









一、正则表达式
一个正则表达式,就是用某种模式去匹配一类字符串的一个公式。绝大部分是基于vi中的文本替换命令和grep文本搜索命令,还可以在sed、awk、perl等支持正则表达式的编程语言中使用。
规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表达一个模式。
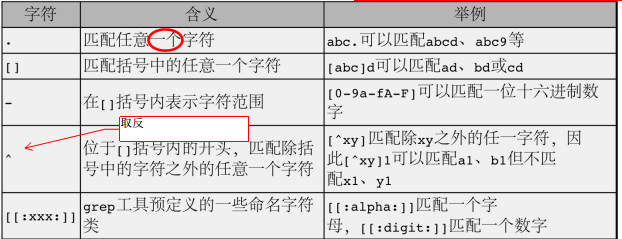
1、字符类:在模式中表示某个字符的取值范围是一类字符中任意一个。
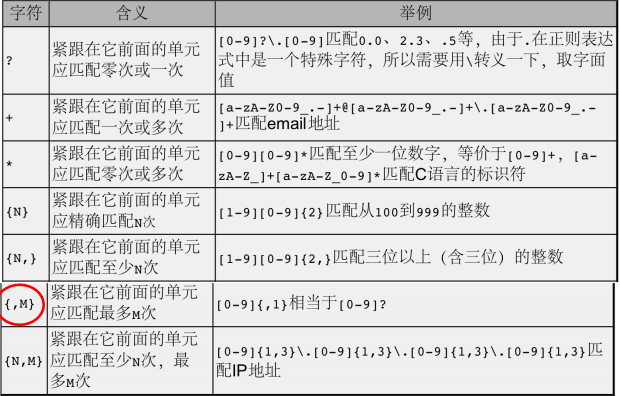
2、数量限定符:限定数量的个数。
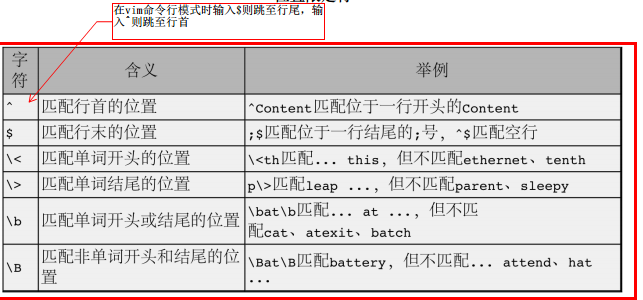
3、位置限定符:某个位置的字符限定出现。
*其他一些特殊字符
\ 转义字符,将普通字符转义为特殊字符,特殊字符转义为普通字符
( ) 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符
例: ([0-9]{1,3}\.){3}[0-9]{1,3} 匹配IP地址
| 连接两个子表达式,表示或的关系
二、grep
1、概述
GREP是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来,grep包含grep、egrep、fgrep。
egrep相当于grep -E ,表示采用extended正则表达式语法,grep的正则表达式有Basic和Extended两种规范,在basic规范下,字符?+ { } |()若不加转义字符表示普通字符,若要有特殊意义需要加转义字符\,若用grep而不是egrep,且不加-E,则应该遵照Basic规范
还有grep -F 也可以写成grep -F,表示只搜索固定字符而不搜索正则表达式模式,不会按正则表达式的语法解释后面的参数。
2、使用
当在grep中使用正则表达式时,要用单引号括起来,因为正则表达式中用到很多特殊字符在shell中也有特殊含义,例如\,只有用单引号括起来才能保证这些字符原封不动传给grep命令,不会被shell解释掉。
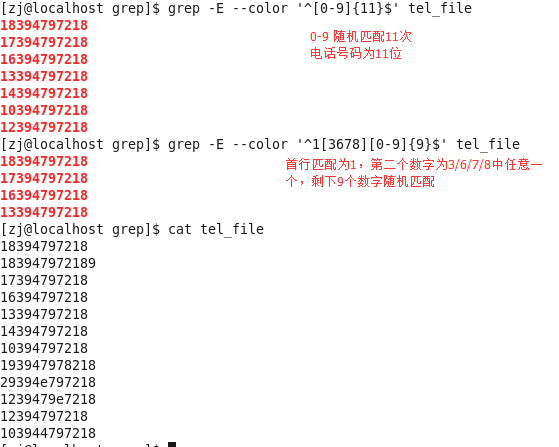
例子:

- 我们在上面可以看到,1492.168.1.1也被找出来,是因为grep找的是包含某一模式的行,这一行包含一个符合模式的字符492.168.1.1,而192.34168.1.1不包含符合模式的字符所以不会被找出来
例:

*跟在它前面的单元应匹配0次或多次

\<表示匹配单词开头的位置
\>表示单词结尾的位置

- 同样,对于一个163邮箱,为@163.com结尾
故:
grep -E --color '^[a-zA-Z0-9]+@163,com$' file
三、sed
1、基本概念
sed处理的文件即可以由标准输入重定向,也可以当命令行参数传入,命令行参数可以一次传入多个文件sed依次处理
sed编辑命令的格式为
/pattern/action
- 其中pattern为正则表达式,action为编辑操作,sed程序一行一行读出处理文件,若某一行与pattern匹配,则执行相应的action,若一条命令没有pattern而只有action,这个action将用作处理文件的每一行。
sed是一种在线编辑器,一次处理一行,处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区的内容,处理完成后把缓冲区的内容送往屏幕,继续下一行,不断重复,直到文件末尾。
文件内容不会改变,除非使用重定向存储输出。
注意:
sed默认按照Basic规范基本匹配
2、相关参数
- /pattern/p 打印
p命令时表示除了把文件内容打印出来之外还额外打印一遍匹配的pattern的行。 若指向输出处理结果,加上-n选项。
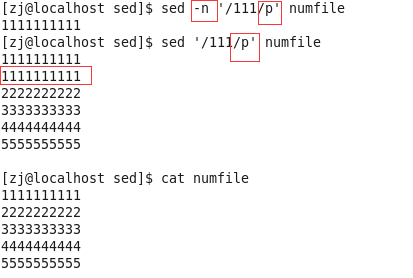
/pattern/d 删除匹配pattern的行

注意:d处理不会影响源文件内容,只表示不打印输出,但是加上-i选线则会删除源文件,慎用!!
- /pattern/s/pattern1/pattern2/ 查找符合pattern的行,将该行第一个匹配pattern1的字符串替换为pattern2
- /pattern/s/pattern1/pattern2/g 查找符合pattern的行,将该行所有匹配pattern1的字符串替换为pattern2

- 定址
决定对那些行进行编辑。地址的形式可以是数组、正则表达式、或二者的结合。若没有指定地址,sed处理输入文件的所有行。
sed -n '3p' file 打印第三行
sed -n '100,300p' file 打印100~300行(若地址用逗号分离,则需要处理的地址是这两行之间的范围)
sed '2,5d' file 删除2~5行
sed '/start/,/end/d' file 删除包含‘start’行和‘end’之间行
sed ‘/start/,10d’file 删除包含‘start’后10行的内容
3、命令和选项


4、用正则表达式
- 行首定位符^:
-
- sed -n '/^my/p' file 匹配所有以my开头的行
- 行尾定位符$
-
- sed -n '/my$/p' file 匹配所有以my结尾的行
- 匹配单个字符 .:
-
- sed -n '/m..y/p' file 包含m后跟两个任意字符再跟y的行
- 匹配零个或多个前导字符
-
- sed -n '/test*/p' file 匹配包含tes
- 匹配指定字符组内任意字符 [],在[]内加^表示不在指定字符组内任意字符
-
- sed -n '/t[eE]st/p' file 匹配test或tEst
- \<行首定位符
- \>行尾定位符
- x\{m\} 连续m个x
-
- /9\{5\}/ 包含5个9的行
- x\{m,\} 至少m个x
- x{m,n\} 至少m个,但是不超过n个x
5、模式空间与保持空间
sed在正常情况下,将处理的行读入模式空间,脚本中的sed命令就一条一条的处理,直到脚本处理完毕,然后输出,模式空间清空。
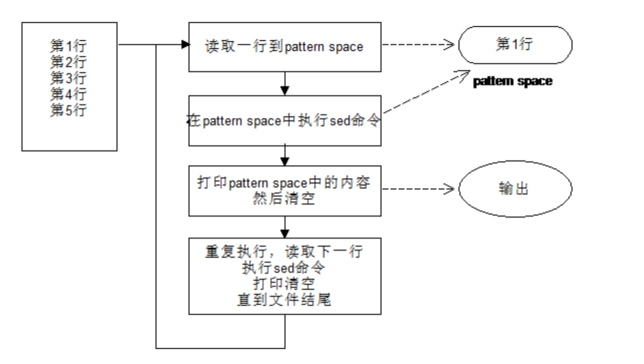
- 所有数据都需要在模式空间内处理
- 保持空间只对数据有保持功能
模式空间相当于流水线,数据直接在它上面处理。保持空间相当于仓库,在进行数据处理时,作为数据的暂存区域。一般只有在使用高级命令时才会用到保持空间。
用到保持空间的命令:
- +g 将保持空间中的内容拷贝到模式空间中,原来模式空间的内容清除
- +G 将保持空间中的内容追加到模式空间后
- +h 将模式空间的内容拷贝到保持空间中,原来保持模式空间的内容清除。
- +H 追加
- + d 删除模式空间中所有行,并读入下一行到模式空间中
- +D 删除multiline pattern中第一行,不读入
- +x 交换保持空间和模式空间的内容
- +N 将下一行添加到模式空间中
- +n 读取下一行到模式空间
例1、在每一行输入一个空行
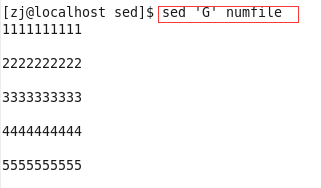
例2、求1-100和
















 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









