







什么是模式分解?
关系模式R<U, F>的一个分解是指:={
<
,
>, ... ,
<
,
>},其中
=
...
,并且
,1
i,j
n,
是
在
上的投影。相应地将R储存在二维表r中的数据分散到二维表
,
,... ,
中去,其中
是属性r在属性集
上的投影。
把低一级的关系模式分解为若干个高一级的关系模式,分解方法并不是唯一的,在这些分解方法中,只有能够保证分解后的关系模式与原关系模式等价的方法才有意义。在这里,对于“等价”有以下3种不同的定义:
- 分解具有无损连接性
- 分解要保持函数依赖
- 分解既要保持函数依赖,又要具有无损连结性
这三个定义是实行模式分解的三条准则。
下面通过一个例子讲解什么是模型分解。
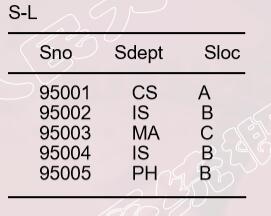
对于一个有关学生的关系模式S-L(SNo, Sdept, Sloc),关系S-L如图所示:

其中SNo属性代表学生证号,Sdept属性代表所属院系,Sloc属性代表院系地址,S-L中有以下函数依赖:
SNo→Sdept
SNo→Sloc
SdeptSloc
已知S-L2NF,该关系模式存在着非主属性对码的传递函数依赖,存在插入异常、删除异常、数据冗余度大和修改复杂的问题,需要分解该关系模式,使之成为更高范式的关系模式。
第一种分解情况
将S-L分解为下面三个关系模式:
SN(Sno)
SD(Sdept)
SO(Sloc)
分解后的关系为:

SN、SD和SO都是规范化程度很高的关系模式,但对比分解之前的关系S-L,发现分解后的关系模式会丢失许多信息,如图:

分解后的关系,无法查询95001学生所在的系或所属院系的地址了,这种分解方法是不可取的,丢失了数据之间联系的信息。
第二种分解情况
将S-L分解为以下两个关系模式:
NL(Sno, Sloc)
DL(Sdept, Sloc)
分解后的关系为:

对NL和DL关系进行自然连接的结果为:

对比分解之前的关系:
发现NLDL比原来的S-L关系多了三个元组,因此我们也无法知道原来的S-L关系种究竟有哪些元组了,从这个意义上说,此分解仍然丢失了信息。
第三种分解情况
将S-L分解为以下两个关系:
ND(Sno, Sdept)
NL(Sno, Sloc)
分解后的关系模式为:

对ND和NL关系进行自然连接的结果为:

第三种分解情况没有丢失信息,称这种分解具有”无损连结性”,但是它仍然存在一定的问题,例如95001学生由CS系转到IS系,ND关系的(95001, CS)元组和NL关系的(95001, A)元组必须同时进行修改,否则会破坏数据库的一致性,如图:

产生该问题的原因是,S-L中的函数依赖Sdept→Sloc既没有投影到关系模式ND上,也没有投影到关系模式NL上。这种分解没有保持原关系模式中的函数依赖。
第四种分解情况
将S-L分解为以下两个关系:
ND(Sno, Sdept),Sno→Sdept
NL(Sdept, Sloc),Sdept→Sloc
这种分解保持了函数依赖,称为具有“保持函数依赖性”。
再看第四种分解的情况:

对ND和DL关系进行自然连接,结果为:

这种分解不仅具有“保持函数依赖性”,还具有“无损连接性”。
在给出的例子中:
第一种情况,既不具有无损连结性,也未保持函数依赖;
第二种情况,既不具有无损连结性,也未保持函数依赖;
第三种情况,具有无损连结性,但未保持函数依赖;
第四种情况,既具有无损连结性,又保持了函数依赖。
分解的无损连结性和保持函数依赖
具有无损连接的模式分解:={
<
,
>, ... ,
<
,
>}是R<U, F>的一个分解,若对R<U, F>的任何一个关系r均有r=r在
中各关系模式上投影的自然连接成立,则称分解
具有无损连接性。简称
的无损分解。
只有具有无损连接性的分解才能保证不丢失信息,但是无损连结性不一定解决插入异常、删除异常、修改复杂、数据冗余等问题。
保持函数依赖的模式分解:={
<
,
>, ... ,
<
,
>}是R<U, F>的一个分解,若F所逻辑蕴含的函数依赖一定也为分解后所有的关系模式中的函数依赖
所蕴含,即
,则称关系模式R的这个分解是保持函数依赖的。
如果一个分解具有无损连接性,则它能够保证不丢失信息。如果一个分解保持了函数依赖,则它可以减轻或解决各种异常情况。
【分解具有无损连接性】和【分解保持函数依赖】是两个相互独立的标准。具有无损连结性的分解不一定能够保持函数依赖,保持函数依赖的分解也不一定具有无损连接性。
模式分解的相关算法
无损连接的测试算法:https://blog.csdn.net/Shishishi888/article/details/90271943
其他算法待更新
参考自:《数据库系统概论》,王珊,萨师煊编著














 4675
4675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









