






我选择欧氏距离作为测量本函数库中两点之间距离的方法,但这不是唯一的方法,您可以选用若干种方法,诸如直线距离和曼哈顿距离,在此之前的文章中曾讨论过一些。

添加图片注释,不超过 140 字(可选)
Print("Euclidean distance vector\n",euc_dist); 输出 -----------> CS 0 19:29:09.057 TestScript Euclidean distance vector CS 0 19:29:09.057 TestScript [6.7082,13,13.41641,7.61577,8.24621,4.12311,1.41421,3,2]
现在,赫兹量化交易软件将欧氏距离嵌入到矩阵的最后一列:
if (isdebug) { matrix dbgMatrix = Matrix; //temporary debug matrix dbgMatrix.Resize(dbgMatrix.Rows(),dbgMatrix.Cols()+1); dbgMatrix.Col(euc_dist,dbgMatrix.Cols()-1); Print("Matrix w Euclidean Distance\n",dbgMatrix); ZeroMemory(dbgMatrix); }
输出:
CS 0 19:33:48.862 TestScript Matrix w Euclidean Distance CS 0 19:33:48.862 TestScript [[51,167,1,6.7082] CS 0 19:33:48.862 TestScript [62,182,0,13] CS 0 19:33:48.862 TestScript [69,176,0,13.41641] CS 0 19:33:48.862 TestScript [64,173,0,7.61577] CS 0 19:33:48.862 TestScript [65,172,0,8.24621] CS 0 19:33:48.862 TestScript [56,174,1,4.12311] CS 0 19:33:48.862 TestScript [58,169,0,1.41421] CS 0 19:33:48.862 TestScript [57,173,0,3] CS 0 19:33:48.862 TestScript [55,170,0,2]]
我把这个数据放在一个便于解释的图像:
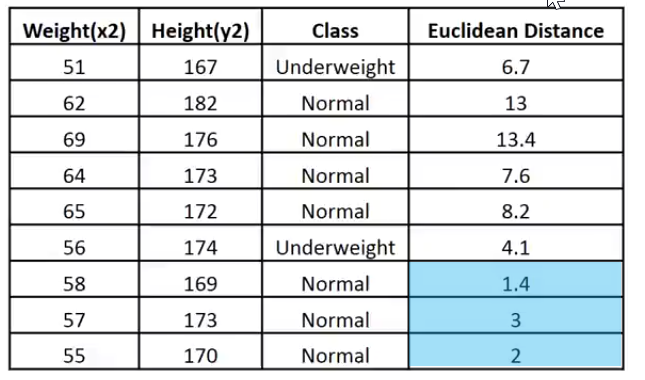
添加图片注释,不超过 140 字(可选)
给定的 k 值为 3,3 个最近邻都属于 Normal 类,赫兹量化交易软件知道给定的点落在 Normal 类别,现在我们的代码能为此作出决策。
为了能够判定最近邻,并追踪它们,使用矢量将非常困难。 数组可以更灵活地进行分片和重塑。 我们就用它们令该过程圆满完成。
int size = (int)m_target.Size(); double tarArr[]; ArrayResize(tarArr, size); double eucArray[]; ArrayResize(eucArray, size); for(ulong i=0; i<m_target.Size(); i++) //convert the vectors to array { tarArr[i] = m_target[i]; eucArray[i] = euc_dist[i]; } double track[], NN[]; ArrayCopy(track, tarArr); int max; for(int i=0; i<(int)m_target.Size(); i++) { if(ArraySize(track) > (int)k) { max = ArrayMaximum(eucArray); ArrayRemove(eucArray, max, 1); ArrayRemove(track, max, 1); } } ArrayCopy(NN, eucArray); Print("NN "); ArrayPrint(NN); Print("Track "); ArrayPrint(track);
在上面的代码模块上,我们判定最近邻,并将它们存储在 NN 数组当中,我们还跟踪它们的类值/该类的目标值在全局向量中所处位置。 最重要的是,我们需删除数组中的最大值,最后我们只保留 k 的较小值数组(最近邻)。
下面是输出:
CS 0 05:40:33.825 TestScript NN CS 0 05:40:33.825 TestScript 1.4 3.0 2.0 CS 0 05:40:33.825 TestScript Track CS 0 05:40:33.825 TestScript 0.0 0.0 0.0
投票过程:
//--- Voting process vector votes(m_classesVector.Size()); for(ulong i=0; i<votes.Size(); i++) { int count = 0; for(ulong j=0; j<track.Size(); j++) { if(m_classesVector[i] == track[j]) count++; } votes[i] = (double)count; if(votes.Sum() == k) //all members have voted break; } Print("votes ", votes);
输出:
2022.10.31 05:40:33.825 TestScript votes [0,3]
投票向量根据数据集中可用类的全局向量排列投票,还记得吗?
2022.10.31 06:43:30.095 TestScript classes vector | Neighbors [1,0]
现在,这告诉我们,在投票选出的 3 个邻居中,有 3 个投票认为给定的数据属于 zeros(0) 类,并且没有成员投票给 Ones(1) 类。
我们看看如果选择 5 个邻居投票会发生什么,即 K 值为 5。
CS 0 06:43:30.095 TestScript NN CS 0 06:43:30.095 TestScript 6.7 4.1 1.4 3.0 2.0 CS 0 06:43:30.095 TestScript Track CS 0 06:43:30.095 TestScript 1.0 1.0 0.0 0.0 0.0 CS 0 06:43:30.095 TestScript votes [2,3]
现在最终的决定就很容易了,在这种情况下票数最高的类赢得决定,给定的权重属于编码为 0 的正常类。
if(isdebug) Print(vector_, " belongs to class ", (int)m_classesVector[votes.ArgMax()]);
输出:
2022.10.31 06:43:30.095 TestScript [57,170] belongs to class 0
很棒,现在一切工作正常,我们将 KNNAlgorithm 的类型从 void 更改为 int,令其返回给定值所属类的值,这可能会在实时交易中派上用场,因为我们将插入新值,期望算法立即将其输出。
int KNNAlgorithm(vector &vector_);
测试模型并判定其准确性。
现在我们已有了模型,就像任何其它监督机器学习技术一样,我们必须训练它,且测试过程需基于之前从未见过的数据上,这将有助于我们理解我们的模型在不同数据集上的表现。
float TrainTest(double train_size=0.7)
默认情况下,数据集的 70% 用来训练,而其余 30% 则用来测试。
我们需要为切分数据集的函数编码,从而能分阶段训练,以及分阶段测试:
^//--- Split the matrix matrix default_Matrix = Matrix; int train = (int)MathCeil(m_rows*train_size), test = (int)MathFloor(m_rows*(1-train_size)); if (isdebug) printf("Train %d test %d",train,test); matrix TrainMatrix(train,m_cols), TestMatrix(test,m_cols); int train_index = 0, test_index =0; //--- for (ulong r=0; r<Matrix.Rows(); r++) { if ((int)r < train) { TrainMatrix.Row(Matrix.Row(r),train_index); train_index++; } else { TestMatrix.Row(Matrix.Row(r),test_index); test_index++; } } if (isdebug) Print("TrainMatrix\n",TrainMatrix,"\nTestMatrix\n",TestMatrix);
输出:
CS 0 09:51:45.136 TestScript TrainMatrix CS 0 09:51:45.136 TestScript [[51,167,1] CS 0 09:51:45.136 TestScript [62,182,0] CS 0 09:51:45.136 TestScript [69,176,0] CS 0 09:51:45.136 TestScript [64,173,0] CS 0 09:51:45.136 TestScript [65,172,0] CS 0 09:51:45.136 TestScript [56,174,1] CS 0 09:51:45.136 TestScript [58,169,0]] CS 0 09:51:45.136 TestScript TestMatrix CS 0 09:51:45.136 TestScript [[57,173,0] CS 0 09:51:45.136 TestScript [55,170,0]]
故此,最近邻算法的训练非常简单,您可能会认为根本未经训练,因为如早前所述,该算法本身不会尝试理解数据集中的形态,这与逻辑回归或 SVM 等方法不同,它只是在训练期间存储数据,然后取这些数据用于测试目的。















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









