法传入当前页面的链接和响应头,即可获取整个网页html内容。为了避免不必需要的错误,可以给这个html网页限定为通用的utf-8格式编码。
header = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}
r = requests.get(url, headers=header)
r.encoding = "utf-8"第4步,写入文件
写入txt文件
使用writelines() 按集分行写入同一个txt中。
#全部下载一个文件里
with open("剧情.txt", "a",encoding='utf-8') as f:
f.write('这是第{}集,网页链接为:'.format(i+1)+j + "\n")# 标记集数的,不需要的话可以注释掉这一行。
f.writelines(content)
f.write("\n")
print('爬取结束,请查看剧情.txt文件')也可以在open中利用format()方法写入多个文件,实现按集写入多个txt中。
# 分集下载到多个文件,可以替换上面with
with open("第{}集.txt".format(i+1), "a") as f:
f.write(content)第5步,可视化
这里,数据猿想知道主要人物的戏份,也就是出场频次和顺序大概是怎么样的。
主要使用python的jieba库进行分词,然后使用matplotlib的bar(),和barh()进行角色的出场频次和顺序的可视化。
jieba分词
首先,确定要分析的主角人物
# 欲分析的人物名列表
roles_l = ['王陆','王舞','海云帆','风铃','琉璃仙','梁秋','朱秦','风吟','闻宝','王忠','海天阔','仙翁老人']将人物名加入jieba中,以免分词过程中割裂名字,造成误伤
import jieba
for role in roles_l:
jieba.add_word(role)提取人物出场频次
首先,读取爬虫得到的剧情文档
with open('剧情.txt','r',encoding='utf-8') as f:
fhwz_list = f.readlines()然后,对该内容进行清洗并分词
fhwz_fc_list = []
for rm_content in fhwz_list:
split_word =jieba.lcut(rm_content.replace('\n','').strip(''))
for i in split_word:
if len(i)>= 2:
fhwz_fc_list.append(i)
fhwz_fc_list得到分词后的列表
柱形图展示人物出场频次和顺序
首先,计算人物的出场频次
fhwz_dict = {}
for role in roles_l:
fhwz_dict[role] = fhwz_fc_list.count(role)使用bar()图可视化出来
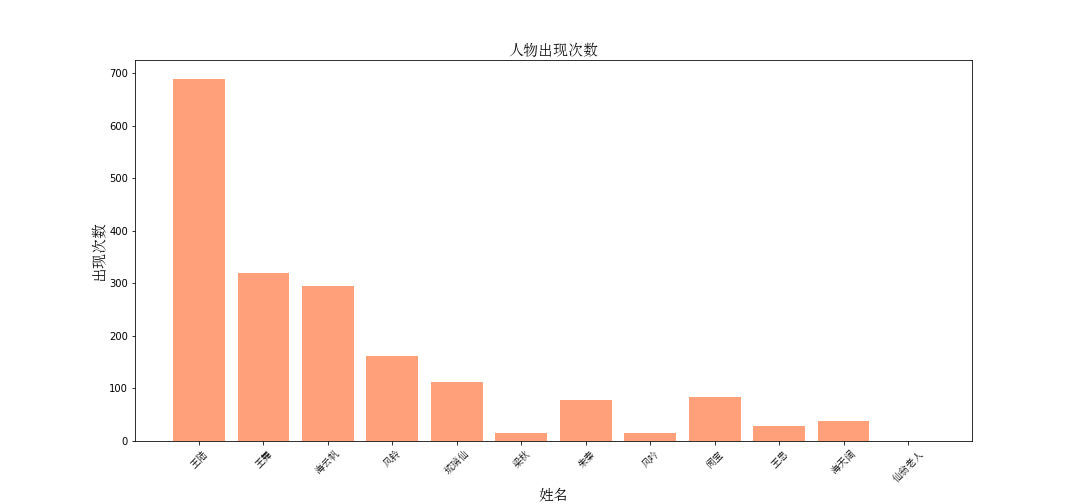
可以发现,张绍刚扮演的“仙翁老人”没怎么在剧情中出现过,戏份还是极少地,王陆出现这么多,说明这部剧很有可能是 “大男主” 电视剧。
计算人物的出场顺序。这里的以剧情的字数为单位,首次出现的字数越多,说明出场越晚。
# 人物出现顺序
order ={}
with open('剧情.txt','r',encoding='utf-8') as f:
str_fhwz = f.read()
print(str_fhwz.replace('\n',''))
for i in roles_l:
val = str_fhwz.find(i)
order[i]=val
order = sorted(order.items(), key=lambda order:order[1],reverse = False)
order=dict(order)使用barh()图可视化出来
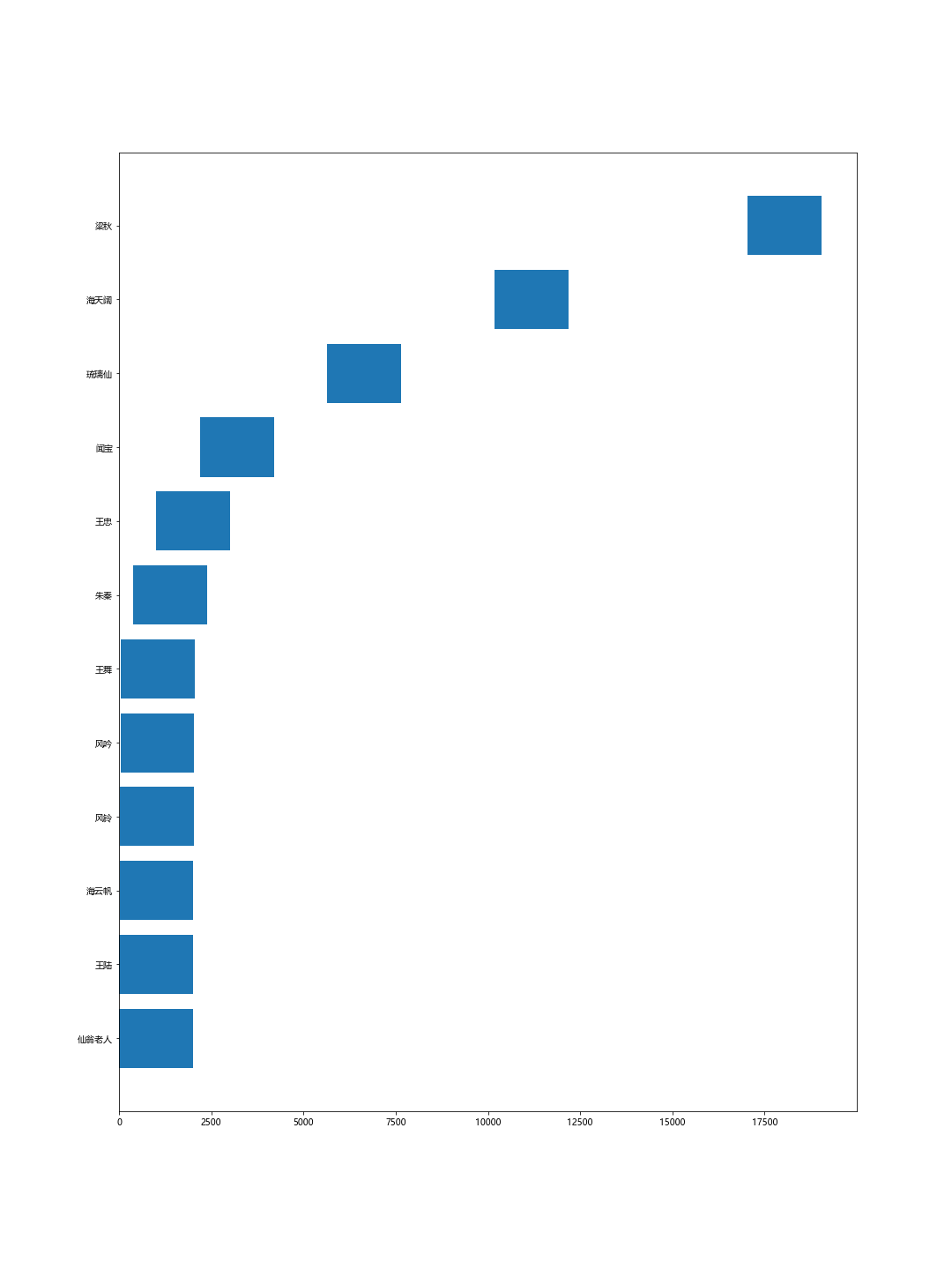
词云图展示整体情况
stylecloud可以下载个性图标为蒙版,制作有特色的词云图。数据猿这里使用mountain为图标。
import stylecloud
from PIL import Image
stylecloud.gen_stylecloud(
text=text,
palette='tableau.BlueRed_6', # 设置配色方案
icon_name='fas fa-mountain', # 设置蒙版方案
font_path="msyh.ttc")
Image.open("stylecloud.png")
当然,数据猿的审美不咋地,这个图标并不好看,想要更多好看图标,需访问如下地址
https://fa5.dashgame.com/#/%E5%9B%BE%E6%A0%87然后,复制图标名字,替换代码中的mountain即可。
icon_name='fas fa-mountain'了解更多stylecloud使用详情,访问如下地址
https://github.com/minimaxir/stylecloud小结:
相比于之前的爬虫代码,这次使用模块的思路来组合函数,使得两个函数都只实现一个功能,if __name__ == "__main__": 充分发挥作用,专职模块的输入和输出。
利用matplotlib和stylecloud库进行简单的可视化呈现,信息价值呈现的还不错,但审美和分析上还需要更加更加优化。


后台回复“入群”即可加入小z干货交流群

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









