






KNN是什么
给定一个待预测样本,找到已知样本中离它最近的k个,根据这k个的标签情况对该待预测样本进行分类或者回归。
k的选择
较小的k容易过拟合,较大的k容易都到不相关的数据点的干扰。所以k的选择可以按照如下方法:
1.最朴素的想法:大的数据集就稍微选大的k,小数据集选较小的k;
2.交叉验证法:将数据集分成若干子集,在每个子集中进行KNN,用不同的k值进行测试,最后选择最合适的k;
3.可视化分析判断。
KNN算法的距离度量方式
欧氏距离
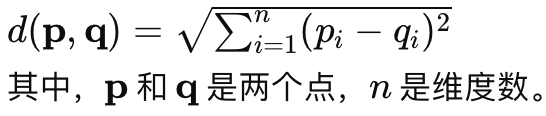
曼哈顿距离
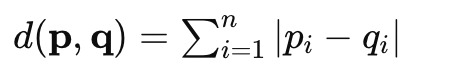
切比雪夫距离
![]()
马氏距离
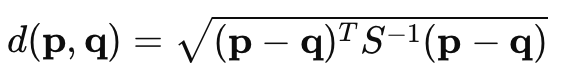
KNN的局限性
KNN巨简单,但是局限性也很显著:
1.每个训练数据都保存,对内存要求大
2.每次都要计算待测数据和所有数据的距离,计算量巨大;
3.对类别不平衡的问题极为敏感;
4.对噪声数据点也很敏感;
5.特征空间高维情况下,数据点稀疏,以距离为指标的数据相关性判断并不一定准确。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









