









Spark装载CSV数据源
- 文件预览
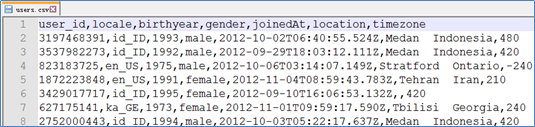
-
使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.csv") val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(",")) val fields = lines.filter(l=>l.startsWith("user_id")==false).map(l=>l.split(",")) //移除首行,效果与上一行相同
装载JSON数据源
正常json文件
- 文件预览
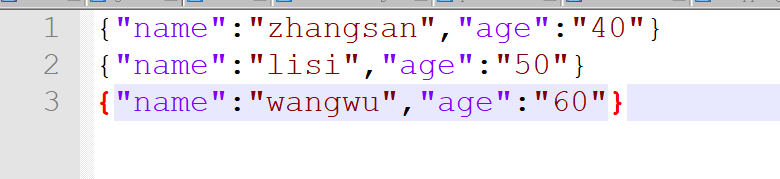
- 代码加载
val frame = spark.read.format("json").load("D:\\study files\\Spark\\test\\test.json")
frame.show()

部分包含json文件
- 文件预览

- 代码实现
val txt = spark.sparkContext.textFile("D:\\study files\\Spark\\test\\test.log")
val frame = txt.map(_.split(" ")).map(x=>(x(0),x(1),x(2),x(3))).toDF("no","action","info","times")
frame.show()

关于算子get_json_object的使用:(将数据转为二维表)
val txt = spark.sparkContext.textFile("D:\\study files\\Spark\\test\\test.log")
val frame = txt.map(_.split(" ")).map(x=>(x(0),x(1),x(2),x(3))).toDF("no","action","info","times")
frame.select($"no",$"action",
get_json_object($"info","$.name").as("name"),
get_json_object($"info","$.age").as("age"),$"times"
).show()















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









