






数据类型
字符串定义:
有序的字符的集合。
字符串的特性:
str(索引) hello(01234)
可切片操作:
a = "hello,my name is smion."
print(a[3:6]) # 从3开始切 切到第六个位置 顾头不顾尾
lo, #结果
不可变,字符串是不可变的。
常用字符串类型:
.center(数量,“填充物”)
a="smion"
print(a.center(50,"-"))
----------------------smion-----------------------#结果
count 寻找
a="join smion"
print(a.count("i"))
print(a.count("i",0,4)) #默认全部,但是可以设置范围
查找开头与结尾
# endswitch 判断以何结尾
# startswitch 判断以何开头
a="join smion"
print(a.endswith("w")) #false
print(a.startswith("w")) #false
find 寻找模块
a="join smion"
print(a.find("t")) # 字符查找,返回-1代表没找到,找到了便返回索引数
判断整数
print("22".isdigit())
join 将列表里的值变成字符串
t = ["smion","gogo","talioo"]
print("".join(t))
smiongogotalioo # 输出
replace 替换
a="smoin"
a= a.replace("s","m") #默认是全部替换,但可以在后面标注多少
print(a)
mmion #结果
spilt 字符串变列表
print(a.split())
mmion #结果
列表list
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素。
特点:可以存放多个值,有顺序,可修改
name = [“smion”,“jojo”,“koko”,“aser”]
#追加 append append("")追加到最后
#插入 insert(位置,“插入内容”)
合并,可以把另一个列表的值合并进来
n1 = ["dog","cat","pig"]
name.extend(n1) # 将n1的值加到name中
print(name)
列表嵌套
n2 = [1,2,3]
name.insert(2,n2) # 将小列表插入大列表
print(name)
print(name[2][1]) # 从小列表中取第一个值
删除 del name[2]
name.pop() 默认删除最后一项,并返回这个值,想删除那个需要指定索引
remove(“”) 从左边开始删除第一个
清空 names.clear()
#修改操作,直接重新幅值
#查操作 name.index(“eva”)
#在一个列表中不知道一个元素在列表的那个位置的情况下如何修改
先判断在不在列表 in list ,取索引,去修改。
列表切片
names[start:end] # 从哪切到切到那为止,顾头不顾尾
names = ["smion","jojo","koko","lili"]
print(names[1:3]) # 顾头不顾尾,从1切到4
print(names[:3]) # 从0切到4 0可以省略
print(names[3:4])
# # 倒着切 从左往右
print(names[-4:-1])
步长 跳着切
print(names[0:-1:2]) # 最后设置步长 默认是1
a=[0,1,2,3,4,5,6,7,8,9]
print(a[::3]) # 按步长3打印整个列表,第1个:是省略的start:end
排序和反转
names.sort() # 按照 大写 小写 中文的顺序
a.reverse() # 列表的反转
# # 列表循环
for i in a:
print(a)
添加索引
for i in enumerate(names):
# print(i) # 列表添加索引 变为 元组
print(i[0]) # 打印索引
分组小程序练习
room = [["小赵", 34],["小王",92],["小钱",67],["小花",88],["小静",90],["小费",56]]
home = [
[] , # 100-90
[] , # 89-80
[] , # 79-70
[] , # 69-60
[] , # 59-0
]
for i in room:
if i[1] >= 90: #列表room中的第一个变量
home[0].append(i)
elif i[1] >= 80:
home[1].append(i)
elif i[1] >= 70:
home[2].append(i)
elif i[1] >= 60:
home[3].append(i)
else:
home[4].append(i)
# print(home)
for room in home:
print(room)
数据类型 dic

dic = {
"Alex":[23,"CEO",66000],
"黑姑娘":[24,"行政",4000],
"佩奇":[26,"讲师",40000]
}
print("佩奇" in dic) # 判断是否为true
不能以列表开头,不能重复,重复了新写入的会覆盖以前的值
字典打印
print(dic["佩奇"]) # 直接dic[]
字典增加
d = {}
d["name"]="smion"
d["age"]=22
d["hobby"]="money"
print(d)
删除操作
# 删除操作
d.pop("age") # 精确删除
del d["hobby"] # 通用删除
print(d)
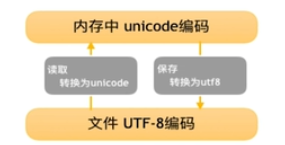
内存中是unicode,文件中是UTF-8。
 十六进制
十六进制
计算机靠电流驱动,降电压分为高电压与低电压,高电压为1,低电平为0
二进制 0与1,逢2进1,计算机的晶体管。
从二进制到英文字母 2–10–字母 ASCII码
ord(“0”) 打印0的ASCII码位置
计算机容量单位 8bit是一个字节
8 bit = 1bytes 字符是最小的表示单位
1kb = 1024b 字节是最小的存储单位
GB2312 一个中文两个字节
两个字节连在一块,若首位都是1,则是中文
GBK
解决各国乱码的措施:1,使用本国编码方式。2,安装别国的编码。3,万国码。Unicode
万国码有所有编码的对应位置。
在Unicode中一个英文字符占两个字节 所以使用UTF-8
快递分拣小程序
dict1 = {}
# 循环分拣
for i in list:
if '省' in i[1][:4]: # 判断前‘省’是否在列表地址前4位中,因为有黑龙江省,所以需要判断到前4位
a = i[1].index('省') # index 将第个‘省’字出现的索引值赋值给a
c = i[1][:a+1] # 把省字及前面的字赋值给c,因为顾头不顾尾,所以a+1
elif '市' in i[1][:4]: # 同上
a = i[1].index('市')
c = i[1][:a + 1]
else:
c = i[1][:2] # 剩下的就是特殊地区,只取2位。内蒙古懒得再分了,直接取内蒙
if c in dict1: # 判断c是否在字典中,已经存在就在后面添加
dict1[c].append(i)
else: # 不存在就新建一个
dict1[c] = []
dict1[c].append(i)
# 按照格式打印出来
print('{')
for j in dict1:
print(f'\t"{j}":[')
for k in dict1[j]:
print(f'\t\t{k},')
print(f'\t],')
print('}')















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









