







Kafka是什么
Kafka我们了解一直认为是一个消息队列,但是其设计初,是一个:分布式流式处理平台。流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
- 消息队列:建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 大吞吐量流式数据处理: 构建实时的流数据处理程序来转换或处理数据流。
Kafka支持的俩种模型:
- 队列模型:使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半。
- 订阅模型(Pub-Sub) 使用主题(Topic) 作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者,在一条消息广播之后才订阅的用户则是收不到该条消息的。
核心概念
Producer、Consumer、Broker、Topic、Partition,我们一一介绍。
Kafka 将生产者发布的消息发送到 Topic(主题) 中,需要这些消息的消费者可以订阅这些 Topic(主题),如下图所示:
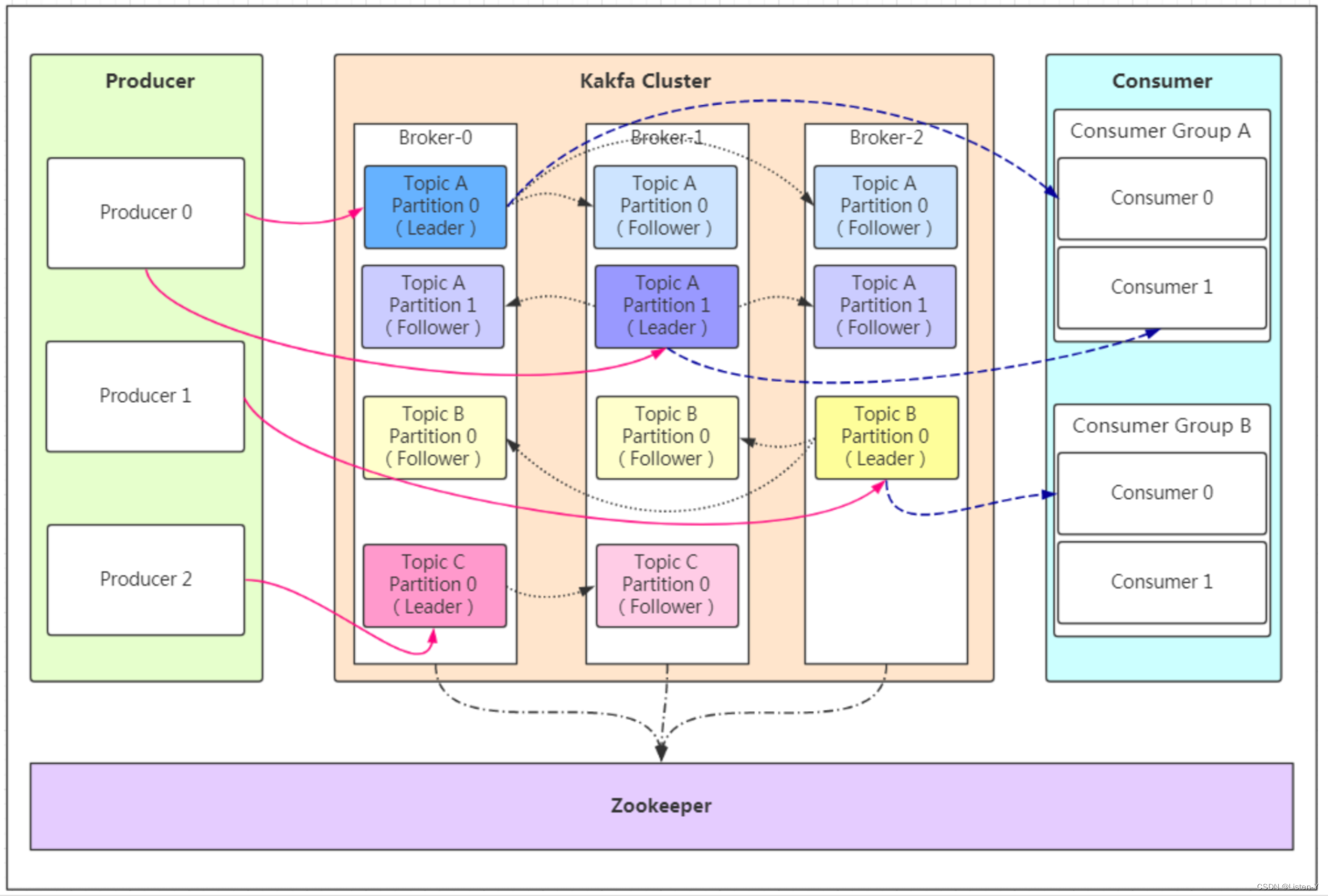
- 生产者(Producer)::生产者负责将消息发布到Kafka集群中的一个或多个主题(Topic),每个Topic包含一个或多个分区(Partition)
- Consumer(消费者) : 消费者负责从Kafka集群中的一个或多个主题消费消息,并将消费的偏移量(Offset)提交
回Kafka以保证消息的顺序性和一致性。 - Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
Leader Broker:Leader Broker 是分区的主副本,它是负责处理消息读写请求的节点。生产者将消息发送到Leader Broker,消费者从 Leader Broker中拉取消息。
Follower Broker:Follower Broker 是 Leader Broker的备份节点,它负责与Leader Broker进行数据同步,以保持自己的数据与 Leader Broker保持一致。
-
Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
-
Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。
-
Kafka Cluster(集群):在集群中,每个分区都有一个Leader Broker和多个Followeer Broker,只有Leader Broker才能处理生产者和消费者的请求,而Follower Broker只是LeaderBroker的为备份,用于提供数据的冗余备份和容错能力。如果Leader Broker发生故障,Kafka集群会自动将Follower Broker提升为新的 Leader Broker,从而实现高可用性和容错能力。
-
Zookeeper:ZooKeeper是Kafka集群中使用的分布式协调服务,用于维护Kafka集群的状态和元数据信息,例如
主题和分区的分配信息、消费者组和消费者偏移量等。
多分区、多副本
上文说道, Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
生产者和消费者只与 leader 交互。你可以理解为其他副本只是 leader 的拷贝,它们的存在只是为了保证消息存储的安全性。
当 leader 发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?
Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
Zookeeper的作用
ZooKeeper 主要为 Kafka 提供元数据的管理和集群节点协调的功能。
Zookeeper 主要为 Kafka 做了下面这些事情:
- Broker 注册:在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 /brokers/ids 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去。
- Topic 注册:在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1
- 负载均衡:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
工作原理
生产者发送的消息经过序列化后,相同主题和分区的消息,会被存放在同⼀个批次⾥,然后由⼀个独⽴的线程负责,从Zookeeper拿到信息,通过不同的分区策略,找到对应的分区,把它们发到 Kafka Broker 上。
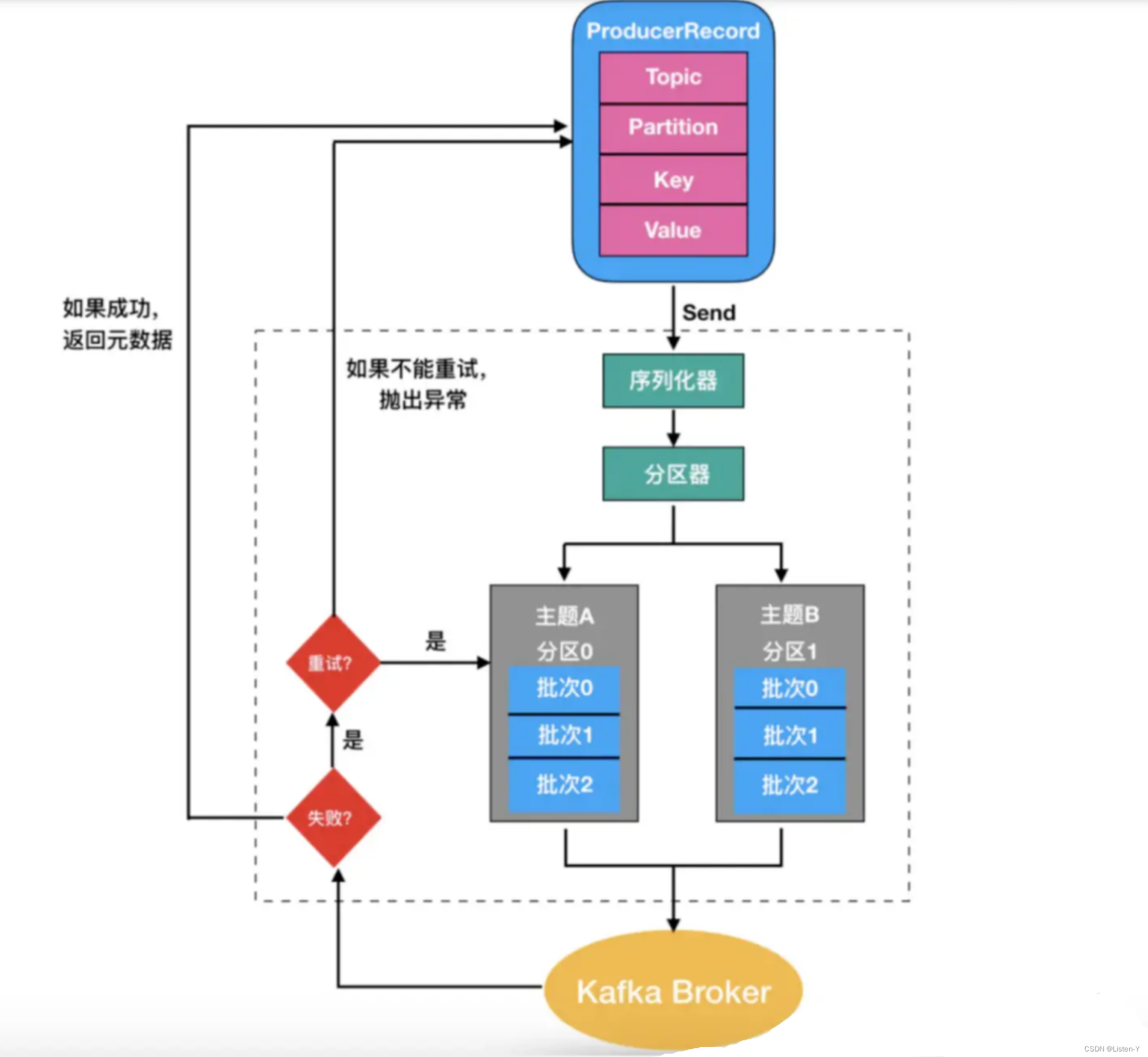
分区的策略包括顺序轮询、随机轮询和 key hash 这 3 种⽅式。
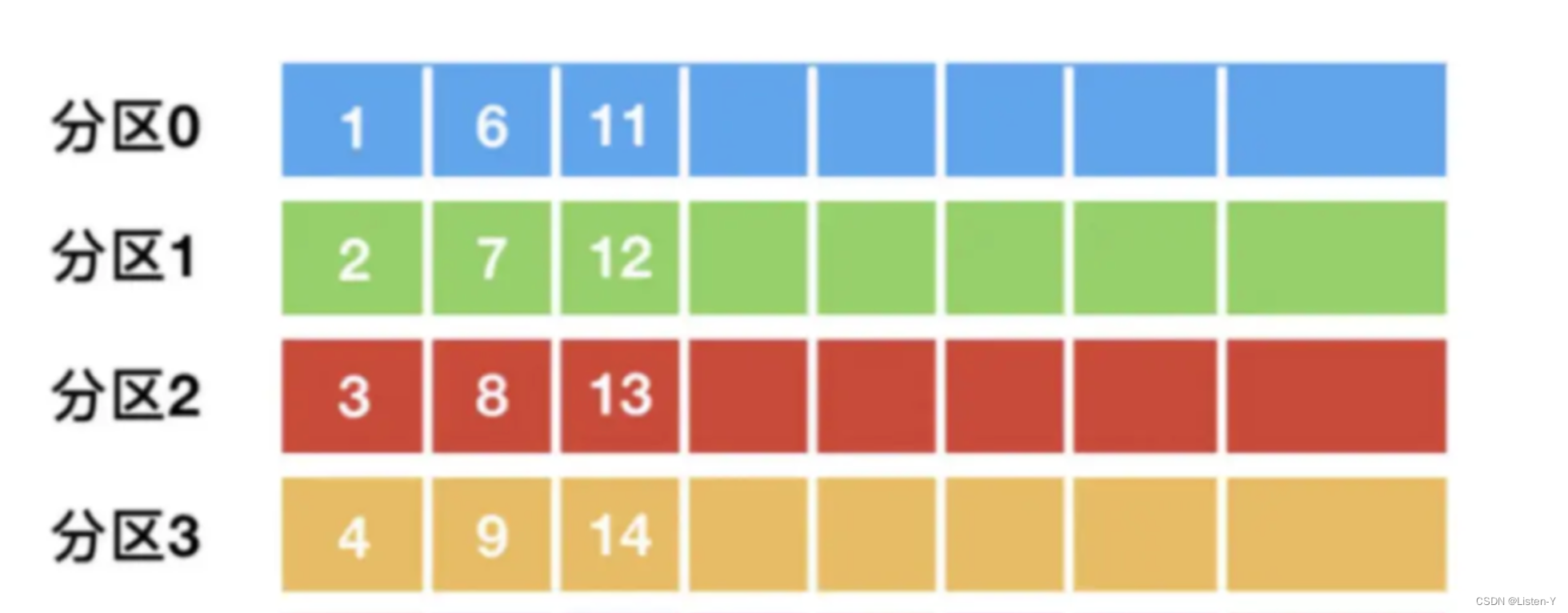
⽐如主题 A 有 12 条消息,有 4个分区,如果采⽤顺序轮询的⽅式,152条消 息会顺序分配给这 4
个分区,后续消费的时候,也是按照分区粒度消费。
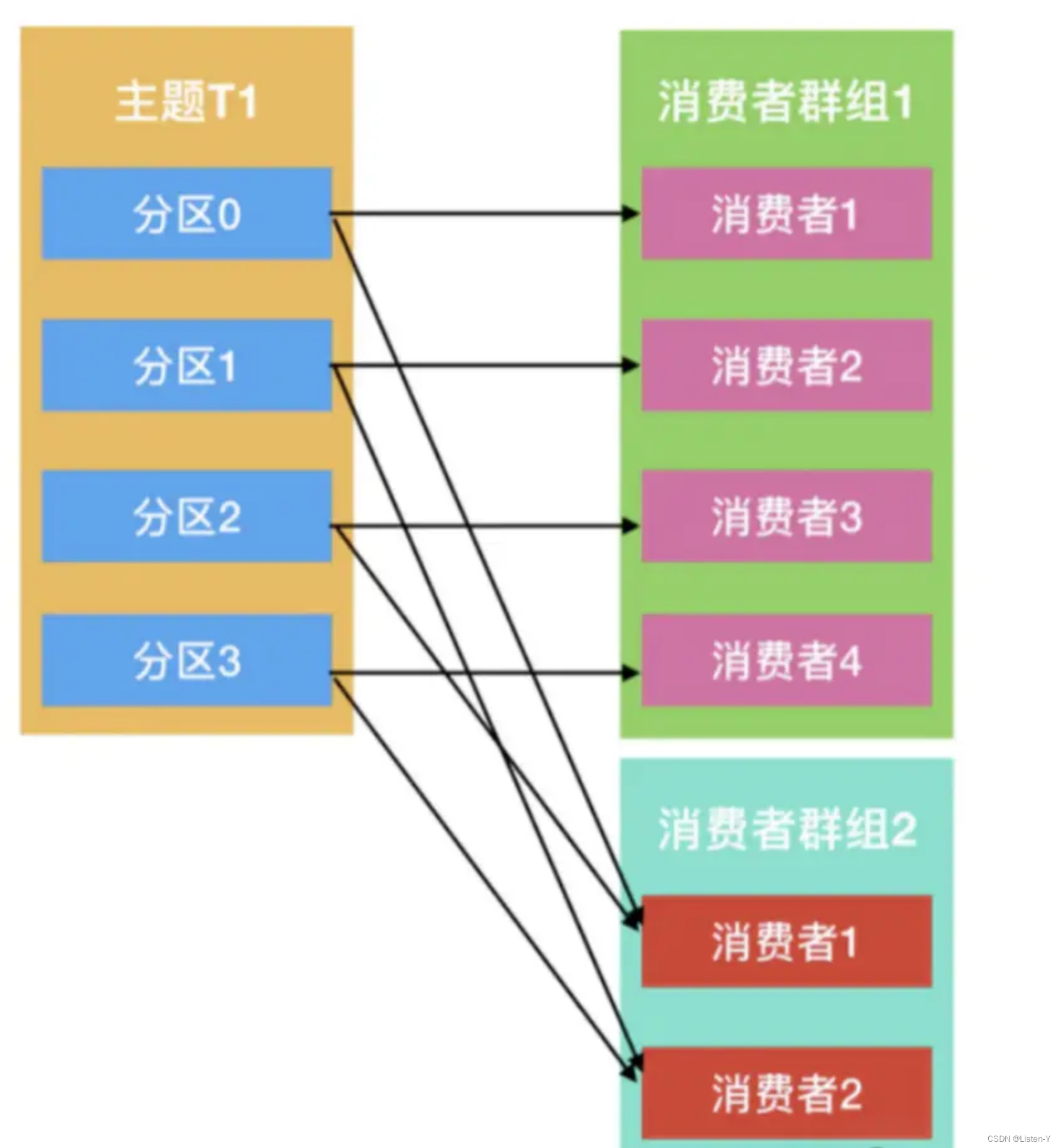
Kafka 消费是通过消费群组完成,同⼀个消费者群组,⼀个消费者可以消费多个分区,但是⼀个分区,只能被⼀个 消费者消费。
分区与消费者的关系是n:1
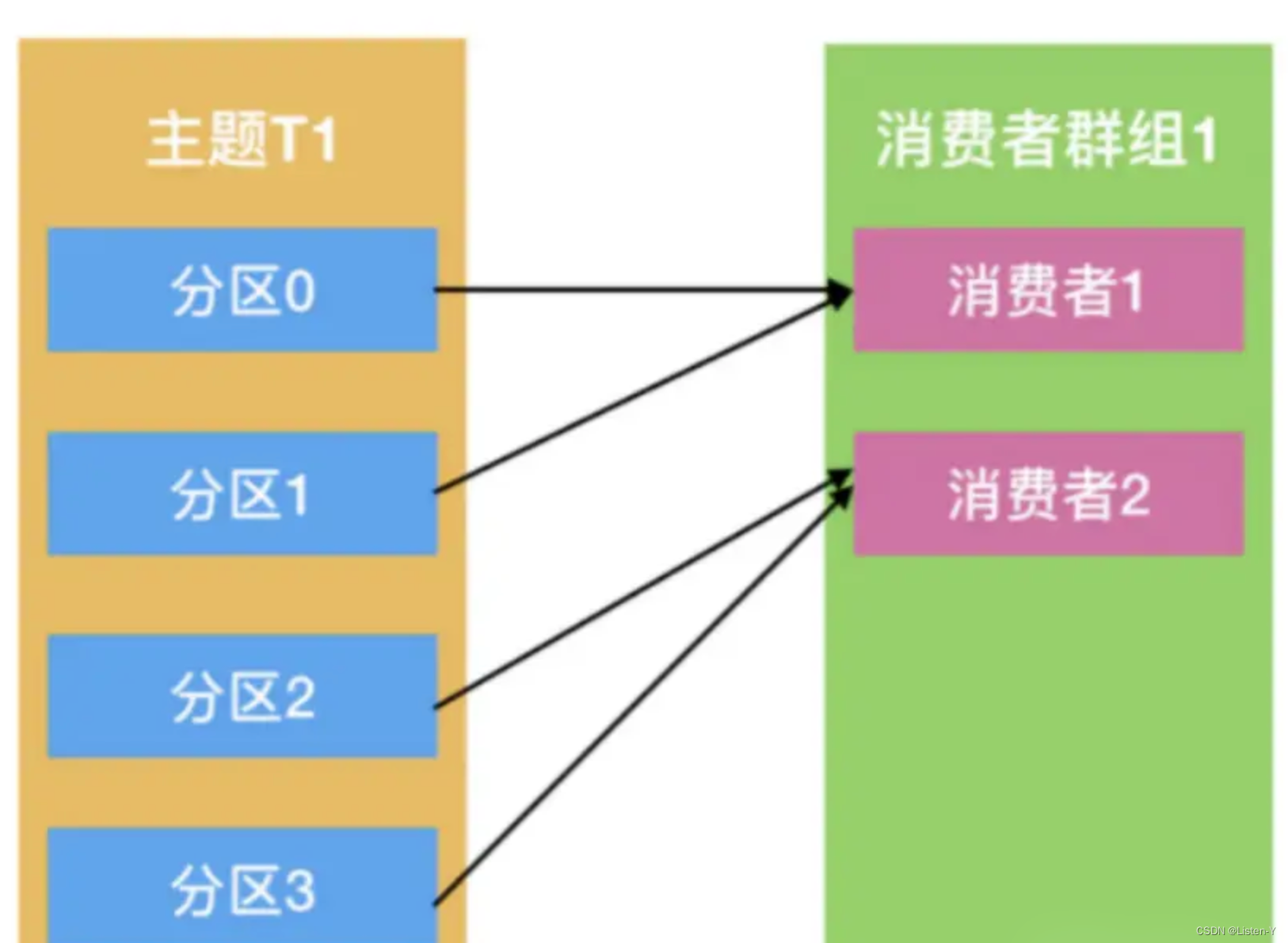
如果消费者增加,会触发 Rebalance,也就是分区和消费者需要重新配对。
不同的消费群组互不⼲涉,⽐如下图的 2 个消费群组,可以分别消费这 4 个分区的消息,互不影响。















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









