







最近在学习字符串这章,顺便学习了KMP算法和BM算法,简单的总结一下吧。
- KMP思想
KMP算法的思想说白了就是利用已知的信息去避免回溯.
这个刚开始不太容易理解就拿一般的朴素想法来说,如果让你找一段字符串里的一个子串,
可能不动脑子的想法就是两个循环一搭建,一个一个对比,匹配失败就从下一个元素开始。
比如说在**aabacabc**中返回子串**aca**的位置,朴素的算法就是
while(lenString && lenPattern){
if(string(i) == pattern(j)){i++; j++;}
else{i=i-j+1; j=0;}
}这种算法的时间复杂度很容易能看出来是平方阶,这是最差的情况,
也很少有文本匹配的模式是aaaaaaac中找aac这种。所以说不为了AC,就实用性来说也够用了。
朴素法耗费时间就耗费在如果已经文本已经匹配失败在模式的最后一个位置,
那么文本的指针就要回溯到这次匹配的下一个位置开始重新匹配。
而KMP就是利用了你已经知道了匹配失败前的字符了,设法利用已知条件不去回溯或者是减少不必要的回溯,
其时间复杂度往往为常数阶。
KMP算法是利用一个存储最长长度前后缀的匹配值去优化。
移动大小 = j - 上一个元素匹配值
本来想自己写例子,但是格式老对不齐,就用别人的吧。
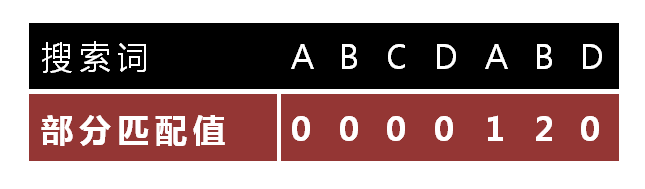

此时j=6, 而d的上一个元素b对应的匹配值为为2,移动4个元素

此时j=2,而c的上一个元素b对应的匹配值为0,移动2个元素
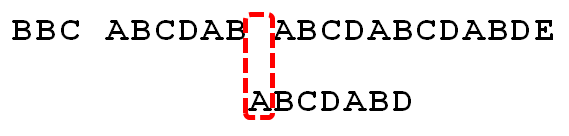
匹配到最后一个元素

此时j=6, 而d的上一个元素b对应的匹配值为为2,移动4个元素

然后就欧啦,~
2. KMP_next(1)
1 2 3 4 5 6 7
A B C D A B D
0 1 1 1 2 3 1
若 Tk == Tj, next[j] = next[k] +1
若 Tk != Tj, 继续比较Tj和T[next[k]]
int k = 0;
next[0] = 0;
for(i = 1, k = 0;i < len; i++){
while(k > 0 && a[i] != a[k]){ k = next[k-1];}
if(a[k] == a[i]){k++;}
next[i] = k;
}
3.KMP_nextval(2)
就是上面的匹配表
若 Tk == Tj, next[j+1] = next[j] +1
若 Tk != Tj, next[j+1] = next[k] +1
int j = 1, k = 0;
next[1] = 0;
while(j < len){
if(k == 0 || a[j] == a[k]){
j++; k++; next[j]=k;
}
else{ k = next[k]; }
}反正我会写了~~~
















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









