






在业务系统越来越复杂的今天,用户对系统的运行性能越来越重视,需要对系统运行中的相关指标进行监控,实时获取监控指标信息,对相关问题进行监控预警,并结合业务分析定位出现的异常。我们知道 APM(应用性能监控)是通过对系统可观察性数据进行采集、存储和分析,进行系统的性能监控与诊断,主要功能包括性能指标监控、调用链分析,应用拓扑图等。一般通过 Metrics(指标监控)、Tracing(链路跟踪)、和 Logging(日志)的手段来获取系统运行状况的相关性能数据。本篇就为大家讲解 ShardingSphere-Agent 如何采集 ShardingSphere-JDBC 监控指标,以及怎样进行可视化展示。
实现原理
在进行指标采集时,一般会想到如下两种办法。一种是手动在业务方法内进行埋点,另一种是利用 Java Agent 技术做无侵入埋点。第一种方法在业务方法内进行埋点对业务侵入性太强,在业务中包含非业务逻辑不是一个好的选择。
所以,一般都是选择使用 Java Agent 技术进行无侵入埋点采集。依赖 Java Agent 技术,修改目标方法字节码进行数据采集也叫探针技术。ShardingSphere-Agent 就是采用的 Java Agent 技术,在 JVM 启动时添加一个 agent 代理,使用 Byte Buddy 修改目标字节码,织入数据采集逻辑。
模块介绍
shardingsphere-agent-api
定义增强接口、插件配置等
shardingsphere-agent-core
定义插件加载流程 和 agent 入口定义
shardingsphere-agent-plugins
插件定义
本篇主要介绍 shardingsphere-agent-plugins 模块下的指标插件部分。在 shardingsphere-agent-plugins 模块下指标插件主要有如下模块:
指标采集定义模块
shardingsphere-agent-metrics-core
指标数据暴露模块
shardingsphere-agent-metrics-prometheus
埋点设置
一般指标埋点需要考虑在有意义的地方,进行埋点。比如 ShardingSphere-JDBC 中常用并且最重要的莫过于 ShardingSphereStatement、ShardingSpherePreparedStatement 两个类。我们会经常使用两个类的 execute、executeQuery、executeUpdate 方法执行 SQL,所以这些方法也是我们最应该关注的地方,也就可以在这些方法进行相关指标的采集。比如可以统计这些方法的执行耗时,执行次数等。
以目前已有的指标:
jdbc_statement_execute_latency_millis 为例,该指标会对 ShardingSphereStatement 和 ShardingSpherePreparedStatement 的 execute、executeQuery、executeUpdate 方法进行拦截增强,统计方法执行耗时。
指标说明
ShardingSphere-JDBC 监控指标
ShardingSphere-Agent 采集的指标符合 OpenMetrics 标准。如下是指标说明。
指标名称 | 类型 | 说明 |
build_info | GAUGE | 构建信息 |
jdbc_meta_data_info | GAUGE | 元数据信息 |
parsed_sql_total | COUNTER | 按类型(INSERT、UPDATE、DELETE、SELECT、DDL、DCL、DAL、TCL)分类的解析总数 |
routed_sql_total | COUNTER | 按类型(INSERT、UPDATE、DELETE、SELECT)分类的路由总数 |
routed_result_total | COUNTER | 路由结果总数(数据源路由结果、表路由结果) |
jdbc_statement_execute_total | COUNTER | 语句执行总数 |
jdbc_statement_execute_errors_total | COUNTER | 语句执行异常总数 |
jdbc_transactions_total | COUNTER | 事务总数,按 commit,rollback 分类 |
jdbc_statement_execute_latency_millis | HISTOGRAM | 语句执行耗时 |
JVM 监控指标
ShardingSphere-Agent 会附带暴露 JVM 运行时的相关指标,指标说明如下。
指标名称 | 类型 | 描述 | 备注 |
jvm_threads_current | GAUGE | JVM 当前线程数 | |
jvm_threads_daemon | GAUGE | JVM 后台线程数 | |
jvm_threads_peak | GAUGE | JVM 峰值线程数 | |
jvm_threads_deadlocked | GAUGE | JVM 死锁线程数 | |
jvm_threads_state | GAUGE | NEW | NEW 状态的线程数 |
RUNNABLE | RUNNABLE 状态的线程数 | ||
WAITING | WAITING 状态的线程数 | ||
TIMED_WAITING | TIMED_WAITING 状态的线程数 | ||
BLOCKED | BLOCKED 状态的线程数 | ||
TERMINATED | TERMINATED 状态的线程数 | ||
jvm_memory_bytes_max | GAUGE | heap | 可分配最大堆内存字节数 |
nonheap | 无限制 | ||
jvm_memory_bytes_committed | GAUGE | heap | 已分配堆内存大小字节数 |
nonheap | 非堆内存已分配大小 | ||
jvm_memory_bytes_used | GAUGE | heap | 已使用堆内存大小 |
nonheap | 已使用非堆内存大小 | ||
jvm_memory_bytes_init | GAUGE | heap | 初始分配堆内存大小 |
nonheap | 初始分配非对内存大小 |
指标类型说明:
✅ GAUGE 类型的指标表示指标值可以增加也可以减少。
✅ COUNTER 类型的指标值只会增加,不会减少。
✅ HISTOGRAM 类型的指标代表的直方图类型,主要用于指标值的分布情况,比如统计方法耗时分布情况。
使用指南
已集成了 ShardingSphere-JDBC 的 SpringBoot 项目为例
准备 spring-boot-shardingsphere-jdbc-test.jar 集成参考[1]
获取 ShardingSphere-Agent,可在[2]下载
注意: 从 5.3.2 版本开始支持。ShardingSphere-JDBC 和 ShardingSphere-Agent 需要版本一致。
agent 包目录结构如下
cd agent
tree
├── LICENSE
├── NOTICE
├── conf
│ └── agent.yaml
├── plugins
│ ├── lib
│ │ ├── shardingsphere-agent-metrics-core-${latest.release.version}.jar
│ │ └── shardingsphere-agent-plugin-core-${latest.release.version}.jar
│ ├── logging
│ │ └── shardingsphere-agent-logging-file-${latest.release.version}.jar
│ ├── metrics
│ │ └── shardingsphere-agent-metrics-prometheus-${latest.release.version}.jar
│ └── tracing
│ ├── shardingsphere-agent-tracing-opentelemetry-${latest.release.version}.jar
└── shardingsphere-agent-${latest.release.version}.jar配置 agent.yaml 文件开启监控
plugins:
metrics:
Prometheus:
host: "localhost"
port: 39090
props:
jvm-information-collector-enabled: "true"
配置说明:
host 代表在本机暴露指标的 IP 地址, 默认为 localhost
port 代表暴露指标的端口
jvm-information-collector-enabled 代表是否收集 JVM 相关指标信息,默认是 true
启动项目
java -javaagent:${agentPath}/agent/shardingsphere-agent-${latest.release.version}.jar -jar spring-boot-shardingsphere-jdbc-test.jar
说明: javaagent 后面需配置 jar 文件的绝对路径。
项目启动后,对项目中的相关业务接口进行请求以触发相关埋点以产生指标数据。接下来,访问本地暴露指标数据的端口 http://127.0.0.1:39090 即可获取数据信息。下面是部分指标截图。
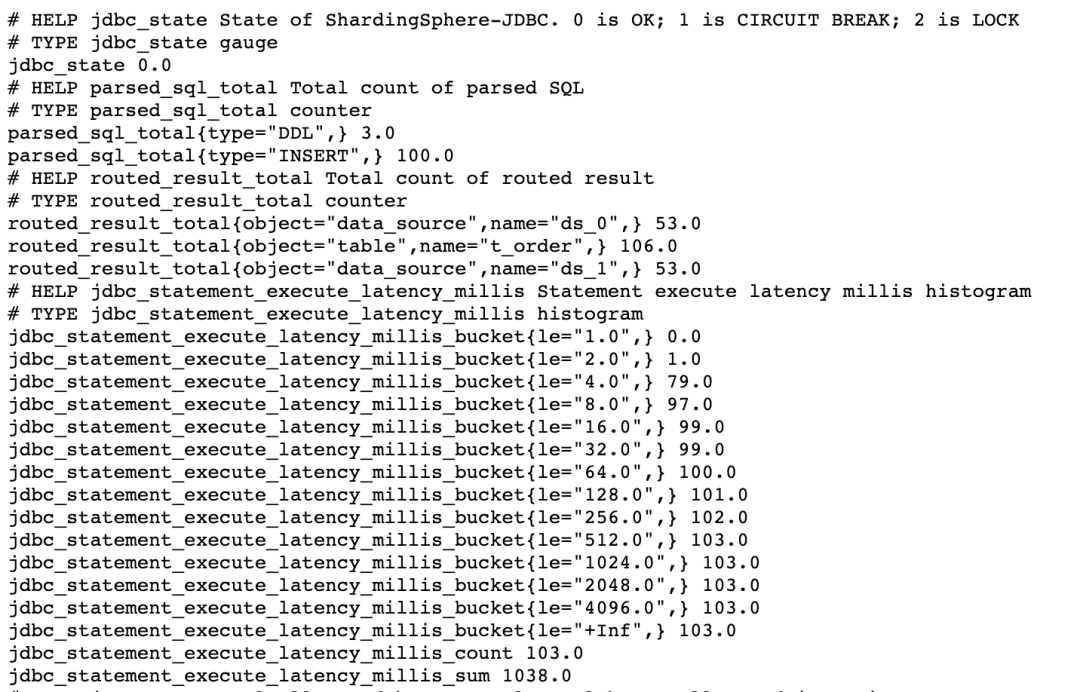
特殊说明:
jdbc_statement_execute_latency_millis_bucket、jdbc_statement_execute_latency_millis_count、jdbc_statement_execute_latency_millis_sum 是由 jdbc_statement_execute_latency_millis 指标衍生而来。
按照指标规范,在产生 HISTOGRAM 类型的指标时,会自动生成带 _bucket、_count、_sum 后缀的指标。后面会介绍怎么样使用。
以上展示的是 ShardingSphere-Agent 暴露的原始指标值,在生产应用中,我们往往需要使用 Prometheus 进行指标采集、存储并通过 Grafana 进行可视化展示。接下来我们进行 Prometheus 和 Grafana 的配置。
Prometheus
在 prometheus.yml 文件中,添加对应配置,采集监控数据。Prometheus 的详细使用参考 Prometheus 官网[3]
scrape_configs:
- job_name: "jdbc"
static_configs:
- targets: ["127.0.0.1:39090"]Grafana
在 Grafana 中设置 Prometheus 数据源(Grafana 使用参考[4]),编写 PromSQL 实现自己关注的指标数据(PromSQL 参考[5])。以 jdbc_statement_execute_total 指标为例,可以展示出平均每分钟内执行 SQL 条数。如下所示表示平均每分钟内 SQL 语句执行条数。
rate(jdbc_statement_execute_total{instance=~'192.168.65.2:39090'}[1m])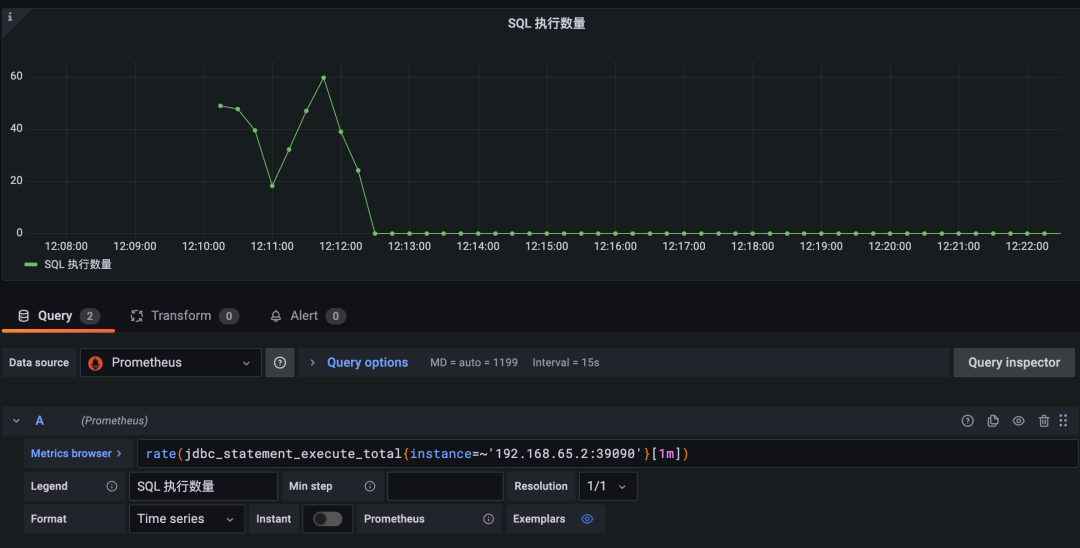
当我们需要查看路由到后端数据库的 SQL 指标时,我们可以使用 routed_sql_total 指标进行展示。该指标使用 type 标签对 INSERT、UPDATE、DELETE、SELECT 类型的 SQL 分别统计,这样更方便我们查看不同类型的 SQL 统计。
rate(routed_sql_total{instance=~'192.168.65.2:39090'}[1m])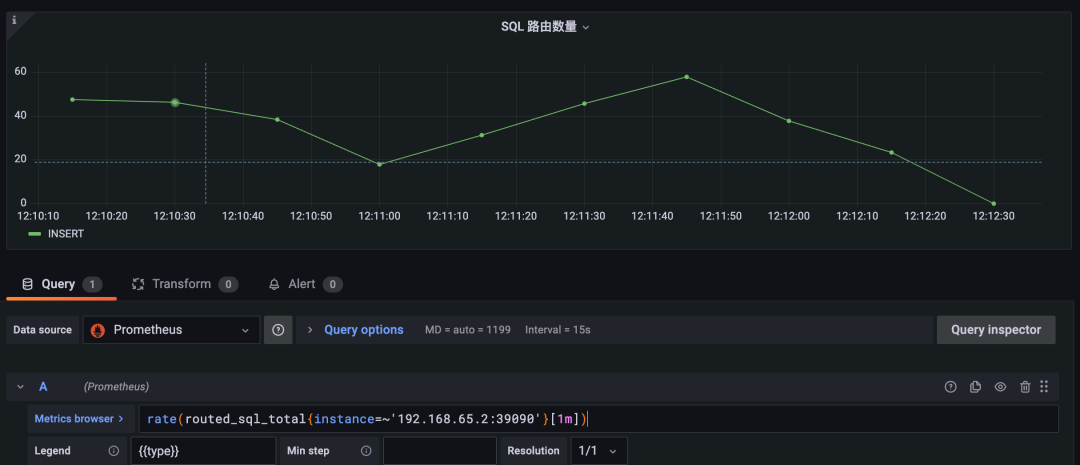
其他 COUNTER 类型的指标可以通过类似的 PromSQL 获取到对应的监控,在此就不一一举例,可自行尝试。
很多时候我们比较关心执行 SQL 时的耗时,此时 jdbc_statement_execute_latency_millis 指标就正好是我们需要的。原始指标暴露格式和含义说明如下。
# HELP jdbc_statement_execute_latency_millis Statement execute latency millis histogram
# TYPE jdbc_statement_execute_latency_millis histogram
jdbc_statement_execute_latency_millis_bucket{le="1.0",} 0.0
jdbc_statement_execute_latency_millis_bucket{le="2.0",} 898.0
jdbc_statement_execute_latency_millis_bucket{le="4.0",} 5065.0
jdbc_statement_execute_latency_millis_bucket{le="8.0",} 5291.0
jdbc_statement_execute_latency_millis_bucket{le="16.0",} 5319.0
jdbc_statement_execute_latency_millis_bucket{le="32.0",} 5365.0
jdbc_statement_execute_latency_millis_bucket{le="64.0",} 5404.0
jdbc_statement_execute_latency_millis_bucket{le="128.0",} 5405.0
jdbc_statement_execute_latency_millis_bucket{le="256.0",} 5458.0
jdbc_statement_execute_latency_millis_bucket{le="512.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="1024.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="2048.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="4096.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="+Inf",} 5459.0
jdbc_statement_execute_latency_millis_count 5459.0
jdbc_statement_execute_latency_millis_sum 27828.0jdbc_statement_execute_latency_millis_bucket{le="1.0",} 0.0 表示执行耗时在 1 毫秒内的次数,此处表示 0 次。
jdbc_statement_execute_latency_millis_bucket{le="2.0",} 898.0 表示执行耗时在 2 毫秒内的次数,此处表示有 898 次。
jdbc_statement_execute_latency_millis_bucket{le="4.0",} 5065.0 表示执行耗时在 4 毫秒内的次数,此处表示有 5065 次。其他的以此类推。
其中 "+Inf" 表示对超过最大耗时的统计,此处表示超过 4096 毫秒的统计。jdbc_statement_execute_latency_millis_count 5459.0 表示总共累计执行次数, 此处表示总共执行了 5459 次。
jdbc_statement_execute_latency_millis_sum 27828.0 表示总共累计执行耗时,此处表示 27828 毫秒。
jdbc_statement_execute_latency_millis_bucket 通过这个指标,我们可以编写 PromSQL 在 Grafana 中使用热力图展示出执行耗时的分布情况,PromSQL 和效果如下。
ceil(sum(increase(jdbc_statement_execute_latency_millis_bucket{instance=~'192.168.65.2:39090', le!='+Inf'}[1m])) by (le))
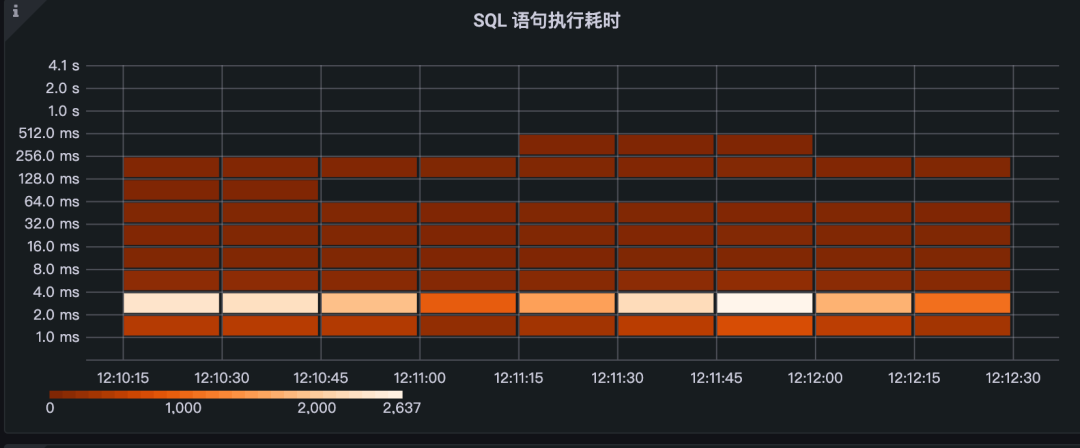
通过热力图可以看出,执行耗时主要集中在 2~4 毫秒内,和原始指标数据反应的结果一致。其他相关指标用户可自行尝试编写 PromSQL 进行体验。
结语
欢迎社区的同学积极参与进来,丰富完善 ShardingSphere-JDBC 的监控指标。有任何疑问或者建议欢迎在 GitHub issue 列表 [6] 提出,或可前往中文社区 [7] 交流讨论。
🔗 参考如下:
[1] ShardingSphere-JDBC 官网文档:
https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/
[2] ShardingSphere-Agent 下载地址:
https://shardingsphere.apache.org/document/current/cn/downloads/
[3] Prometheus 官网地址:
https://prometheus.io/
[4] Grafana 地址:
https://grafana.com/
[5] PromSQL 文档:
https://prometheus.io/docs/prometheus/latest/querying/basics/
[6] GitHub issue 列表:
https://github.com/apache/shardingsphere/issues
[7] 中文社区:
https://community.sphere-ex.com/














 2442
2442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









