






1. 任务
使用Flask将Selenium脚本服务器化,将Selenium辅助脚本作为一个单独的服务在另外一台设备上部署,与其余的Java后端分开。
2. 实验环境
- 编程语言: Python 3.x
- Web 框架: Flask
- 浏览器自动化工具: Selenium
- 浏览器驱动: ChromeDriver
- 依赖库:
flaskseleniumwebdriver_managerre
3. 实验步骤
3.1 安装依赖
使用pip安装必要的工具库:
pip install flask selenium webdriver-manager
3.2 配置 Flask 应用
编写代码,测试Flask是否成功运行:
from flask import Flask, request, jsonify
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import re
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
在命令行中运行:
python -m flask run
访问localhost:5000得到结果,运行成功:
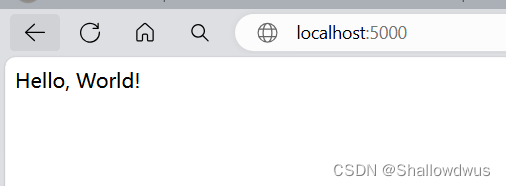
3.3 改写Selenium脚本
实现一个 /search 路由,接收 GET 请求,提取关键词参数,然后使用 Selenium 在指定的几个网站上进行搜索,并返回符合条件的链接和标题。
-
接收关键词参数:
@app.route('/search', methods=['GET']) def search(): keyword = request.args.get('keyword', '') if not keyword: return jsonify({"error": "Keyword parameter is required"}), 400 -
抓取链接和标题:
定义
links_and_titles = [],在过滤后将标题和链接加入其中,最后以JSON格式返回。遍历每个 URL,抓取页面中的所有链接元素,并根据过滤条件筛选有效结果:
links_and_titles = [] keywords_to_filter = [...] # 需要过滤的关键词列表 domains_to_filter = ['space.bilibili'] # 需要过滤的域名列表 for url in urls: driver.get(url) link_elements = driver.find_elements(By.TAG_NAME, 'a') for element in link_elements: try: link = element.get_attribute('href') title = element.text except Exception as e: print(e) continue if not link or not title: continue title = title.strip().replace('\n', '') contains_keyword = True for keyword1 in keywords_to_filter: if keyword1 in title: contains_keyword = False break for keyword1 in domains_to_filter: if keyword1 in link: contains_keyword = False break if contains_keyword and re.search('[\u4e00-\u9fff]', title): links_and_titles.append((link, title)) driver.quit() return jsonify(links_and_titles)
4. 测试
启动 Flask 应用并测试搜索功能:
python -m flask run
在浏览器中访问 http://localhost:5000/search?keyword=山东大学,验证返回的 JSON 数据包含符合条件的链接和标题。
得到数组类型的Json代码:
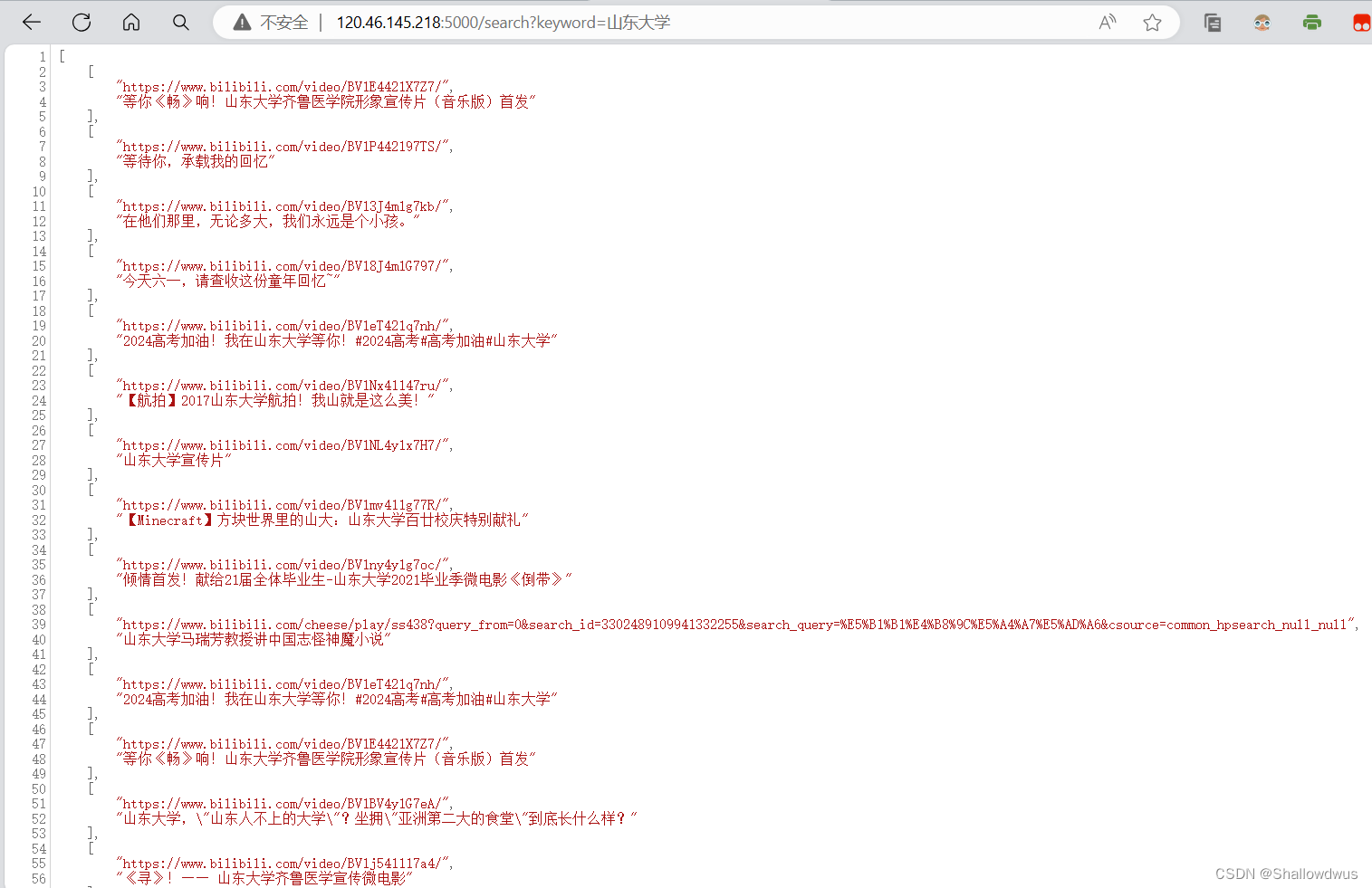
这样的JSON数组可以在格式化后简单的提取,达到跨设备访问服务的效果。
5. Mock接口
直接调用search接口,设备需要调用selenium现场爬取网页,大概用时需要五分钟,不方便后端同学调用接口进行开发。新增一个Mock接口,传输数据。
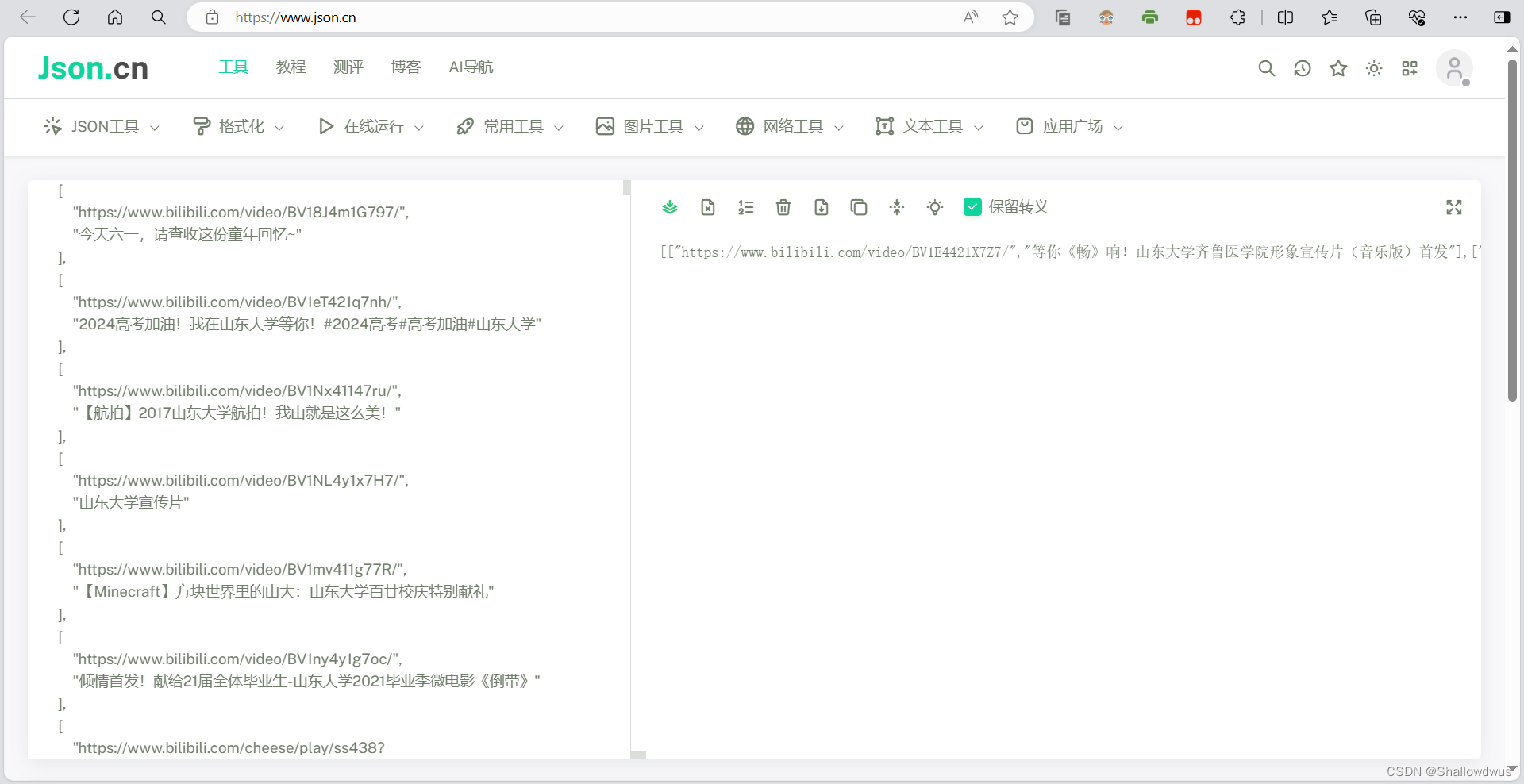
将数据压缩为一行,编写Mock接口:
@app.route('/mock')
def mock():
return '[["https://www.bilibili.com/video/BV1E4421X7...(粘贴上面一行)';
访问http://localhost:5000/mock,得到:
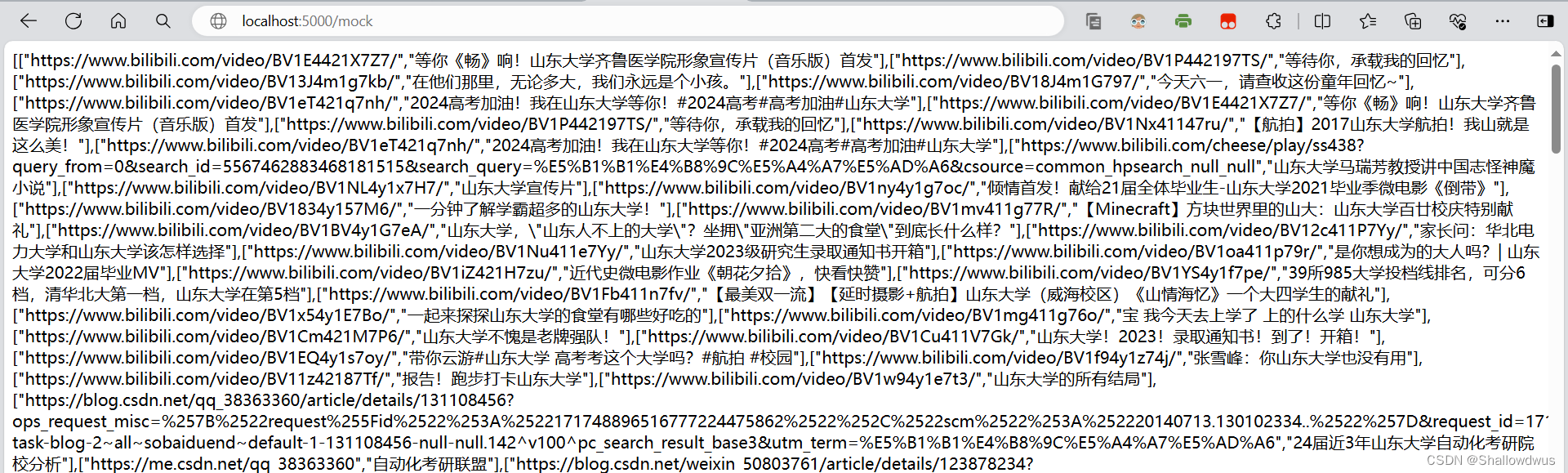
s://www.bilibili.com/video/BV1E4421X7…(粘贴上面一行)';
访问`http://localhost:5000/mock`,得到:
[外链图片转存中...(img-rtGGgZG7-1719127945159)]
便于后端的继续开发。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









