









机器学习导论
| 有监督学习 | 无监督学习 |
|---|---|
| 有因变量、特征向量 | 无因变量、有特征向量、寻找数据中的结构 |
| 预测 | 回归、分类 |
| 决策树、朴素贝叶斯、逻辑回归 | PCA、层次聚类 |
| 输入数据有标签 | 不需要给数据打标签 |
练习
使用scikit-learn(简称sklearn工具库)探索机器学习项目。
回归
回归问题多用来预测一个具体的数值,如预测房价、未来的天气情况等等。例如我们根据一个地区的若干年的PM2.5数值变化来估计某一天该地区的PM2.5值大小,预测值与当天实际数值大小越接近,回归分析算法的可信度越高。
回归问题的目标是给定D维输入变量x,并且每一个输入矢量x都有对应的值y,要求对于新来的数据预测它对应的连续的目标值t。
- 任务:预测波士顿房价Price
- 数据源:sklearn内置Boston房价数据集。
1.导入相关的库
# 引入相关科学计算包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use("ggplot")
import seaborn as sns
sklearn中所有内置数据集都封装在datasets对象内
-
data:特征X的矩阵(ndarray)
-
target:因变量的向量(ndarray)
-
feature_names:特征名称(ndarray)
from sklearn import datasets #数据
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
boston_data.head()#查看数据
#可视化
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6)
plt.title("Price~NOX")
plt.show()
运行结果:
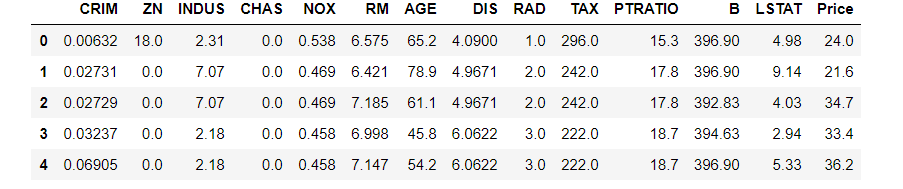 CRIM:各城镇人均犯罪率
CRIM:各城镇人均犯罪率
ZN:规划地段超过25,000平方英尺的住宅用地比例
INDUS:城镇非零售商业用地比例
CHAS:是否在查尔斯河边(1,0)
NOX:一氧化氮浓度(/千万分之一)
RM:每个住宅的平均房间数
AGE:1940年以前建造的自住房屋的比例
DIS:到波士顿五个就业中心的加权距离
RAD:放射状公路的可达性指数
TAX:全部价值的房产税率(每1万美元)
PTRATIO:按城镇分配的学生与教师比例
B:1000(Bk - 0.63)^2其中Bk是每个城镇的黑人比例
LSTAT:较低地位人口
Price:房价

分类
分类是一种基于一个或多个自变量确定因变量所属类别的技术。
鸢尾花分类
from sklearn import datasets#导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(X,columns=features)
iris_data['target'] = y
iris_data.head()
# 可视化特征
marker = ['s','x','o']
for index,c in enumerate(np.unique(y)):
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()
运行结果:


- sepal length (cm):花萼长度(厘米)
- sepal width (cm):花萼宽度(厘米)
- petal length (cm):花瓣长度(厘米)
- petal width (cm):花瓣宽度(厘米)
无监督学习
# 生成月牙型非凸集
from sklearn import datasets
x, y = datasets.make_moons(n_samples=2000, shuffle=True,
noise=0.05, random_state=None)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c,0],x[y==c,1],s=7)
plt.show()

# 生成符合正态分布的聚类数据
from sklearn import datasets
x, y = datasets.make_blobs(n_samples=5000, n_features=2, centers=3)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c, 0], x[y==c, 1],s=7)
plt.show()

参考资料
https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









