







目录
列表是可变类型,元组是不可变类型
索引,切片和字符串一样

列表和元组解决的问题对比
列表解决可以改变数据的问题,eg.播放量、弹幕统计

元组解决定量问题,eg.春夏秋冬

列表和元组的性能对比
- 内存大小:list更占内存,因为list要存指针,要额外存储已经分配的长度大小
- 性能:tuple更快
总结:所以能用tuple的都用tuple
# 1. 存储空间测试 list更占内存
l = [1,2,3,4,5]
print(l.__sizeof__())
t = (1,2,3,4,5)
print(t.__sizeof__())
# 2. 运行效率测试 list慢
from timeit import timeit
print(timeit('l = [1,2,3,4,5]',number=100000000)) # 运行100000000次
print(timeit('t = (1,2,3,4,5)',number=100000000))
104
64
4.999734500000001
1.1413260420000002
一、3种列表增添元素方法
book = ['西游记', '水浒传']
# append 方法
book.append('三国演义') # append 追加在列表的后面
print(book)
# insert 方法
book.insert(0, '红楼梦')
print(book)
# extend 方法
kungfu = ['天龙八部', '笑傲江湖']
book.extend(kungfu)
print(book)
print(kungfu)
['西游记', '水浒传', '三国演义']
['红楼梦', '西游记', '水浒传', '三国演义']
['红楼梦', '西游记', '水浒传', '三国演义', '天龙八部', '笑傲江湖']
['天龙八部', '笑傲江湖']
二、修改列表方法
book[4] = '666'
print(book)
['红楼梦', '西游记', '水浒传', '三国演义', '666', '笑傲江湖']
三、4种查询列表方法
# in 和 not in
if '红楼梦' not in book:
print('红楼梦不在图书列表中')
else:
print('红楼梦在图书列表中')
# index
book.append('红楼梦')
print(book)
print(book.index('红楼梦'))
# count
print(book.count('红楼一梦'))
红楼梦在图书列表中
['红楼梦', '西游记', '水浒传', '三国演义', '射雕英雄传', '笑傲江湖', '红楼梦']
0
0
四、3种删除列表元素方法
# del 根据索引删除
del book[-1]
print(book)
# pop 删除最后一个元素
book.pop()
print(book)
# remove 删除指定元素,删除第一个匹配到的元素
book.append('水浒传')
print(book)
book.remove('水浒传')
print(book)
['红楼梦', '西游记', '水浒传', '三国演义', '666', '笑傲江湖']
['红楼梦', '西游记', '水浒传', '三国演义', '666']
['红楼梦', '西游记', '水浒传', '三国演义', '666', '水浒传']
['红楼梦', '西游记', '三国演义', '666', '水浒传']
五、2种列表排序方法
list_val = [23, 13, 56, 78, 90]
# sort 排序
list_val.sort()
print(list_val)
list_val.sort(reverse=True)
print(list_val)
# reverse 倒置
list_val.reverse()
print(list_val)
[13, 23, 56, 78, 90]
[90, 78, 56, 23, 13]
[13, 23, 56, 78, 90]
六、2种列表复制方法
l1 = [23, 13, 56, 78, 90]
# copy(), 浅拷贝, 重新建个一样的
l2 = l1.copy()
# 赋值, 地址拷贝, 指向同一块内存
l3 = l1
print(l2)
print(id(l1))
print(id(l2))
print(id(l3))
[23, 13, 56, 78, 90]
[23, 13, 56, 78, 90]
4446051072
4446058432
4446051072
七、4类列表推导式
# 1. 基本列表推导式
list_val = []
for i in range(1, 6):
list_val.append(i ** 2)
print(list_val)
new_list = [i ** 2 for i in range(1, 6)]
print(new_list)
word_list = ['I', 'love', 'Python']
print([i.upper() for i in word_list])
print([i.title() for i in word_list])
# 2. 过滤if条件
list_val = []
for i in range(21):
if i % 2 == 0:
list_val.append(i)
print(list_val)
new_list = [i for i in range(21) if i % 2 == 0]
print(new_list)
# 3. 过滤ifelse条件 (for 前面写ifelse)
names = ['AndyFung', 'JackMa', 'BillGates']
list_val = []
for i in names:
if len(i) < 8:
list_val.append(i.lower())
else:
list_val.append(i.upper())
print(list_val)
new_list = [i.lower() if len(i) < 8 else i.upper() for i in names]
print(new_list)
# 4. for 循环嵌套
list_val = []
for i in '高富帅':
for j in '白富美':
list_val.append(i+j)
print(list_val)
new_list = [i+j for i in '高富帅' for j in '白富美']
print(new_list)
[1, 4, 9, 16, 25]
[1, 4, 9, 16, 25]
['I', 'LOVE', 'PYTHON']
['I', 'Love', 'Python']
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
['ANDYFUNG', 'jackma', 'BILLGATES']
['ANDYFUNG', 'jackma', 'BILLGATES']
['高白', '高富', '高美', '富白', '富富', '富美', '帅白', '帅富', '帅美']
['高白', '高富', '高美', '富白', '富富', '富美', '帅白', '帅富', '帅美']
八、元组基本操作
# 创建元组
tuple_value = (1, 'hello', [1, 2, 3, 4, 5], (1, 2, 3, 4, 5))
empty_tuple = tuple()
tuple_1 = ('hi')
tuple_2 = ('hi',)
print(type(tuple_1))
print(type(tuple_2))
# 索引和切片
print(tuple_value[-1][1:3])
# 遍历
for i in tuple_value:
print(i)
# 不可变 和字符串一样
# tuple_value[0] = 2
# 常见操作
print(dir(tuple))
tuple_value = (1, 2, 'hello', [1, 2, 3, 4, 5], (1, 2, 3, 4, 5), 'hello')
print(tuple_value.count([1, 2, 3, 4, 5]))
print(tuple_value.count('hello'))
print(tuple_value.index('hello'))
<class 'str'>
<class 'tuple'>
(2, 3)
1
hello
[1, 2, 3, 4, 5]
(1, 2, 3, 4, 5)
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index']
1
2
2
九、元组拆包
info = ('Andy', 'man', 18)
name, gender, age = ('Andy', 'man', 18)
print(name)
print(gender)
print(age)
# 使用占位符
_, _, age = ('Andy', 'man', 18)
print(age)
# 元素较多
a, b, *rest, c, d = range(10)
print(a)
print(b)
print(rest)
print(c)
print(d)
# 快速交换
num1 = 10
num2 = 5
num1, num2 = num2, num1
print(num1)
print(num2)
Andy
man
18
18
0
1
[2, 3, 4, 5, 6, 7]
8
9
5
10
地址拷贝 – 指向一个地址,跟着变
newlist = 列表
浅拷贝 – 子对象指向一个地址,子对象仍跟着变
from copy import copy
newlist = copy(列表)
newlist = 列表[:]
newlist = 列表.copy()
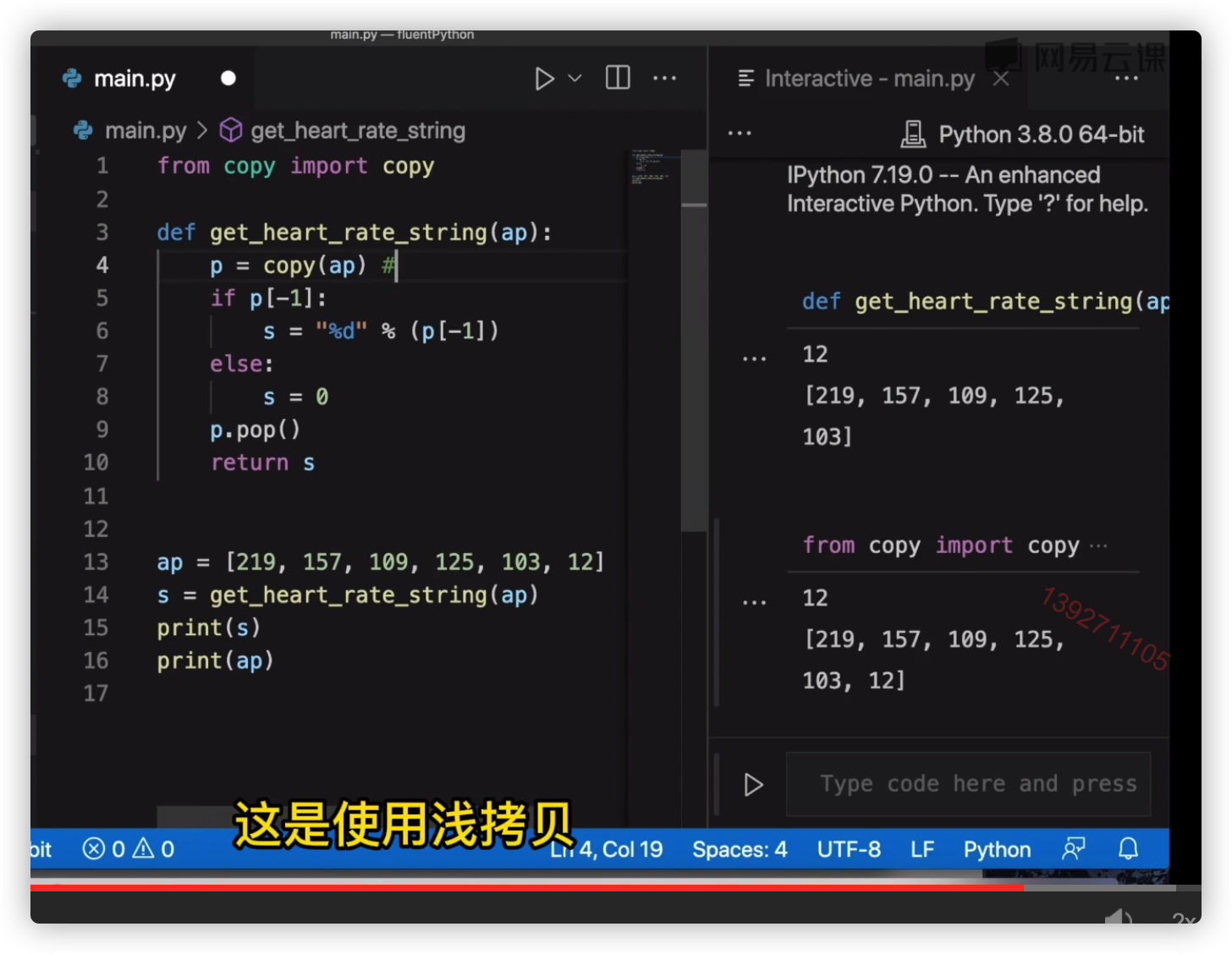
深拷贝 – 不跟着变,独立!
from copy import deepcopy
newlist = deepcopy(列表)
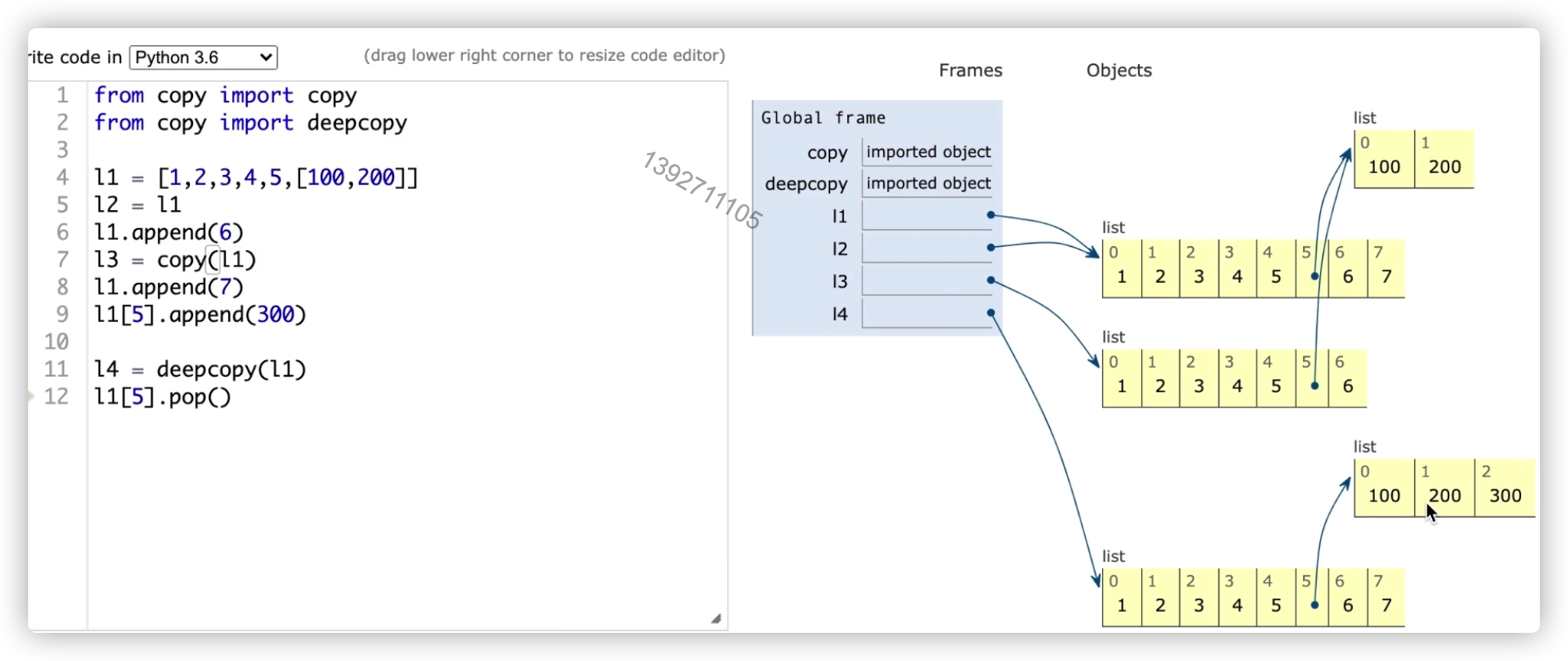
【注意】浅拷贝时,如果存在可变类型数据,那会发生变化
深拷贝,拷贝父对象和子对象
浅拷贝,只拷贝父对象


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











